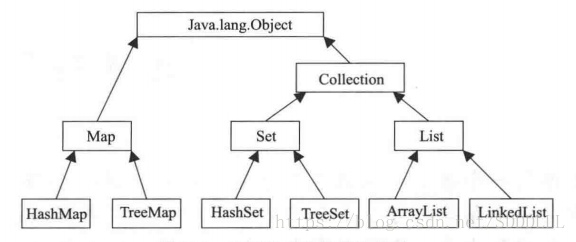
java.util包中提供了一些集合类,这些集合类被称为容器,存储任意数量的具有共同属性的对象。保存的数据可以动态增长。常见的集合类有List、Set、Map集合。他们的继承关系如下:(此图不完整)
本博客的目录是:
目录
1、Collection接口概述
先看一下Collection接口的继承树:
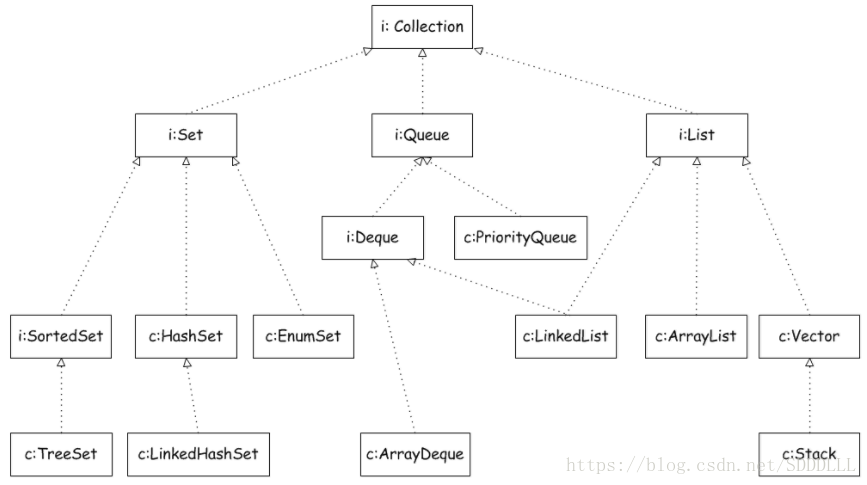
从上图可以看到:Collection主要是有三个子接口:Set、Queue、List。那Collection里面有什么他们三个共同的基本操作呢?
- add( Object o ):增加元素
- addAll ( Collection c ) :添加一个集合
- clear():
- contains( Object o ):是否包含指定元素
- containsAll( Collection c ):是否包含集合C中的所有元素
- iterator() :返回Iterator对象,用于遍历集合中的元素。
- remove(Object o):移除元素
- retainAll( Collection c ):相当于求与C的交集
- size() :返回元素的个数
- toArray() :把集合转换为一个数组
1.1 遍历Collection
在遍历时使用Iterator来遍历。举例说明:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Test5 {
public static void main(String[] args) {
Collection<String> collection=new ArrayList<>();
collection.add("张三");
collection.add("李四");
collection.add("王五");
collection.add("赵六");
//第一种方式:使用for-each
for(String name:collection) {
System.out.println(name);
}
System.out.println("==============");
//第二种方式:使用Iterator迭代器
Iterator<String> it=collection.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
注意:这里面没get( int position )
2、List集合
2.1 ArrayList
一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.不同步(就是线程不安全
ArrayList是一个动态数组,也是我们最常用的集合。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。add 操作以分摊的固定时间运行,也就是说,添加 n 个元素需要 O(n) 时间(由于要考虑到扩容,所以这不只是添加元素会带来分摊固定时间开销那样简单)。
ArrayList的基本操作
import java.util.ArrayList;
import java.util.List;
public class Test6 {
public static void main(String[] args) {
List<String> list =new ArrayList<>();
//添加元素
list.add("参数一");
list.add("参数二");
list.add("参数三");
//删除元素:0表示删除的位置
list.remove(0);
//更改元素
list.set(1, "fdd");
//遍历元素
for(int i=0;i<list.size();i++) {
System.out.println(list.get(i));
}
}
}
2.2 LinkList
linkList其实也就是我们数据结构中的链表。其特性和使用场景和数据结构中的链表一样。
LinkList的基本操作
add操作
boolean add(E e):在链表后添加一个元素,如果成功,返回true,否则返回false;
void addFirst(E e):在链表头部插入一个元素;
addLast(E e):在链表尾部添加一个元素;
void add(int index, E element):在指定位置插入一个元素
remove
E remove();移除链表中第一个元素;
boolean remove(Object o):移除链表中指定的元素;
E remove(int index):移除链表中指定位置的元素;
E removeFirst():移除链表中第一个元素,与remove类似;
E removeLast():移除链表中最后一个元素;
boolean removeFirstOccurrence(Object o):移除链表中第一次出现所在位置的元素;
boolean removeLastOccurrence(Object o):移除链表中最后一次出现所在位置的元素;
get
E get(int index):按照下边获取元素;
E getFirst():获取第一个元素;
E getLast():获取第二个元素;
push、pop、poll
void push(E e):与addFirst一样,实际上它就是addFirst;
E pop():与removeFirst一样,实际上它就是removeFirst;
E poll():查询并移除第一个元素;
peek
E peek():获取第一个元素,但是不移除;
E peekFirst():获取第一个元素,但是不移除;
E peekLast():获取最后一个元素,但是不移除;
具体的代码就不粘贴进来了。自己动手就能实现。
3、set集合
set集合中的对象不按特定的方式排序,只是简单地把对象加入到集合,但是Set集合中不能包含重复的对象。
3.1 HashSet
HashSet继承自AbstractSet,实现了Set接口。内部使用HashMap来存储数据,数据存储在HashMap的key中,value都是同一个默认值。
3.2 TreeSet
不仅实现了Set接口,还实现了java.util.SortedSet接口,因此TreeSet类实现的Set集合在遍历集合时,按照自然顺序递增排序,也可以按照指定比较器递增排序。
TreeSet的基本操作
- first() :返回Set中的第一个元素
- last():返回Set中的最后一个元素
- comparator():返回对此Set中的元素进行排序的比较器。如果此Set采用自然顺序,返回null
- headSet( E toElement ):返回一个新的Set集合
- subSet( E formElement,E toElement ):返回一个新集合,是form(包含)到to(不包含)之间的所有对象
- tailSet( E fromElement )返回一个新集合,新集合包含fromElement(包含)之后的所有对象
代码演示基本操作:
package com.day.bean;
import java.util.Iterator;
import java.util.TreeSet;
public class Student implements Comparable<Object>{
String name;
long id;
public Student(String name,long id) {
this.id=id;
