本文参考《kafka权威指南》(薛 译),《kafka入门与实践》(牟 著)
1、kafka是什么?
通俗说法:高吞吐量、分布式的消息发布订阅系统
官方说法:分布式流式处理平台
2、kafka可以拿来做什么?
2.1 消息系统(消息队列)
消息系统主要是解决 应用解耦、异步通信、流量控制等问题。
拿我们最常见的移动端后台开发来说。我们移动端后台开发最常见交互方式是基于无状态的HTTP请求响应模式,但是往往需要也需要做消息推送系统。通常我们将主要的业务逻辑用HTTP方式实现,然后另外为公司做一个通用消息推送系统。没有引入消息队列之前的做法是:
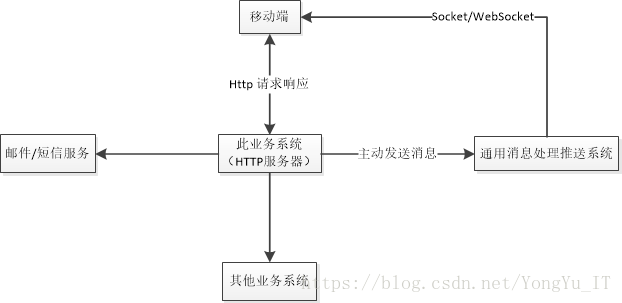
这样的系统至少有这几个方面的问题:
a. 高耦合,HTTP服务器需要知道消息推送系统的API,不灵活。正是由于高耦合,也非常不利于扩展(例如在此基础上集成另外一套系统)。
b. 基于同步方式,只要出现 HTTP消息发送 > 消息系统处理能力 的情况整个系统(包括HTTP服务器)都会被阻塞。
c. 没有消息缓存,没有做到高可用。
于是乎,我们便引入了消息系统,于是整个架构转变成:

比较流行的消息系统有:kafka,recketMQ,rabbitMQ,zeroMQ,ActiveMQ,MetaMQ,Redis。
各种消息系统对比,参见https://blog.csdn.net/sunxinhere/article/details/7968886
2.2 流处理
可以在kafka基础上集成kafka streams、apache samza、storm等框架以实时的方式处理消息(流,从生产者流向消费者的数据),这就是所谓的流处理。与之比较,Hadoop是离线处理数据的框架。
3、kafka基本概念
3.1 消息、批次、模式、分区、主题
kafka的数据单元被称为消息,类似于数据库里面的行数据(一条记录)。消息由一个固定长度的消息头和一个可变长度的消息体构成。对kafka而言,消息是由字节数组组成的,没有特别格式和含义。可以(也可以不)为每条消息指定一个键(键是元数据,保存于zookeeper内),类似地,键也是字节数组,没有特别格式和含义。
为了提高效率,消息总是分批次地写入kafka,批次就是一组消息。同一批次的消息属于同一主题和分区。为了减小网络开销,不允许一条消息单独穿行与网络。
消息(和键)对kafka虽然是无意义的字符数组,但是对生产和消费数据的应用程序来说是有意义的。消息的格式(例如XML或者JSON)即模式是生产者和消费者读懂消息的关键。
kafka的消息通过主题进行分类。主题类似于数据库里面的表,存放的是同类型数据。生产者将消息发送给特定主题,消费者订阅主题或者从主题的某些分区消费数据。
一个主题可以分成若干分区,主题对应的分区数目可以在kafka启动时指定,也可以在创建主题时指定。分区在物理实现上是一个文件夹。分区的命令规则为“主题名-分区编号”。分区编号从0开始,到分区总数减1。
每个分区又可以拥有多个副本,每个分区(包括分区的副本)都独立维护一个提交日志。消息以追加的方式写入分区,然后以先入先出(队列)的顺序被读取。需要注意的是,kafka只能保证单个分区内消息是有序的,无法保证整个主题内消息的有序的(因为主题可以包含好几个分区,一个分区又可以有好几个副本)。正是得益于这种顺序写磁盘,kafka才可以实现高吞吐量。
主题通过分区来实现数据冗余与伸缩性。分区使得kafka拥有更强的并发处理能力。分区是消息被顺序处理(提交日志)的保证,是实现对消息负载均衡的基础。分区可以分布在不同的服务器上,也就是说主题可以实现分布式,从而提高了可用性。每个分区又有多个副本,分区的副本也可以分布于集群上从而进一步提高可用性。
3.2 生产者、消费者
kafka的客户端主要分为两类:生产者和消费者。(还有其他类型的客户端:kafka connect API,用于数据集成;流式处理的kafka streams。)
生产者通过kafka API向kafka写入消息。消息必须从属于某个特定的主题。默认情况下kafka会将消息均匀地分布到主题的所有分区上,生产者并不需要关心消息会被写入哪个分区。但是kafka也允许生产者直接将消息写到指定的分区上。
