斗鱼弹幕数据分析
项目介绍
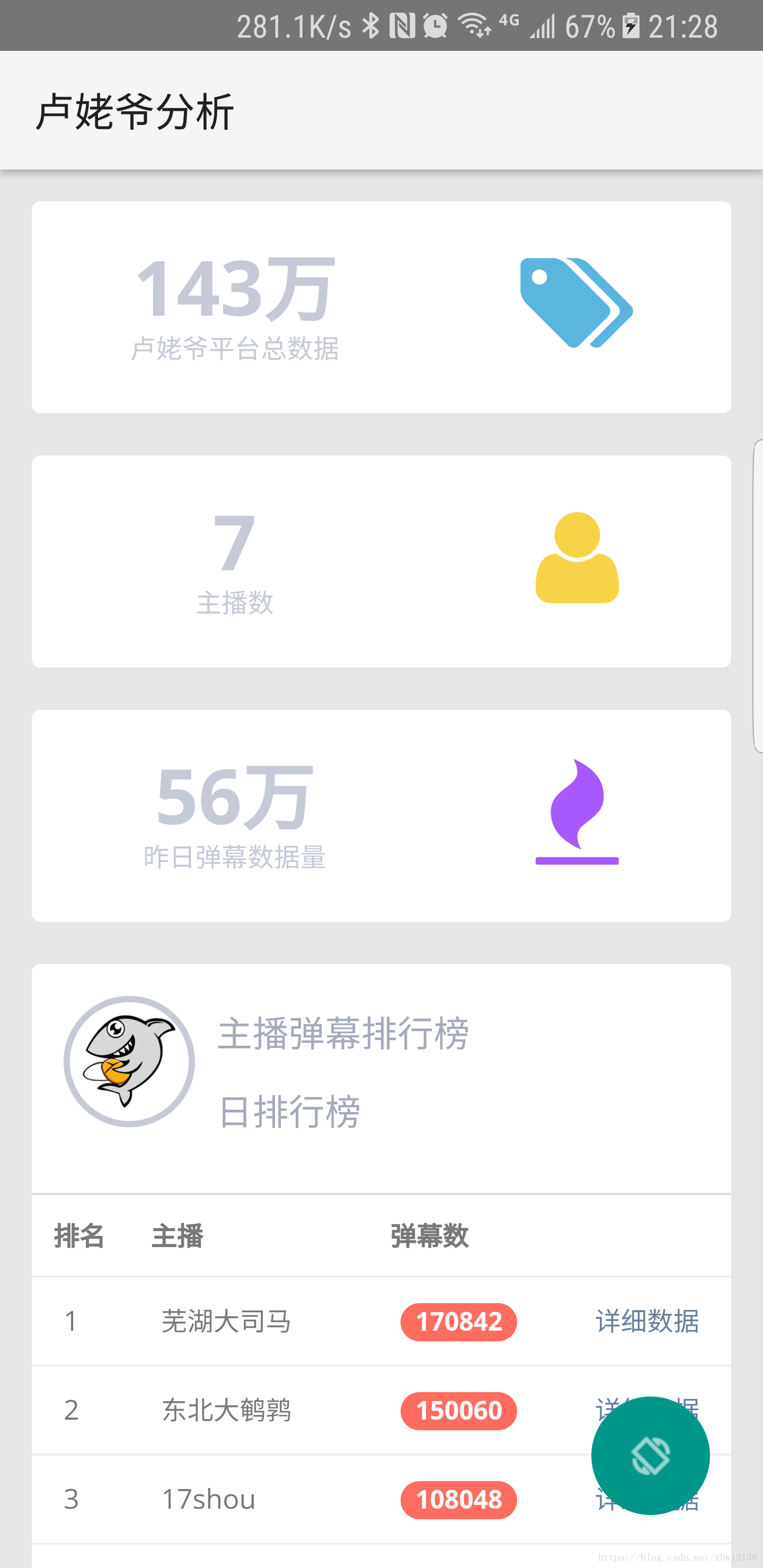
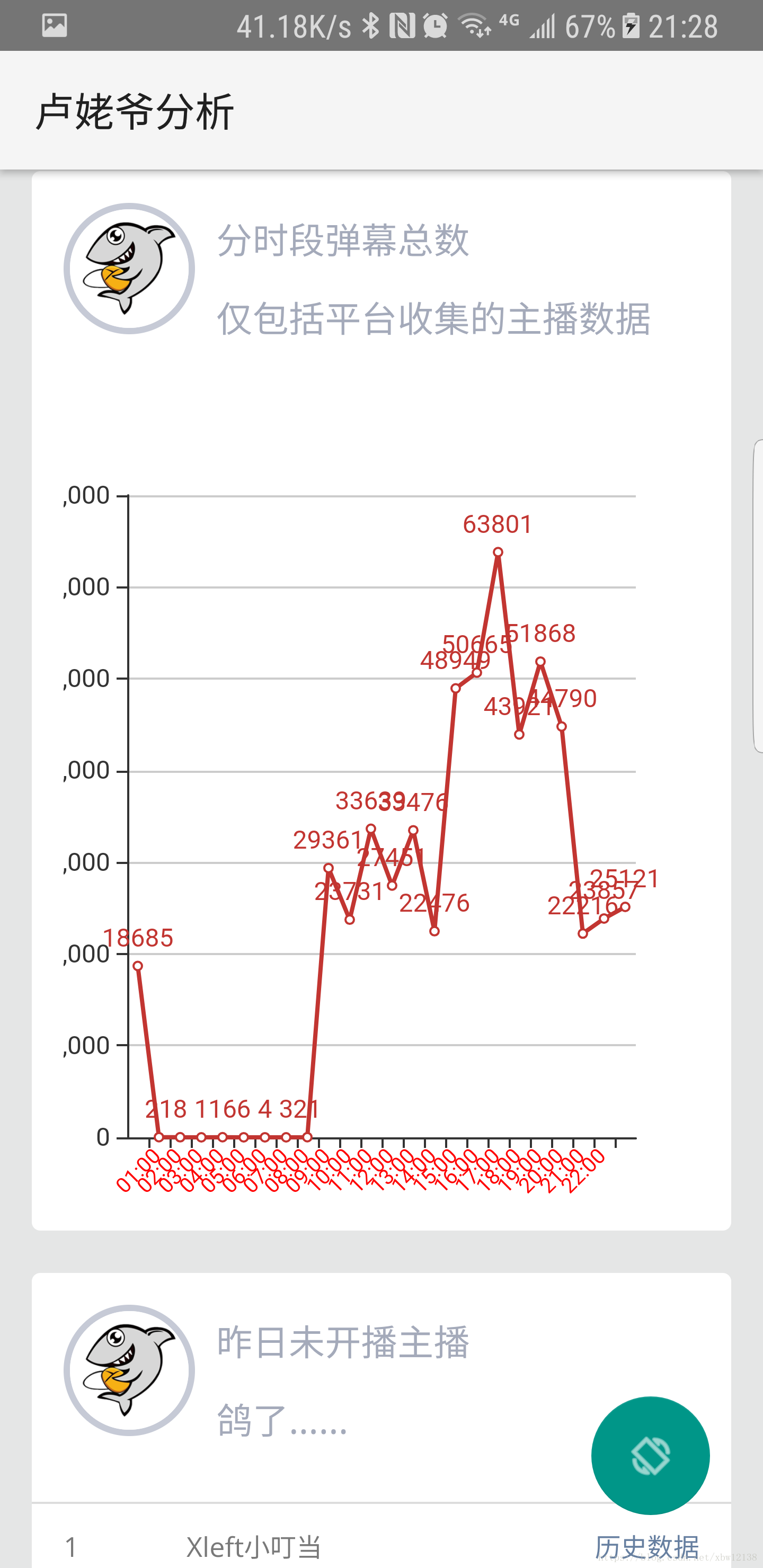
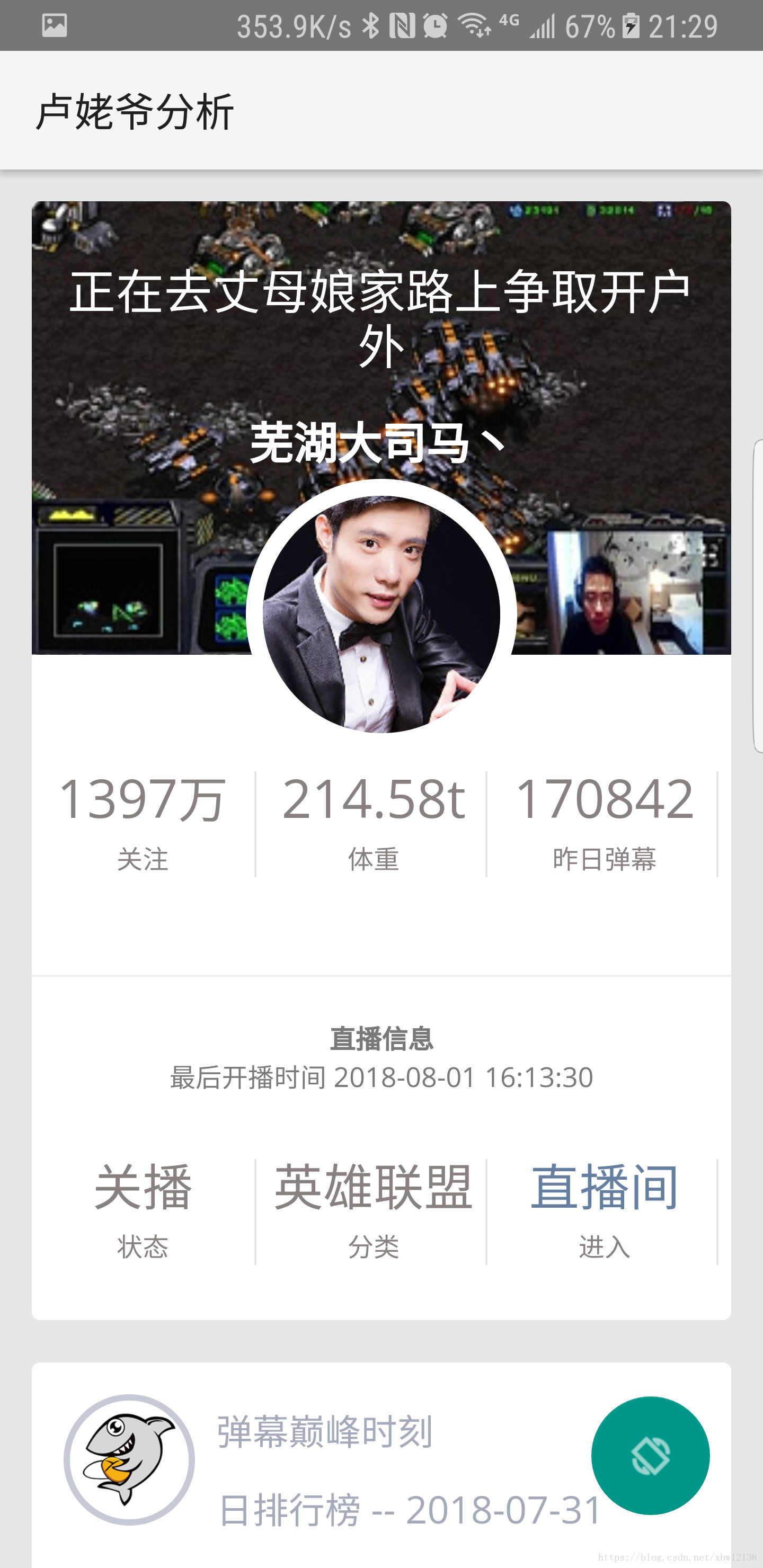
通过分析直播弹幕数据,对主播进一步了解。
数据分析结果见image文件夹

目录介绍
run.py 多线程同步收集斗鱼直播弹幕,采用python的弹幕库
pip install danmu
run.py保持运行,每时每刻都在收集弹幕数据
config.py 配置文件
analyze.py 数据分析脚本,
data 按日期存放每天的数据,再按主播房间ID存放每个主播的数据
platform 存放最终分析结果,供前端调用的Json文本数据
res 资源文件,词云生成图片的mask跟font
result 数据初步分析结果,包括 imgwc 词云图片数据
platform 每个主播每天的数据量,用总数据量给文件命名
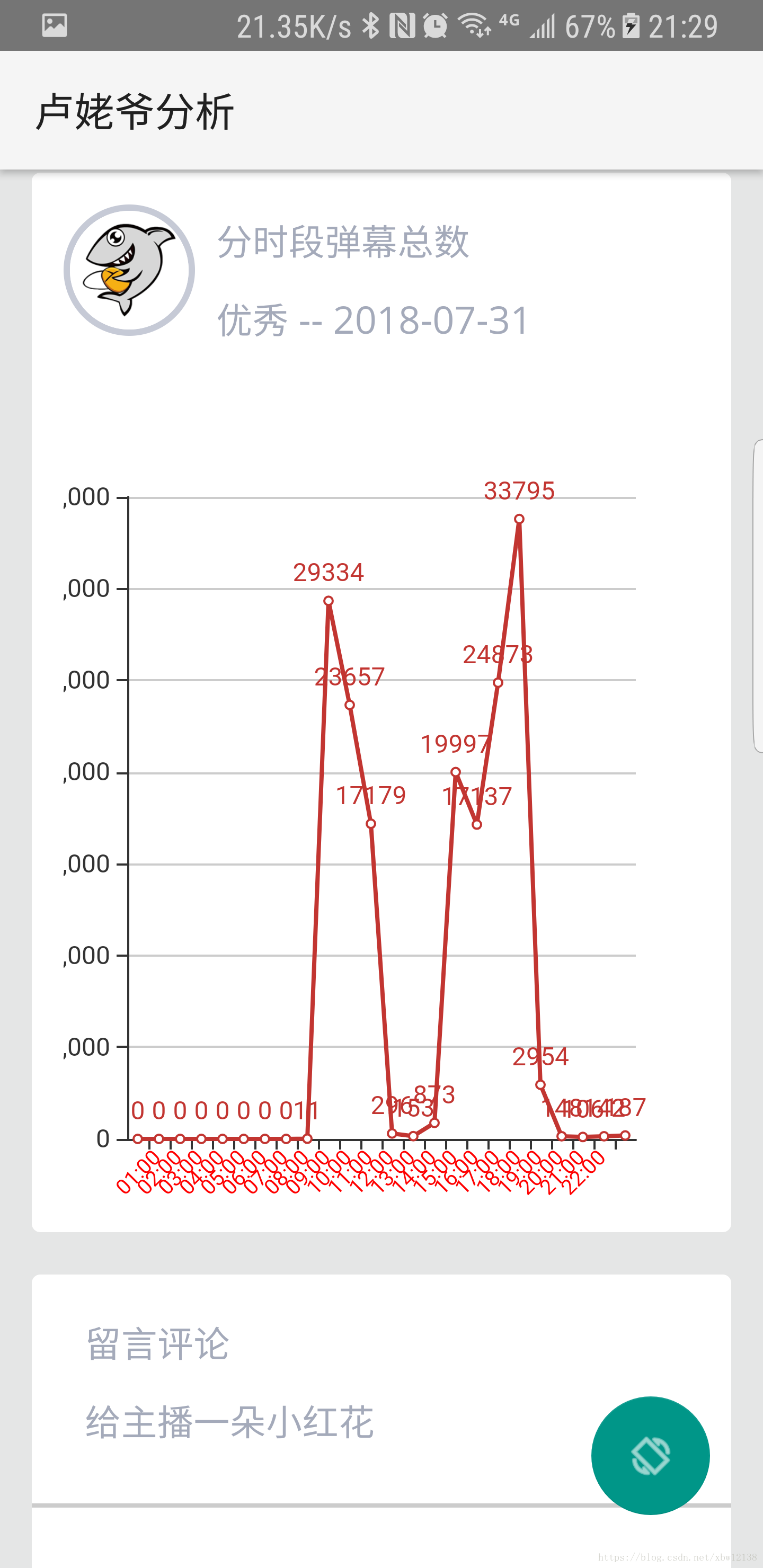
time 每个时段的弹幕数据量
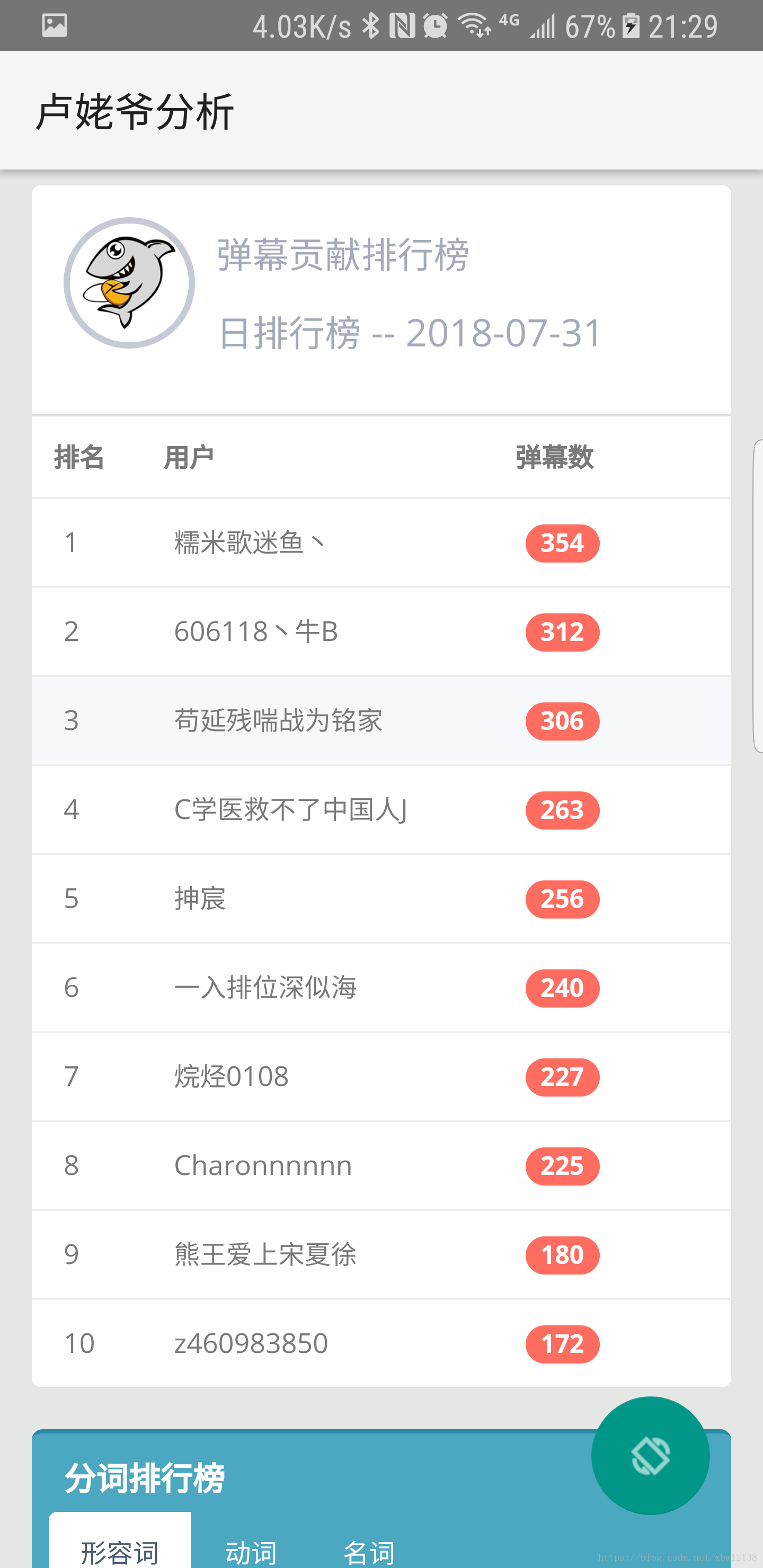
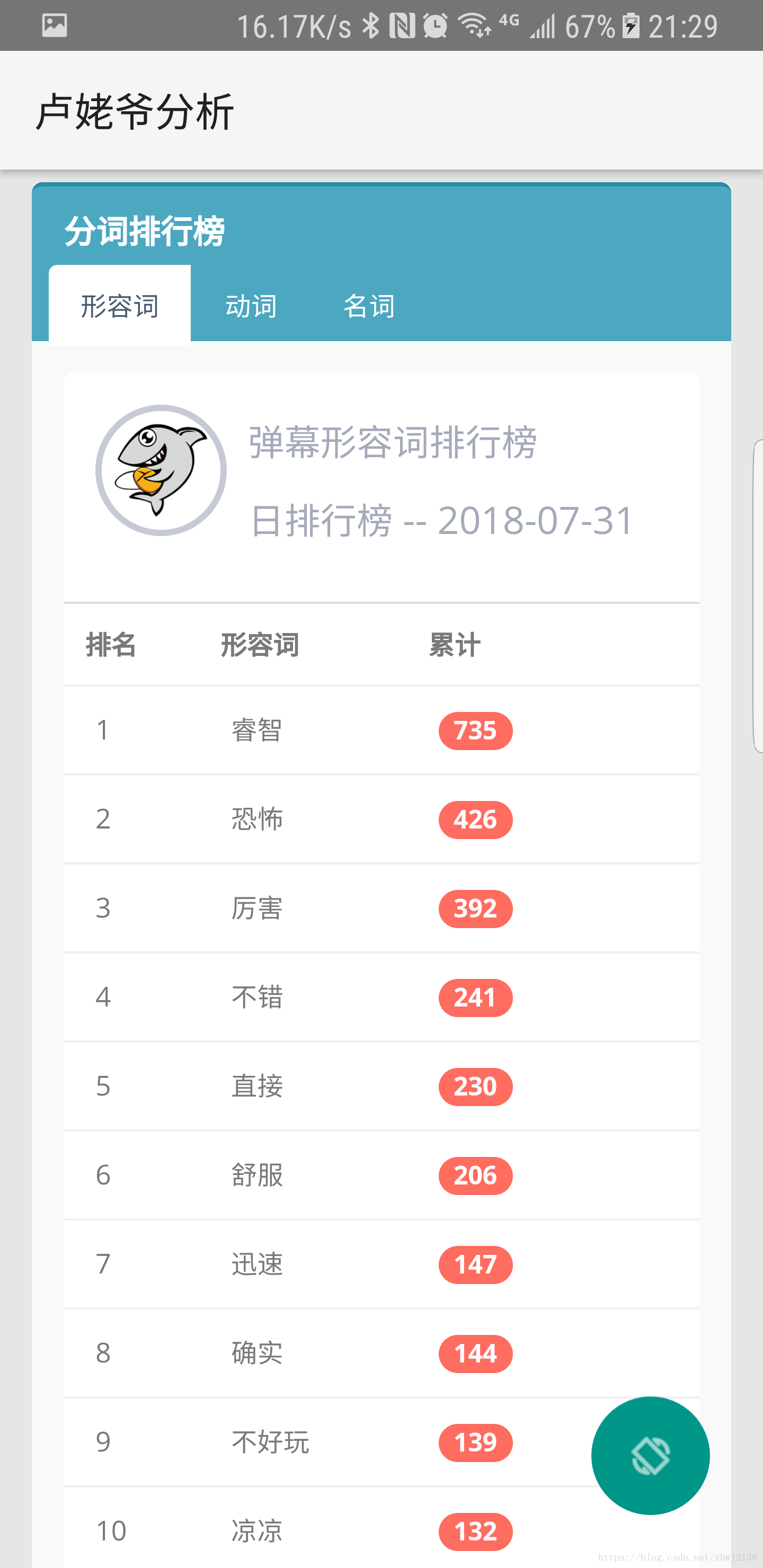
topuser 用户发送弹幕排名
topwc 词性分析排名
shell 自动化脚本,利用crontab自动执行
- start.sh 每天凌晨重新启动一下 run.py程序,因为有可能加进了新主播
- analyze.sh 每天凌晨分析前一天的数据
- delete.sh 词云需要足够的数据量,所以需要删除昨天数据量不够的主播
zhubo.txt 增添可分析的主播ID与名字
使用说明
前端说明
环境 PHP ,Laravel
把lulaoye拷贝到根目录下,cd lulaoye
cp .env.example .env
vim .env
php artisan key:generate
php artisan config:cache
chmod -R 777 storage
此时可以打开前端网页了,不过没有数据
后端说明
pip install danmu
pip install wordcloud
pip install Pillow
pip install jieba
先要保证zhubo.txt有数据,数据我们可以在前端添加 http://ip/lulaoye/addlive
手动添加一定要注意格式,
@|2461752@|@|47号Gamer@|
python run.py开始收集数据,或者利用shell脚本
cd shell
./start.sh
我们项目一定要放在root目录里,代码写的比较挫,server改成Douyu,……尴尬
我们只能分析昨天的数据,想要分析今天的自己改代码吧。。。。。。。
所以得保证昨天有数据才能够分析。
每天凌晨进行数据分析。
python analyze.py 或者
cd shell
./analyze.sh
数据分析
analyze.py
# -*- coding: utf-8 -*-
import jieba
from wordcloud import WordCloud
from scipy.misc import imread
import datetime
import time
import os
import re
import sys
import operator
import json
import config
import io
from PIL import Image
import requests
from collections import Counter
import jieba.posseg as psg
reload(sys)
sys.setdefaultencoding("utf-8")
def getYesterday():
today = datetime.date.today()
oneday = datetime.timedelta(days=1)
yesterday = today-oneday
return yesterday.strftime('%Y%m%d')
def writeTop(path_file_name, str_data):
with open(path_file_name, "a") as f:
f.write(str_data)
print "write finish %s"%(path_file_name)
def getTopWC(text, cixing, roomid):
#jieba.enable_parallel(5)
words = [(x.word, x.flag) for x in psg.cut(
text.replace(' ', '')) if x.flag.startswith(cixing)]
#jieba.disable_parallel()
words = [x[0] for x in words if len(x[0]) >= 2]
tops = Counter(words).most_common(30)
path_result = 'result/%s' % (getYesterday())
if not os.path.exists(path_result):
os.makedirs(path_result)
print "create dir %s"%(path_result)
path_topwc = path_result+'/topwc'
if not os.path.exists(path_topwc):
os.makedirs(path_topwc)
print "create dir %s"%(path_topwc)
path_file_name = path_topwc+'/%s_%s.txt' % (roomid, cixing)
result_json = {}
result_list = []
for top in tops:
result_list.append({"wc": top[0], "num": top[1]})
result_json["data"] = result_list
res_json = json.dumps(result_json)
writeTop(path_file_name, '%s' % (res_json))
def getWordCloud(text, roomid):
cut_text = " ".join(jieba.cut(text.replace(' ', '')))
#color_mask = imread('res/mask/%s/mask.png' % (roomid))
color_mask = imread(config.CIYUNMASK)
font = 'res/font/simfang.ttf'
wordcloud = WordCloud(
mask=color_mask,
font_path=font,
background_color='white',
scale=5,
max_words=2000,
max_font_size=40
).generate(cut_text)
path_result = 'result/%s' % (getYesterday())
if not os.path.exists(path_result):
os.makedirs(path_result)
print "create dir %s"%(path_result)
path_imgwc = path_result+'/imgwc'