this.name=name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
@Override
public int compareTo(Object o) {
//o对象向下转型
Student stu=(Student) o;
int result=id>stu.id?1:(id==stu.id?0:-1);
return result;
}
public static void main(String[] args) {
Student stu1=new Student("张三", 100011);
Student stu2=new Student("李四", 100021) ;
Student stu3=new Student("张三", 100051);
Student stu4=new Student("李四", 100012) ;
TreeSet<Student> tree=new TreeSet<>();
tree.add(stu1);
tree.add(stu2);
tree.add(stu3);
tree.add(stu4);
//生成一个迭代器迭代集合
Iterator<Student> it=tree.iterator();
//遍历集合
System.out.println("加入集合之后集合中的对象是(之前没有按照id的顺序添加):");
while(it.hasNext()) {
Student stu=it.next();
System.out.println("学生姓名:"+stu.getName()+" 学生id:"+stu.getId());
}
//截取stu2前面部分的集合
System.out.println("截取stu2前面部分的集合");
it=tree.headSet(stu2).iterator();
while(it.hasNext()) {
Student stu=it.next();
System.out.println("学生姓名:"+stu.getName()+" 学生id:"+stu.getId());
}
//截取排在stu2和stu3之间的集合
System.out.println("截取排在stu2和stu3之间的集合");
it=tree.subSet(stu2, stu3).iterator();
while(it.hasNext()) {
Student stu=it.next();
System.out.println("学生姓名:"+stu.getName()+" 学生id:"+stu.getId());
}
}//main方法结束
}
控制台输出结果是:

4、map集合
4.1 HashMap
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
HashMap的基本操作
- void clear()
- boolean containsKey(Object key)
- boolean containsValue(Object value)
- Set<Entry<K, V>> entrySet()
- V get(Object key)
- boolean isEmpty()
- Set<K> keySet()
- V put(K key, V value)
- void putAll(Map<? extends K, ? extends V> map)
- V remove(Object key)
- int size()
代码演示
package com.day.bean;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Student {
String mkey;
String mValue;
public Student(String mkey,String mValue) {
this.mValue=mValue;
this.mkey=mkey;
}
public String getMkey() {
return mkey;
}
public void setMkey(String mkey) {
this.mkey = mkey;
}
public String getmValue() {
return mValue;
}
public void setmValue(String mValue) {
this.mValue = mValue;
}
public static void main(String[] args) {
//新建一个map
Map<String, String> map=new HashMap<>();
//添加元素
map.put("学生一", "张三");
map.put("学生二", "李四");
map.put("学生三", "王五");
map.put("学生四", "赵六");
map.remove("学生二");
boolean s=map.isEmpty();
System.out.println("map是否为空"+s);
Set<String> keyset=map.keySet();
Iterator<String> it=keyset.iterator();
System.out.println("HashMap遍历所有的Map集合:无序");
while(it.hasNext()) {
System.out.println("所有的键名:"+it.next());
}
}//main方法结束
}
控制台结果:

4.2 TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
package com.day.bean;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Student {
String mkey;
String mValue;
public Student(String mkey,String mValue) {
this.mValue=mValue;
this.mkey=mkey;
}
public String getMkey() {
return mkey;
}
public void setMkey(String mkey) {
this.mkey = mkey;
}
public String getmValue() {
return mValue;
}
public void setmValue(String mValue) {
this.mValue = mValue;
}
public static void main(String[] args) {
//新建一个map
Map<String, String> map=new HashMap<>();
//添加元素
map.put("1", "张三");
map.put("3", "李四");
map.put("2", "王五");
map.put("4", "赵六");
TreeMap<String,String> treemap=new TreeMap<>();
treemap.putAll(map);
Iterator<String> it=treemap.keySet().iterator();
System.out.println("HashMap遍历所有的Map集合:无序");
while(it.hasNext()) {
System.out.println("所有的键名:"+it.next());
}
}//main方法结束
}
控制台结果:
