R语言简介与案例
一. R语言是什么?
如果说统计学是人类历史上的一次伟大跨越,那么R语言就是就是帮助统计学家走的更远的一双翅膀.R语言是什么?R语言就是一门帮助统计学家在计算机上进行数学计算的语言,有了它统计学家就可以与计算机更好地互动,并帮助统计学家更快更好的完成本专业的一些事情.
不过随着时代的发展,R语言作为一门计算机语言,也已经不仅仅能够完成它的最初使命.同时现在的它还能够完成许多的其他事情比如网络爬虫等等
二. 如何使用R语言?
R语言的使用十分简单.对于一般常用公式,R语言都已经做好了封装,将其封装在了内部.也就是说R语言已经将很多常用的数学公式写好了,对于数学中的各种函数与方法,在R中我们也给他们的计算机实现起了同样的名字”函数”.
比如假如我们在R中使用卡方检验来检验两个变量的相关性,那么只需要简单的调用”chisq.test()”函数就可以了.
举个例子,我们使用R中自带的卡方检验函数对R语言中自带的数据

上述结果表明数据集有很多因素变量,可以被认为是分类变量。 对于我们的模型,我们将考虑变量“AirBags”和“Type”。 在这里,我们的目标是找出所售的汽车类型和安全气囊类型之间的任何显着的相关性。 如果观察到相关性,我们可以估计哪种类型的汽车可以更好地卖什么类型的气囊。
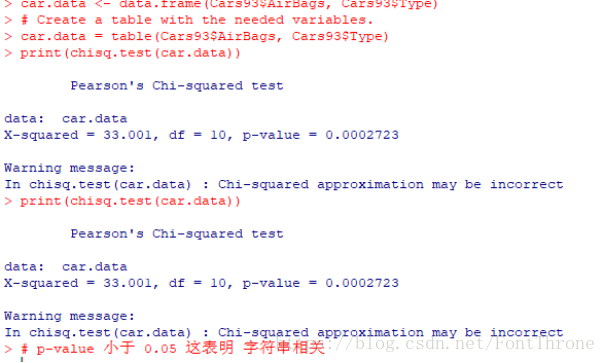
文中的前三行代码是从R语言中自带的数据库挑选出了汽车类型与安全气囊这两个数据,然后将其展示给了我们,而最后一行代码则使用”chisq.test()”函数对数据进行了卡方检验
从这里我们可以看出,对于使用R语言中的函数可以说是相当的简单了.
三. 在R语言中实现皮尔逊系数
皮尔逊系数是检验变量之间线性相关性的一种常用方法,虽然R语言中已经有了相关实现,不过这里我们将要自己实现一下.
首先我们来确认皮尔逊系数的一种实现方式,下面的这个公式十分简单,只要能够使用R语言中的求均值,求和,开平方等基本操作就可以了.
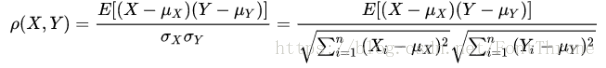

通过上面的这些操作,我们已经在R语言中是实现了皮尔逊系数的公式.如果有需要的话我们也可以将这个公式封装为我们自己的函数.只需要使用一条简单的语句声明即可.

现在我们已经拥有一个我们自己的函数了.
四. 使用R中的包
包是什么?
刚刚我们封装了我们自己的一个函数,而假如我们想要将我们自己的函数提供给别人使用,我们就需要将他们变成另外一种形式,也是就是包.
通过将我们自己的一些程序打成包发出去,就可以让别人使用我们的包.同样的我们也可以通过下载包的形式使用别人已经做好的包.这样我们都可以减少很多不必要的工作.也正因如此假如我们需要使用某一个R语言自身没有带的数学公式的时候,我们就可以去下载一些别人制作的包.这样一来,我们就不需要自己做一些重复造轮子的事情了.
而同样的在R中下载和使用包也是十分简单的.只需要”install.packages(“包名”)”即可.比如假如我们想要在R语言中使用随机森林算法.那么只需要

下面我们就在R语言中进一步利用randomForest 进行进一步实战.
(1) 随机森林randomForest 的语言
语法为---> randomForest(formula, data)
以下是所使用的参数的描述 -
其中:formula是描述预测变量和响应变量的公式。data是所使用的数据集的名称
(2) 选择数据
我们将使用名为readingSkills的R语言内置数据集来创建决策树。 它描述了某人的readingSkills的分数,如果我们知道变量“age”,“shoesize”,“score”,以及该人是否是母语。
以下是示例数据。
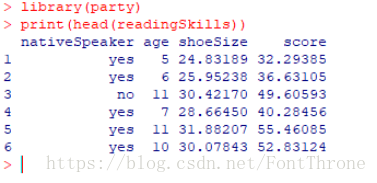
(3) 然后我们开始使用R语言中的随机森林算法对数据建模预测

(4) 结论:从上面显示的随机森林,我们可以得出结论,鞋码和成绩是决定如果某人是母语者或不是母语的重要因素。 此外,该模型只有1%的误差,这意味着我们可以预测精度为99%。
五.安装问题
(1)win下请到官网下载exe安装文件,直接安装即可,R语言镜像目录,Rstudio