1、w/uptime
(1)w命令用于显示已经登陆的用户表,并显示用户正在执行的指令
-h:不打印头信息
-u:显示当前进程和cpu时忽略用户名
-s:使用短格式输出
-f:显示用户从哪里登陆
(2)uptime命令能够打印系统总共运行了所长时间和系统的平均负载,显示的信息依次为:现在时间,系统已运行时间,目前有多少用户登陆,系统在过去1分钟,5分钟,15分钟的平均负载。

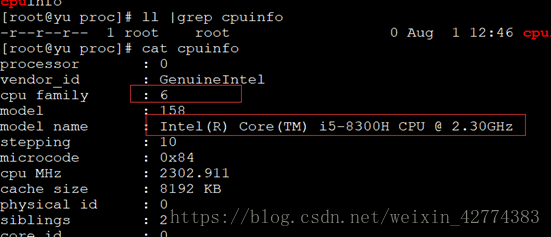
2、 /proc/cpuinfo中提供了系统软硬件信息
3 、vmstat是Linux最常见的监控工具,可以展现 给定时间间隔的服务器状态值,包括服务器cpu使用率,内存使用,虚拟内存交换情况和io读写情况。
一般vmstat有两个参数,第一个表示时间间隔,第二个表示采样次数

r表示运行队列(即有多少个真正的进程分配 到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈,也和TOP负载有关系,一般负载超过3就比较高,超过5就高,超过10就不正常,服务器处于危险的状态。
b表示阻塞的进程
swap表示虚拟内存已经使用的大小,如果大于0表示机器物理内存不足
free表示空闲的物理内存
buff用来存储即将被写入磁盘的,缓存
cache
si表示每秒读入虚拟内存的大小,如果大于零表示物理内存不够用或者内存泄露,要查找消耗内存的进程杀掉
so表示每秒虚拟内存写入磁盘的大小,如果大于零表示物理内存不够用或者内存泄露,要查找消耗内存的进程杀掉
bi表示块设备每秒收的块的数量,例如我们读文件,bo就要大于0,bi和bo一般都要接近0,不然就是io过去频繁,需要调整
in表示每秒cpu中断次数,包括时间终端
cs表示每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进行上下文切换,这个值要越小越好,太大了要考虑调低线程或进程的数目例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us表示用户cpu时间
sy表示系统cpu时间,如果太高表示系统调用时间长,例如io操作频繁
Id表示空闲cpu时间一般us+sy+id=100
wt 表示等待io cpu时间
4、top
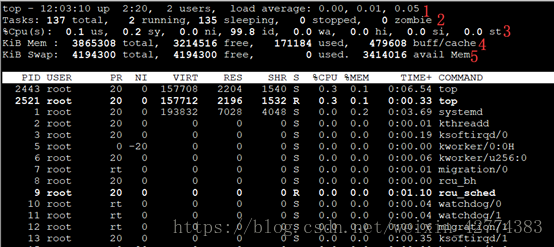
第一行:top任务队列信息(系统与运行状态及平均负载),与uptime命令结果相同。

第一段:系统当前时间。
第二段:系统运行时间,未重启时间,时间越长系统越稳定。
格式: up xx days,HH:MM
第三段:当前登陆用户数,例如1user表示只有一个用户登陆
第四段:系统负载,及任务队列的平均长度,三个数值分别为1,5,15分钟的系统平均负载。
系统平均负载:单核CPU情况下,0.00表示没有任何负载,1.00表示刚好满负荷,超过1表示超负荷,理想值是0.7.
多核CPU负载:CPU核数*理想值0.7=理想负荷,例如4核CPU负载不超过2,8表示没有出现高负载。
第二行:Tasks进程相关信息
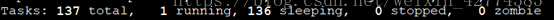
第一段:进程总数,表示总共运行了137个进程。
第二段:正在运行的进程数。
第三段:睡眠的进程数。
第四段:停止的进程数。
第五段:僵尸进程数,僵尸进程就是已经结束的进程但是没有从进程表中删除。
第三行:CPU相关信息,如果是多核CPU,按数字1可显示各核CPU行,数字1可以来回切换

