微信公众号回复、接收消息中文乱码问题的分析及解决
为了方便,我们把接收时用的编码记为A、把处理时用的编码记为B、把返回时用的编码记为C
这里涉及字符串处理的时机有三个:接收的时候、处理的时候、返回的时候;在这三个地方处理字符串,稍有差池,英文还好,中文就遭殃了——乱码,一堆既不认识的也不知道该怎么使用键盘打出来的字符就出现在屏幕上,不言不语,可是就是让人很无奈(气愤),哦,问号除外!
中文乱码尝试解决方法示例
每个地方,我们考虑3种情况:默认、ISO-8859-1、UTF-8,那么一共就有27种情况(考虑更多的编码方式,情况就会更多了,这里就考虑这三种好了),这里自然无法一一道来,但是窥一斑而知全豹,就项目而言,解决问题的方法有一种即可,就学习领悟而言,得其道即可;下面先看呕心沥血得来的例子:为了方便,我们把接收时用的编码记为A、把处理时用的编码记为B、把返回时用的编码记为C;
1. A=UTF-8;B=UTF-8;C=UTF-8;
效果如下:

接收方式为UTF-8
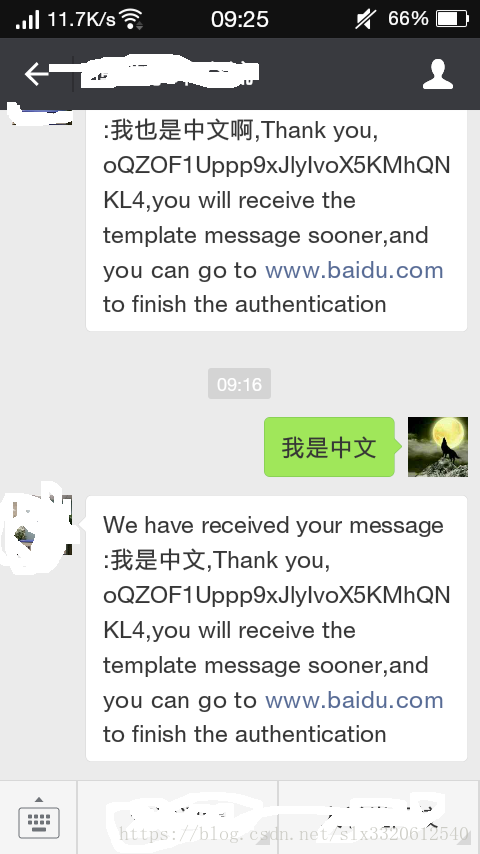
最终效果:终于不乱码了

对request和response的设置均为UTF-8
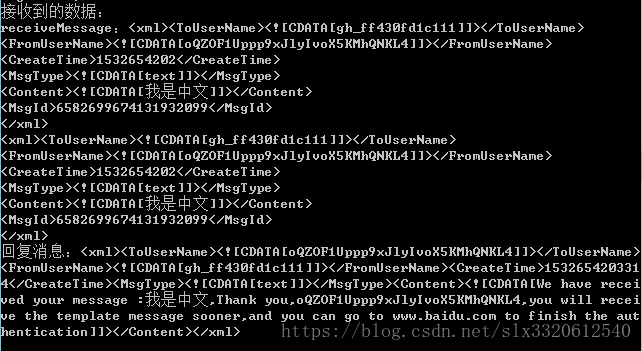
tomcat接收到的信息,也没有乱码,多好啊
这里,我们可以发现,使用UTF-8接收消息,处理消息,然后返回消息是可以解决公众号接收、回复消息中中文乱码的问题的,这也是我最后采用的方式——统一,协调,好;如果只是需要解决乱码问题,那么这就是最优解啦~
下面记录的是我的一些尝试和思考,当然也有其他的一些解~,也挺好(麻烦);
2. A=默认;B=默认;C=默认