消费者通过kafka API从kafka读取消息。消费者可以订阅一个或者多个主题,并按照消息生成的顺序读取消息。消费者通过纪录和比对消息的偏移量来判别消息是否已被读取。注意,kafka的只负责纪录消息和删除消息(基于失效机制),不负责纪录消息是否被消费,判别数据是否被消费是消费者自己的事。
偏移量是另一种元数据(保存在zookeeper内),是一个不断递增的整数值。在创建消息时kafka会把它添加到消息里。偏移量由分区进行维护,在给定的分区内偏移量是唯一的、不变的(对于消息)、递增的。消费者最好把从每个分区最后读到消息的偏移量保存在zookeeper或者kafka内,这样即使消费者关闭或者重启,处理消息进度也不会丢失。
经常会出现有多个消费者订阅同一个主题的情况发生,这时需要将消费者构成一个消费群组。消费群组要保证每一个分区只能被一个消费者使用(但是一个消费者可以使用多个分区)。消费者和分区间的映射关系就是消费者对分区的所有权关系。
3.3 broker和集群
每个独立的kafka服务器就是一个broker(又称代理)。broker的主要负责:
接收生产者消息;为消息设置偏移量;提交消息到磁盘保存;为消费者提供服务,对读取分区的请求做出响应,返回已提交到磁盘的消息。
kafka集群是由若干个broker组成的。每个集群都会自动选举唯一的一个broker兼任集群控制器。集群控制器负责分区分配(将分区分配给broker)和集群监控(监控各个broker)。
一个分区可以有多个副本,分配给多个broker。这些broker里面只有一个是这个分区的拥有者(也称为这个分区的首领(Leader)),其他的broker就是分区的跟随者(Follower)。当分区分配给多个broker时会发生分区复制,这种复制机制为分区提供了冗余,提高了可用性。
由于分区副本的存在,必须保证分区与其副本间数据的一致性。只有Leader才负责处理客户端对分区的读写请求,其余的Follower只需要从Leader同步分区数据即可。
一旦首领broker失效,其他的broker借助分区副本,可以接管分区的领导权,不过此时生产者和消费者必须重新连接到新的首领broker。
3.4 保留消息
这是kafka区别于其他消息队列的一个重要特性。这个特性与 redis失效策略+存盘策略 相似,只不过redis是在主要实在内存里实现的,而kafka主要是在磁盘上实现的。
kafka不会立即删除已被消费的消息,也不会将消息一直保留下去。kafka broker默认的消息保留策略是这样的:
消息保留策略应用于主题。可以为主题的消息保留设置两个上限:保留消息时间(例如7天),保留消息总大小(例如1G)。当达到任意上限时,按照时间先后顺序,旧消息将会丢失。这样在任意时刻,保留消息总量都不会超过指定大小。
4、kafka优势
1、支持多个生产者和消费者。
一般的消息队列,消息一旦被一个消费者读取即消失,其他的消费者就再也无法获取它。而kafka多个消费者可以从各自独立的消息流上获取数据,相互不干扰。此外,多个消费者还可以按需组成消费群组共享一个消息流,这样整个群组可以实现对消息只消费一次。
2、消息持久化
就是上面说的保留消息。
这里需要进一步说明的是,kafka是一个高度依赖文件系统来实现存储和缓存消息的。在我们的直观印象里,文件系统(即磁盘)的读写性能远远不如内存,为什么kafka要使用文件系统来做消息缓存呢?
首先,磁盘不是任何情况下都很慢!磁盘的随机读取性能低下,但是顺序读写性能并不低。(kafka官网介绍,顺序读写速度大约是随机读写速度的6000多倍)。实际上kafka基于提交日志和偏移量实现的分区并不支持对消息队列的随机访问。
其次,JVM对内存的利用效率并不高(坑爹的GC)。而kafka是基于JVM实现的(尽管不是直接使用java语言)。
综上两点,kafka通过利用磁盘的顺序读写实现了高吞吐量。从这里也可以看出kafka的性能非常仰仗磁盘的I/O性能以及磁盘碎片的情况。
3、支持集群
kafka依赖zookeeper对集群进行协调管理。
4、高吞吐量
除了上文讲到的充分利用磁盘顺序读写的高性能以外。
在kafka在数据写入和数据同步时通过对系统函数sendFile()的调用,使得数据完全在内核中操作,避免了内核缓存和用户缓存间的数据拷贝,实现了“零拷贝”,操作效率极高。
kafka还支持数据压缩和批量发送。
kafka采用了多分区存储消息。
这些都提高了kafka的吞吐能力。