第一段:us(user)用户空间占用CPU百分比
第二段:sy(system)内核空间占用CPU百分比
第三段:ni(niced)用户进程空间内改变过优先级的进程占用CPU百分比
第四段:id空闲CPU百分比
第五段:wa(io wait)等待输入输出CPU时间百分比
第六段:hiCPU服务于硬件中断所耗费的时间总额
第七段:siCPU服务软中断所耗费的时间总额
第八段:st Steal time虚拟机被hypervisor偷去的CPU时间
第四行:Mem内存相关信息
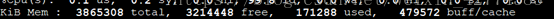
第一段:物理内存总量
第二段:使用的物理内存总量
第三段:空闲内存总量
第四段:用作内核缓存的内存量
第五行:Swap交换分区相关信息

第一段:交换分区总量
第二段:使用的交换区总量
第三段:空闲交换区总量
第四段:缓冲的交换区总量
第六行各进程(任务)状态监控

PID:进程id,进程的唯一标识符
USER:进程所有者的实际用户名
PR:进程调度优先级,这些字段一些值是rt,意味着这些进程运行在实时态
NI:进程的nice(优先级),越小的值意味着越高的优先级,负值表示高优先级,正值表示低优先级
VIRT:进程使用的虚拟内存,进程使用的虚拟内存总量,单位KB,
VIRT=SWAP+RES
RES:驻留内存大小,驻留内存是任务使用的非交换物理内存大小,进程使用的,未被使用的物理内存大小,单位KB,RES=CODE+DATA
SHR:SHR是进程使用的共享内存,单位KB
S:这个是进程的状态有以下不同的值:
D—不可中断的睡眠态
R—可运行态
S—睡眠态
T—被跟踪或已停止
Z—僵尸态
%CPU:自从上一次更新到现在任务所使用的CPU时间百分比
%MEM:进程使用的可用物理内存百分比
TIME +:任务启动后到现在所使用的全部CPU时间,精确到百分之一秒
COMMAND:运行进程所使用的命令
| top命令选项 |
|
| -b |
以批处理模式操作 |
| -c |
显示完整的命令 |
| -d |
屏幕刷新间隔时间 |
| -I |
忽略失效过程 |
| -s |
保密模式 |
| -S |
累计模式 |
| -i<时间> |
设置间隔时间 |
| -u<用户名> |
指定用户名 |
| -p<进程号> |
指定进程 |
| -n<次数> |
循环显示次数 |
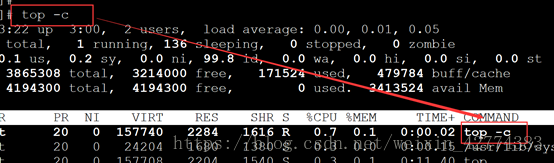
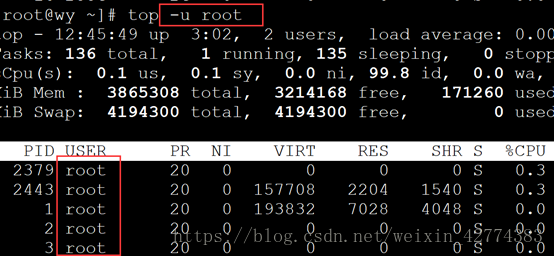
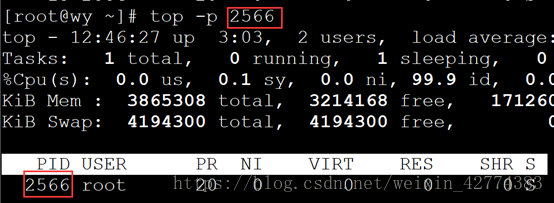
| top命令交互 |
|
| 1 |
显示CPU详细信息,每核显示一行 |
| d/s |
修改刷新频率,单位为秒 |
| h |
可显示帮助界面 |
| n |
指定进程列表显示行数,默认为满屏行数 |
| q |
退出top |
| l |
隐藏/显示第一行负载信息 |
| t |
隐藏/显示第2~3行cpu信息 |
| m |
隐藏/显示第4~5行内存信息 |
| M |
根据驻留内存大小进行排序 |
| P |
根据CPU使用百分比大小排序 |
| T |
根据累计时间排序 |