使用平台默认的编码方式接收数据;
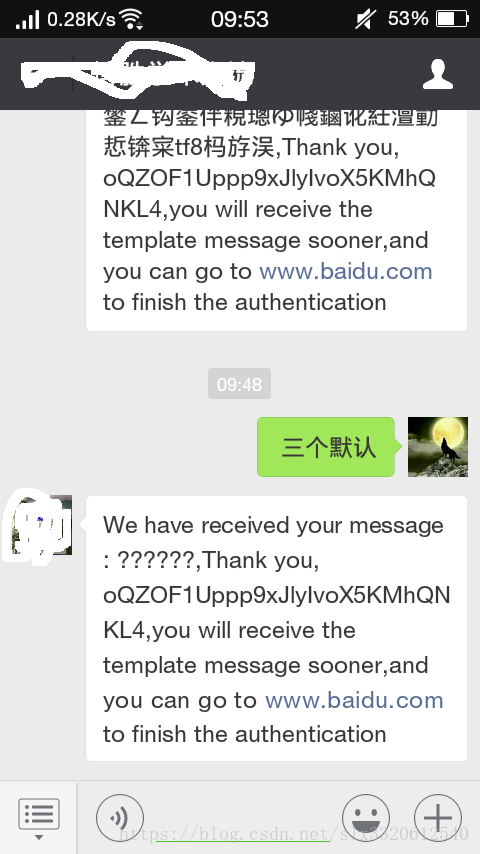
最终结果:还是熟悉的问号,还是熟悉的乱码
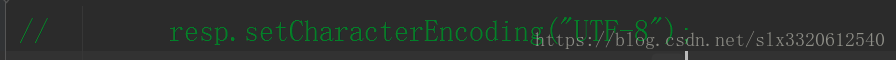
注释掉response的解码方式;
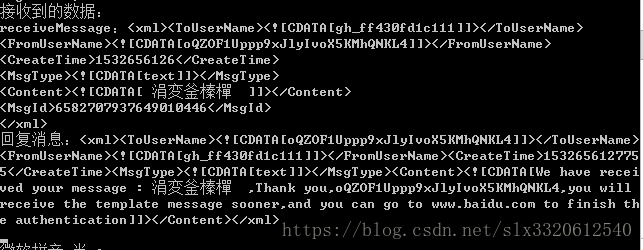
tomcat收到的消息:从头乱到尾啊,这也是最初的情景
3. A=默认;B=UTF-8;C=UTF-8
效果如下:

使用默认的编码规则接收数据,注意,是默认的哦
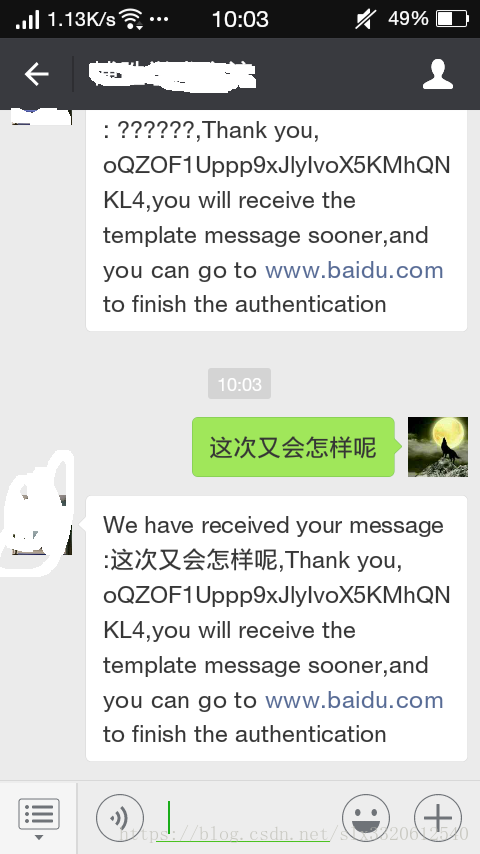
最终结果:反正不乱码了,勉强也算是一解吧;

恢复response的解码方式;
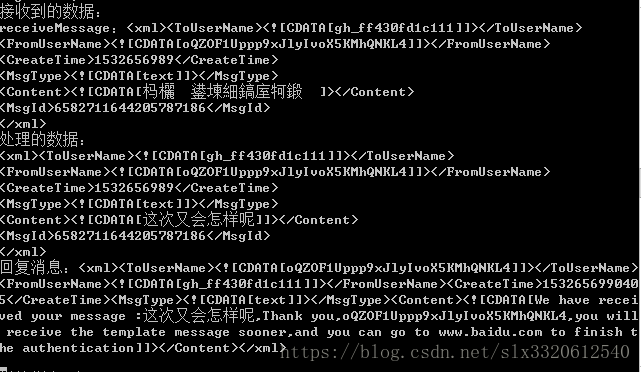
tomcat收到的消息:接收到的消息仍然是乱码的,但是进入业务处理的时候,又不乱码了,这是为什么呢?这是因为我做了一次转码呗,请看下一张图:

这里,我对使用默认编码得到的字符串进行转码,转为UTF-8,最后返回给微信客户端也是不乱码的;
4. A=默认;B=默认;C=UTF-8
效果如下:

使用平台默认解码接收到的数据
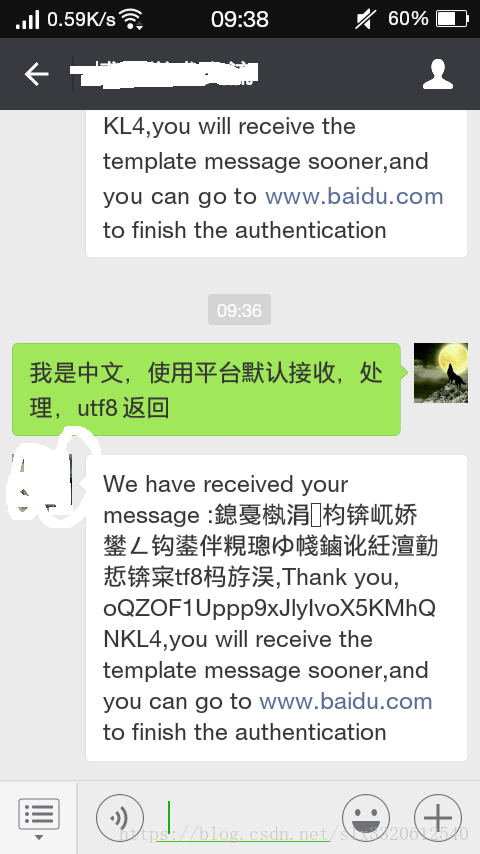
最终结果:该乱还是要乱啊;

设置了返回时UTF-8也没有用;
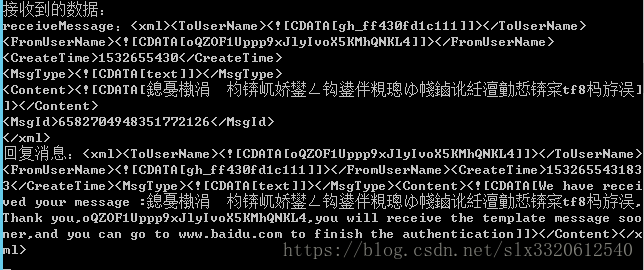
从头乱到尾!;
5. A=ISO-8859-1;B=UTF-8;C=UTF-8
效果如下

使用ISO-8859-1解码收到的数据;
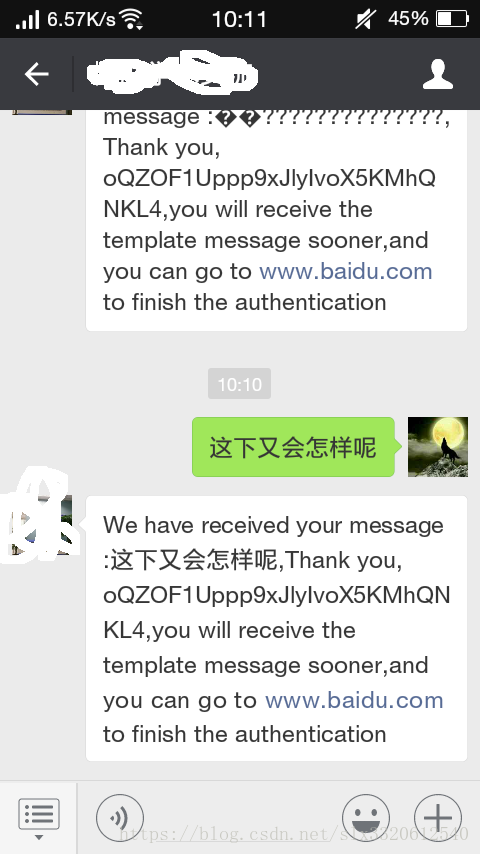
不错,反正不乱码了!

使用UTF-8返回数据
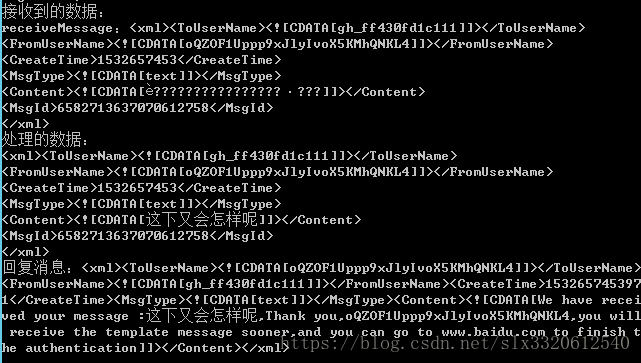
这里可以看出,接收到的ISO-8859-1数据中中文是乱码的,但是经过转换为UTF-8后,是可以解决中文乱码问题的

6. A=ISO-8859-1;B=UTF-8;C=默认
效果如下:

使用ISO-8859解码收到的数据;
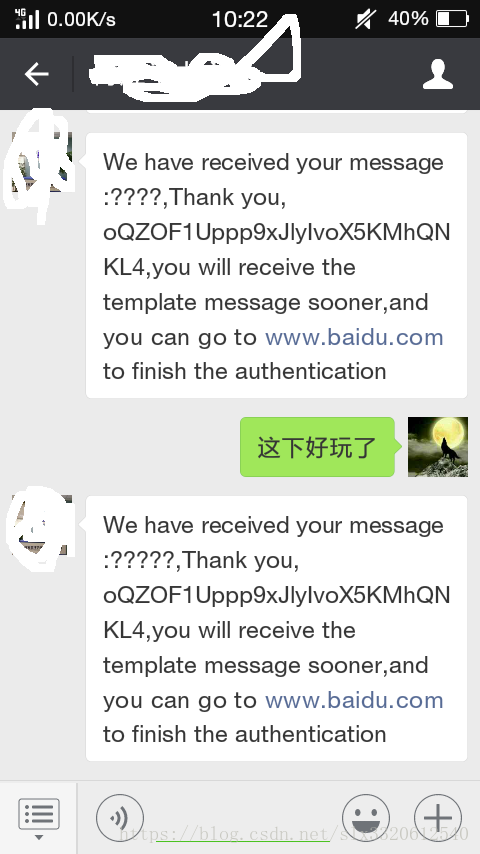
乱码可好玩了:-(
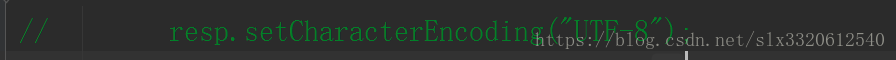