if not os.path.exists(path_imgwc):
os.makedirs(path_imgwc)
print "create dir %s"%(path_imgwc)
wordcloud.to_file(path_imgwc+'/wc_%s.png' % (roomid))
print "save image %s/wc_%s.png"%(path_imgwc,roomid)
def getTimeAnalyze(res_json, roomid, index):
path_result = 'result/%s' % (getYesterday())
if not os.path.exists(path_result):
os.makedirs(path_result)
print "create dir %s"%(path_result)
path_time = path_result+'/time'
if not os.path.exists(path_time):
os.makedirs(path_time)
print "create dir %s"%(path_time)
unit = ''
if index == 3:
unit = 'h'
elif index == 6:
unit = 'm'
elif index == 9:
unit = 's'
elif index == 10:
unit = 't'
path_file_name = path_time+'/%s_%s.txt' % (roomid, unit)
writeTop(path_file_name, '%s' % (res_json))
def getUserAnalyze(res_json, roomid, unit):
path_result = 'result/%s' % (getYesterday())
if not os.path.exists(path_result):
os.makedirs(path_result)
print "create dir %s"%(path_result)
path_time = path_result+'/topuser'
if not os.path.exists(path_time):
os.makedirs(path_time)
print "create dir %s"%(path_time)
path_file_name = path_time+'/%s_%s.txt' % (roomid, unit)
writeTop(path_file_name, '%s' % (res_json))
def getPlatformAnalyze(res_json, total):
path_result = 'result/%s' % (getYesterday())
if not os.path.exists(path_result):
os.makedirs(path_result)
print "create dir %s"%(path_result)
path_platform = path_result+'/platform'
if not os.path.exists(path_platform):
os.makedirs(path_platform)
print "create dir %s"%(path_platform)
path_file_name = path_platform+'/lulaoye_%s.txt' % (total)
writeTop(path_file_name, res_json)
# danmu数据分析
def analyzeDanmu(path_name):
if not os.path.exists(path_name):
print 'no file'
else:
for root, dirs, files in os.walk(path_name):
for file in files:
if file != '.DS_Store':
roomid = re.findall("\\d+", file)[0]
text = open('%s/%s' % (path_name, file), 'r').read()
getWordCloud(text, roomid) # 获取词云
getTopWC(text, 'a', roomid) # 获取形容词Top 30
getTopWC(text, 'v', roomid) # 获取动词Top 30
getTopWC(text, 'n', roomid) # 获取名词Top 30
# data数据分析
def analyzeData(path_name):
result_json = {}
result_list = []
result_total = 0
if not os.path.exists(path_name):
print 'no file'
else:
for root, dirs, files in os.walk(path_name):
for file in files:
if file != '.DS_Store':
roomid = re.findall("\\d+", file)[0]
path = '%s/%s' % (path_name, file)
getClimax(path, roomid, 3) # 取前三位,即按小时统计
getClimax(path, roomid, 6) # 取前六位,即按分钟统计
getClimax(path, roomid, 9) # 取前十位,即按秒统计,数据庞大,无意义
# 取前十位,即按秒统计,此处10作为标记为,统计每秒弹幕Top30
getSecondTop(path, roomid, 10)
getUserTop(path, roomid) # 获取用户发送弹幕数量Top30
# 分析今日弹幕总数量
num = len(open(path, 'r').readlines())
result_total = result_total + num
result_list.append({"roomid": roomid, "num": num})
result_json["data"] = result_list
res_json = json.dumps(result_json)
getPlatformAnalyze(res_json, str(result_total))
# 获取平台数据信息 总条数
def getPlatformData():
path_name = 'result'
total = 0 # 总的平台弹幕数
yesnum = 0 # 昨日平台弹幕数
for root, dirs, files in os.walk(path_name):
for file in files:
if file[:7] == 'lulaoye':
count = re.findall("\\d+", file)[0]
total = total + int(count)
path_platform = '%s/%s/platform' % (path_name, getYesterday())
result_list = [] # 主播name id 弹幕数量信息
absent_live = [] # 未直播主播
present_live = [] # 直播主播
all_live = [] # 平台所有主播
if os.path.exists(path_platform):
for root, dirs, files in os.walk(path_platform):
for file in files:
if file[:7] == 'lulaoye':
count = re.findall("\\d+", file)[0]
yesnum = int(count)
txt = open('%s/%s' % (path_platform, file)).read()
array = json.loads(txt)['data']
for a in array:
present_live.append(a['roomid']) # 把房间id添加到直播主播中
a.update(name=config.DOUYU_ROOM_DICT[a['roomid']])
result_list.append(a)
# 获取平台所有主播
for a in config.DOUYU_ROOM:
all_live.append(a['roomid'])
# 差集求出未直播主播
absent_live = list(set(all_live).difference(set(present_live)))
# 构造未直播主json
absent_live_dict = []
for a in absent_live:
name = config.DOUYU_ROOM_DICT[a]
absent_live_dict.append({'roomid': a, 'name': name})
period_dict = getPeriodDanmu() # 获取时间段弹幕活跃数
result_json = {"periodnum":period_dict,"nolive": absent_live_dict, "liveinfo": result_list, "total": total, "time": getYesterday(
), "livenum": len(config.DOUYU_ROOM), "live": config.DOUYU_ROOM, "yesnum": yesnum}
res_json = json.dumps(result_json)
path_platform = 'platform/%s' % (getYesterday())
if not os.path.exists(path_platform):
os.makedirs(path_platform)
print "create dir %s"%(path_platform)
with open('%s/data.txt' % (path_platform), 'w') as f: # 清除再写入
f.write(res_json)
print "write finish %s/data.txt"%(path_platform)
def getUserTop(path_name, roomid):
file = open(path_name)
text = [re.findall("\\*\\[(.*?)\\]\\*", line)[0] for line in file]
result = Counter(text).most_common(30)
result_json = {}
result_list = []
for r in result:
result_list.append({"nickname": r[0], "num": r[1]})
result_json["data"] = result_list
res_json = json.dumps(result_json)
unit = 'st' # 发送弹幕top
getUserAnalyze(res_json, roomid, unit)
file.close()
def getSecondTop(path_name, roomid, index):
file = open(path_name)
text = [line[1:index-1] for line in file]