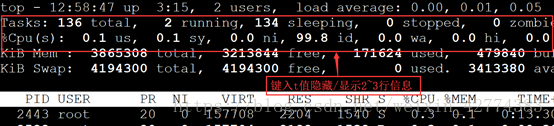

5、sar命令可以看文件的读写情况,系统调用使用情况,磁盘io,cpu效率,内存使用情况,进程活动及IP有关活动

CPU:all表示统计信息为所有CPU的平均值
%user:显示用户级别(application)运行占用CPU时间百分比
%nice:显示再用户级别,用于nice操作,所占用CPU时间百分比
%system:在核心级别(kernel)运行CPU总时间的百分比
%iowait:显示用于等待io操作占用CPU总时间的百分比
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比
%idle:显示CPU空闲时间占用CPU总时间的百分比
注:
若iowait的值过高,表示硬盘存在io瓶颈
若%idle值过高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
若%idle值持续低于1,表示系统的CPU处理能力较低,表明系统中最需要解决的资源是CPU
(1)sar -q输出进程队列长度和平均负载统计信息

(2)sar -b 显示io和传送速率统计信息

(3)sar -f 从文件中读取数据信息
6、nload命令用于查看Linux网络流量状况,实时输出。
nload下载需要扩展源epel
yum install -y epel-release
yum install -y nload

7、iostat,Linux系统中的iostat是I/O statistics(输入输出统计的缩写),iostat工具将对系统的磁盘活动进行监控,特点是汇报磁盘活动情况,同时也会汇报出CPU的使用情况,同vmstat一样,缺点是不能对某个进程进行深入分析。
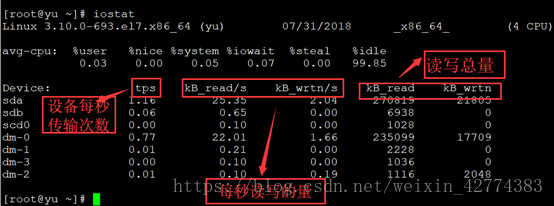
8、free,命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区

9、cache与buffer的区别
cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小的但速度很快的存储器,因为CPU速度远远高于主存的速度,CPU从贮存中读取数据需要等待很长的时间,而cache保存着CPU刚用过的数据或循环使用的部分数据,这时从cache中读取数据会更快,减少了CPU等待的时间,提高了系统性能,cache并不是缓存文件的,而是缓存块的(块是io读写的最小单元),cache一般会用在io请求上,如果多个进程要访问某个文件,可以把文件读入cache中,这样下一个进程获取CPU就可以直接读取,提高系统性能。
buffer:缓冲区,用于存储速度不同步的设备或优先级不通的设备之间传输数据,通过buffer可以减少进程通信需要的等待时间,当存储速度快和存储速度慢的设备进行通信时,存储慢的设备先将数据放入buffer中,达到一定程度存储快的设备再从buffer中读取,在此期间CPU可以做别的事情。buffer一般用在写入磁盘的,例如某个进程要求多个字段被读入,这些字段就会先写入buffer中再同一读入磁盘
cache解决的是时间问题,buffer解决的是空间问题。
10、ps,是显示瞬间进程的状态,并不动态连续,这是与TOP的区别。
-A :所有的进程均显示出来
-a :显示现行终端下所有进程包括其他用户进程
-u :以用户为主的进程状态
-x :与其他参数混合用,可列出完整信息
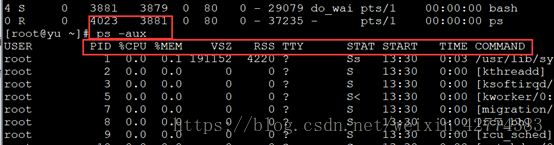
USER:该进程属于哪个使用者账号
PID:该进程的ID号
%CPU:该进程使用CPU资源百分比
%MEM:该进程所占用物理内存百分比
VSZ:该进程使用掉的虚拟内存量KB
RSS:该进程占用的固定内存量KB
TTY:该进程是在哪个终端机上面运作,若与终端机无关则显示?,tty1-tty6是本机上面的登陆程序,ots/0等表示网络连接进主机的程序。
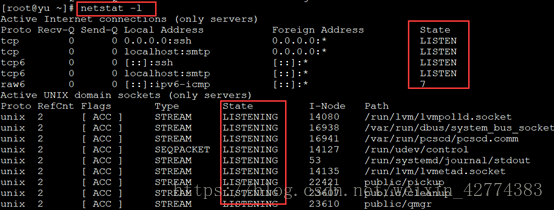
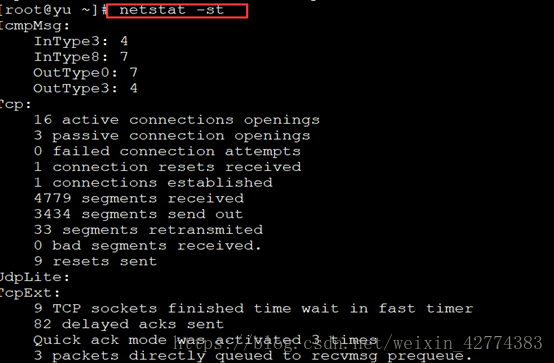
11、netstat命令用来打印Linux中网络系统的状态信息,可以知道整个Linux的网络情况。
| -a |
列出所有端口 |
| -at |
列出所有tcp端口 |
| -au |
列出所有udp端口 |
| -l |
只显示监听端口 |
| -lt/lu/lx |
列出监听tcp/udp/unix端口 |
| -st/su |
显示tcp/udp端口统计信息 |
| -pt |
列出pid和进程名称 |
| -an |grep ‘:22’ |
找出运行在指定端口的进程 |