转为了UTF-8仍然改不了乱码的命运!
控制变量法,就是因为注释了这一行代码,所以乱码了!
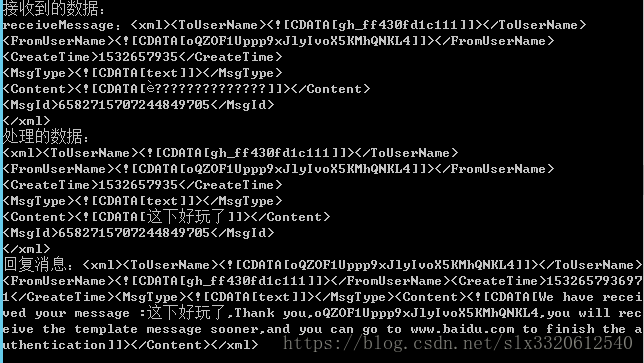
从tomcat中可以看到,信息在系统中是正常的,但是返回就乱码了
中文乱码原因思考
首先,我们需要知道的是,这些花花绿绿的文字,不管是认识的还是不认识的,在磁盘上都是一串01,这是基本的计算机知识:当代计算机使用二进制系统;
好了,知道乱码还是不乱码都是01之后,我们需要理解一个流程:
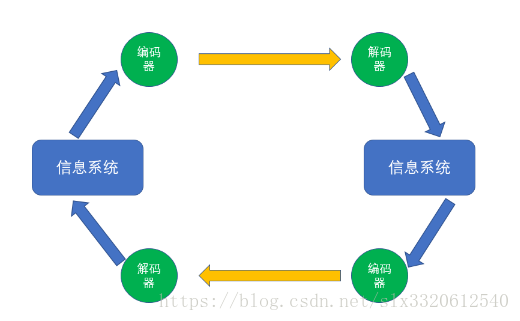
这是信息流通的过程图,不仅适用于计算机系统,还适用于人际交往哦!黄色的箭头表示信息的传输过程,一旦到达解码器,就算是信息传递到了;一旦离开编码器,信息就算发出了;
举个栗子:老板说,“好好干,面包会有的!”,大家听到后,有些人热血澎湃,已准备好奋战三天三夜的准备;有的人无动于衷;这里大家收到的消息是相同的,也就是每个人的解码器收到的信息是一致的,但是之所以产生不同效果,就是因为每个人的解码器不一样啊!(狼来了的故事,放在这里也毫无违和感的);
OK,明确上述两个知识点后,为什么会乱码是不是有一点思路了呢?恭喜恭喜!不妨看看想法是一致 :-)~
倒数第一种尝试和倒数第二种尝试对比分析
就事论事,我们看看微信公众号消息接收并反馈系统中的信息传递流程:首先,微信客户端将用户的文本消息发送到微信服务器上,微信服务器经过处理后再将信息发送到我们填写的URL上,Tomcat将收到的请求做预处理之后交付给我们的POST方法,然后我们的POST方法将信息还给Tomcat,Tomcat再将信息发送给微信服务器,微信服务器将信息还给用户。
抛开用户和微信服务器的交互,我们需要注意的流程有这些:微信服务器->Tomcat->POST->Tomcat->微信服务器;也就是说有四次消息传递(四个箭头嘛);每一次消息传递都涉及编码器和解码器哦!继续来看;
据说,微信服务器发送消息时使用ISO-8859-1编码消息,那么Tomcat使用什么解码消息呢?网上说Tomcat8以前默认是使用ISO-8859-1解码、编码消息,8及其以后默认使用UTF-8;这个我没有核实,因为在该问题中,我们的数据来源是字节流,也就是01,Tomcat应该没对此做处理,但是Tomcat会对字符流做转码处理以便传输;既然微信系统使用ISO-8859-1编码,Tomcat没做处理,那么我们在POST里使用ISO-8859-1接收数据不就好了,我们也的确这么做了,比如最后两次尝试!;可惜,ISO-8859-1编码是单字节编码,向下兼容ASCII,但是没法表示博大精深的中文字符啊(据说,茴香豆的茴字有5种写法呢);但是但是,因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,也是网络传输大多采用ISO-8859-1编码的原因;所以,虽然我们使用ISO-8859-1接收到的数据输出到控制台上看不懂(这是因为没有做编码转换,控制台使用它的解码方式也看不懂ISO-8859-1啊,因为控制台至少支持中文啊,所以应该不会使用ISO-8859-1吧)但是,数据是全的,这样就为我们做转码提供了可能。
回到正题,我们接收到这一堆的ISO-8859-1编码的字符,我们使用ISO-8859-1接收构造字符串后,再转为UTF-8,这样我们就能“看到”中文信息了;这也是最后两次尝试中我们进入业务处理系统的信息不是乱码的原因;好了,处理完,就看看POST->Tomcat吧,这里我们使用的是PrintWriter这个response的输出字符流对外返回我们的处理结果,注意,这里是字符流啊,所以Tomcat应该会将PrintWriter中的东西转码为ISO-8859-1格式的数据,然后在网络中传输;于是,设置了C=UTF-8的倒数第二个尝试最后没有乱码,因为Tomcat知道PrintWriter里的字符是用UTF-8编码的,所以它就使用UTF-8编码规则做出转换;但是如果没有设置,Tomcat就会采用默认的编码规则来做转换,如果默认的规则不是UTF-8,那么可不就乱码了!!这就解释了在倒数第一种尝试中,处理后的数据是正常的,但是微信客户端收到的是乱码;这也就解释了为什么网上针对中文乱码的解决方法有的能解决问题,有的不能解决问题,我想,但凡在博客里总结,博主都不会存心误人,问题就在于:你的默认编码不是我的默认编码啊!
根据控制变量法,我们利用倒数的两种尝试,解释了POST->Tomcat这一消息传递中设置C=UTF-8的必要性以及倒数第二种方法的合理性,接下来我们看看第二到四种尝试会给我们带来什么!
第二到第四种尝试对比分析