result = Counter(text).most_common(30)
result_json = {}
result_list = []
for r in result:
result_list.append({"time": r[0], "num": r[1]})
result_json["data"] = result_list
res_json = json.dumps(result_json)
getTimeAnalyze(res_json, roomid, index)
file.close()
def getClimax(path_name, roomid, index):
file = open(path_name)
text = [line[1:index] for line in file]
result = Counter(text)
result = dict(result)
result = sorted(result.iteritems(), key=lambda d: d[0], reverse=False)
result_json = {}
result_list = []
for r in result:
result_list.append({"time": r[0], "num": r[1]})
result_json["data"] = result_list
res_json = json.dumps(result_json)
getTimeAnalyze(res_json, roomid, index)
file.close()
# 修改文件权限供前端可以读取数据
def modifyPermission():
val = os.system("chmod 777 -R %s" % (config.ROOT))
if val == 0:
print "修改文件权限成功"
else:
print "修改文件权限失败"
# 上传图片到七牛云
def uploadQiniu(path_imgwc):
image = Image.open(path_imgwc)
output = io.BytesIO()
image.save(output, format='PNG')
data_bin = output.getvalue()
url = config.QINIUYUN
img_file = {'img': data_bin} # 此处img是服务器端post文件字段
data_result = requests.post(url, {}, files=img_file)
json_data = data_result.json()
return json_data['url']
# 获取出席主播roomid
def getPresentLive():
present_live = []
path = 'result/%s/imgwc' % (getYesterday())
for root, dirs, files in os.walk(path):
for file in files:
roomid = re.findall("\\d+", file)[0]
present_live.append(roomid)
return present_live
# 获取主播数据信息
def getLiveInfo(roomid):
live_info = {}
path = 'result/%s' % (getYesterday())
path_imgwc = '%s/imgwc/wc_%s.png' % (path, roomid)
path_time_h = '%s/time/%s_h.txt' % (path, roomid)
path_time_m = '%s/time/%s_m.txt' % (path, roomid)