12、tcpdump,采用命令行方式对接口的数据进行筛选抓取,特性表现在灵活的表达式上
(1)安装命令:yum instasll -y tcpdump
tcpdump -nn -i enss33
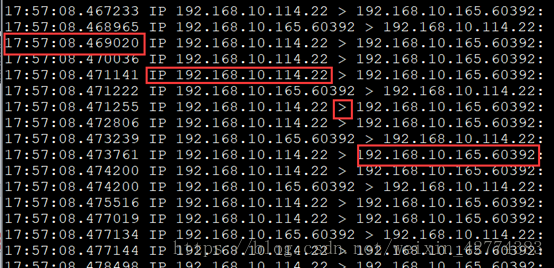
从左向右依次是:系统时间,IP源地址,指向符,目标ip地址
tcpdump -nn port 22 抓指定端口的包
tcpdump -nn -i ens33 抓来自网卡ens33的包
tcpdump -nn -i ens33 not port 22 and host 192.168.10.165抓取来自指定IP地址不是端口22的包
tcpdump -nn -c 100 -w 1.txt 抓取指定个数的包并写入文件中,文件不可读
13、Linux系统日志
(1)/var/log/message:为操作系统层面的文件,存放开机发生错误的记录,是核心日志文件,包含了系统启动时的引导信息,以及系统运行时的其他状态信息,io错误,网络错误和其他系统错误,是做故障诊断时要首先要查看的文件。
(2)/etc/logrotate.conf:日志切割文件
(3)demsg命令用来显示开机信息,显示内核缓冲区的内容
/var/log/dmesg核心启动日志,显示Linux内核环形缓冲区信息,可以显示系统架构,cpu,挂载的硬件,RAM等多个运行级别的大量系统信息。
(4)last 命令可以查看之前有什么用户什么时候什么地点登陆过,对应的文件为/vat/log/wtmp
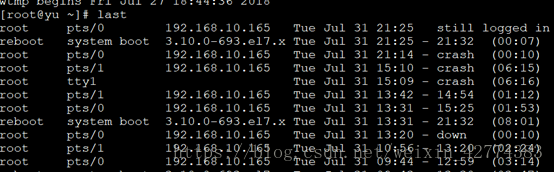
(5)lastb命令查看登陆失败的用户,对应的文件/var/log/btmp