首先,我们均使用默认的解码方式来处理收到的字节流;第二种尝试里,系统接收到的数据是ISO编码的,强行处理,问题也不大,比如Content的内容还是被我们输入到返回数据中(乱码长的一样,说明信息的确是一样的吧),但是问题就在于,这些信息的内存表示即一堆01本来就是ISO-8859-1的,最后Tomcat又使用默认的编码规则对ISO-8859-1的01串转换为ISO-8859-1的01串来传输,当然会发生乱码,除非Tomcat默认使用ISO-8859-1对字符流的内容解码。所以第二种就乱码了;
第三种,我们使用默认的编码方式接收字符串,然后将得到的字符串使用默认的解码方式转换为UTF-8格式,并且设置了Tomcat使用UTF-8对字符流里的内容转码(就是转为ISO-8859-1进行网络传输时按照UTF-8的规则解释01串);那么当然就不会乱码了。所以第三种也是一种乱码解决方案,但实际上何不直接使用UTF-8来接收字符串呢?其实和全部使用UTF-8是一样的,只不过多了一步转换而已,当然这么做也是有目的和收获的(劳而无功,岂不可惜),也让我们看到了在构造字符串的时候,平台并没有默认使用UTF-8,否则在第三种接收到的数据中应该是没有乱码的!这里就涉及到一个大问题:通过byte[]构造字符串时,Java默认的编码方式到底是什么呢?这个问题,网上有人说是系统默认的规则,但这也太含糊了,一不明确,没有说Windows是什么,Mac上是什么,二也没展示源码分析,所以这个问题值得深入理解探究一下。以下为废话,有闲暇时间不妨看看~(选择Java其实就是因为它为软件开发者提供了很多有用的低层实现,使得我们的注意力可以集中在业务逻辑而不是底层细节上,但是了解知道其低层实现的过程本身也是一种学习提升的过程,而且知其然,知其所以然后再利用这些工具自然更加得心应手。然而可惜的是,由于时间和精力以及近期安排,无法深入探索,实在遗憾,但是我希望有一天,我能弥补该遗憾吧);
第四种,使用默认的解码方式构造字符串,在处理之前没有进行转码,最后Tomcat使用UTF-8规则做转换规则,转换为乱码也是应该的。
乱码总结
不乱码的特点
在6种尝试里,1和3和5是可以解决乱码问题的,当然解决问题的方法应该还有很多,比如不使用字符流,使用字节流来传输数据(没验证,但理论上应该可行);而且,就1,3,5的特征来看,其B和C都是UTF-8。也就是说,处理数据时使用的哪种编码,Tomcat做转码时就要明确使用该编码规则,否则就会出乱码问题,而且因为UTF-8支持中文,所以处理数据时使用的数据也是正常的,如果处理的数据本身就是不正确的,结果当然也不正确了,传输时又做了正确的转码,自然就没有乱码了。值得注意的是,在3中,我们构造字符串的时候使用的是默认编码,我们转换字符串的时候也是使用默认的编码,即怎么来的,又怎么去,这样使用UTF-8构造字符串的byte数组就一定和接收到的01串是相同的了。举个栗子,比如ISO下的5经过UTF-8转换为8,那么UTF-8下的8转为ISO的时候就是5;
乱码的特点
结合信息流通图,乱码发生的根本原因就是编码器和解码器不相容导致的。而编码器和解码器的交互发生在系统边界,即为接收到消息和发送消息时。
接收消息时,因为接收者的解码器和发送者的编码器采用不一致的规则而导致乱码的尝试有2和4。接收者以自己默认的编码规则对接收到的信息处理,结果乱码了。(我们是信息的接收者,微信系统是信息的发送者)。
发送消息时,因为发送者的编码器和接收者的解码器采用不一致的规则而导致乱码的尝试有6。这是因为Tomcat使用默认的编码规则对我们使用UTF-8处理的内容解码导致出现信息偏差,换言之,微信系统接受到信息本身就是错误的。(我们是信息的发送者,Tomcat是信息的接收者);
至此,关于乱码的问题基本上都解决了,但还有一个大大大问题值得探究,Java通过byte数组构造字符串的时候,到底是用的什么规则呢?当然,不同的平台有不同的默认的规则,甚至,即便操作系统相同,不同的机器,其设置不同,默认的规则自然也是不同的。这也就是为什么会出现在IDE里测试时不会乱码,但是部署到服务器里就产生了乱码的情况。我在IDEA里测试System.out.println(Charset.defaultCharset());其输出结果为UTF-8,而在服务器里运行时就成了GBK,这也就是前面分析中“平台没有使用UTF-8作为默认规则”的由来,因为tom猫是在服务器里运行的~至此,妈妈再也不用担心我的程序里有中文乱码啦;
附属说明
举一反三,有时候我们开发Java Web,Servlet接收数据时常常也出现中文乱码的情况,其实道理都是相通的,参考消息流通的那张图,相信很快就能找到答案,说实话,曾经很头疼Html里的中文乱码。有一篇不错的博客,Servlet 中文乱码问题及解决方案剖析,也是当初解决Html里中文乱码的学习资料,本文就微信公众号接收、回复消息为出发点,总结分享了关于乱码的若干思考,而那篇博客是从Servlet的get和post为问题的出发点,其实背后的道理都是一样的~OK,祝看到本文的伙伴们,从此编程再无中文乱码!