path_time_t = '%s/time/%s_t.txt' % (path, roomid)
path_topuser = '%s/topuser/%s_st.txt' % (path, roomid)
path_topwc_a = '%s/topwc/%s_a.txt' % (path, roomid)
path_topwc_n = '%s/topwc/%s_n.txt' % (path, roomid)
path_topwc_v = '%s/topwc/%s_v.txt' % (path, roomid)
path_danmu_count = 'data/%s/danmu/DouYuTV_%s.txt' % (
getYesterday(), roomid)
if os.path.exists(path_danmu_count):
num = len(open(path_danmu_count, 'r').readlines())
live_info['count'] = num
else:
live_info['count'] = 0
if os.path.exists(path_imgwc):
url = uploadQiniu(path_imgwc)
live_info['imgwc'] = url
else:
live_info['imgwc'] = ''
if os.path.exists(path_time_h):
txt = open(path_time_h).read()
array = json.loads(txt)['data']
live_info['time_h'] = array
else:
live_info['time_h'] = []
if os.path.exists(path_time_m):
txt = open(path_time_m).read()
array = json.loads(txt)['data']
live_info['time_m'] = array
else:
live_info['time_m'] = []
if os.path.exists(path_time_t):
txt = open(path_time_t).read()
array = json.loads(txt)['data']
live_info['time_t'] = array
else:
live_info['time_t'] = []
if os.path.exists(path_topuser):
txt = open(path_topuser).read()
array = json.loads(txt)['data']
live_info['topuser'] = array
else:
live_info['topuser'] = []
if os.path.exists(path_topwc_a):
txt = open(path_topwc_a).read()
array = json.loads(txt)['data']
live_info['topwc_a'] = array
else:
live_info['topwc_a'] = []
if os.path.exists(path_topwc_n):
txt = open(path_topwc_n).read()
array = json.loads(txt)['data']
live_info['topwc_n'] = array
else:
live_info['topwc_n'] = []
if os.path.exists(path_topwc_v):
txt = open(path_topwc_v).read()
array = json.loads(txt)['data']
live_info['topwc_v'] = array
else:
live_info['topwc_v'] = []
live_info['name'] = config.DOUYU_ROOM_DICT[roomid]
return live_info
# 将主播数据信息写入文本
def writeLiveInfo():
path = 'platform/%s' % (getYesterday())
if not os.path.exists(path):
os.makedirs(path)
print "create dir %s"%(path)
live_list = getPresentLive()
for roomid in live_list:
result_json = {}
result_json["data"] = getLiveInfo(roomid)
res_json = json.dumps(result_json)
with open('%s/live_%s.txt' % (path, roomid), 'w') as f: # 清除再写入
f.write(res_json)
print "write finish %s/live_%s.txt"%(path,roomid)
# 获取时间段弹幕活跃数
def getPeriodDanmu():
period = {
"00":0,
"01":0,
"02":0,
"03":0,
"04":0,
"05":0,
"06":0,
"07":0,
"08":0,
"09":0,
"10":0,
"11":0,
"12":0,
"13":0,
"14":0,
"15":0,
"16":0,
"17":0,
"18":0,
"19":0,
"20":0,
"21":0,
"22":0,
"23":0,
}
path = 'result/%s/time'%(getYesterday())
for root, dirs, files in os.walk(path):
for file in files:
if 'h' in file: #文件名包含h的
txt = open('%s/%s'%(path,file)).read()
array = json.loads(txt)['data']
for a in array:
period[a['time']] = period[a['time']] + a['num']
period = sorted(period.iteritems(), key=lambda d: d[0], reverse=False)
return period
if __name__ == "__main__":
path = 'data' # 根目录
path_content_danmu = 'danmu' # 纯弹幕内容数据
path_content_data = 'data' # 包括弹幕发送者与时间数据
path_date = getYesterday() # 日期目录
# danmu数据分析
path_name = '%s/%s/%s' % (path, path_date, path_content_danmu)
analyzeDanmu(path_name)
# data数据分析
path_name = '%s/%s/%s' % (path, path_date, path_content_data)
analyzeData(path_name)
# 获取平台数据,结果保存在根目录platform中
getPlatformData()
# 写主播数据信息到文本
writeLiveInfo()
# 修改文件权限供前端可以读取数据
modifyPermission()
应用连接
酷安 搜索 斗鱼分析
Google Play 卢姥爷分析
fir.im 斗鱼分析
需要源码请留言