Spark有三种运行模式,分别为:
local模式-只运行在本地,相当于伪分布式
standalone模式-这种模式只需要安装Spark即可,使用自带的资源管理器
Spark on yarn/mesos模式-这种模式Spark将使用yarn/mesos作为资源管理器
一般来说,standalone适合只想体验一把Spark集群的人,如果想将Spark应用于生产环境,还需要借助第三方的资源调度模块来优化Spark的资源管理。
Spark以哪一种模式运行可以在执行spark-shell或者spark-submit命令时通过指定 --master参数来设置,如果不设置默认以local方式单机运行
由于我想在Spark安装完成后运行在yarn之上,所以在配置过程中添加了一些hadoop的配置,如果想使用Spark on yarn需要安装Hadoop2.0以及以上版本。本例是在Hadoop2.4.0平台搭建,当然,如果仅是做学习体验用只使用local或standalone模式可以不用安装Hadoop。
关于Hadoop集群的安装部署,请参考:http://blog.csdn.net/u013468917/article/details/50965530
本次在上述双节点Hadoop集群的基础上安装Spark。两个节点分别为:
master 192.168.1.131
slave1 192.168.1.125
方式一:安装了hadoop的spark
1.搭建hadoop集群
hadoop的hdfs文件系统是整个生态圈的基础,因为数据量大了以后,数据一般就都放hdfs上头了。因为四台测试机之前已经搭建好了hadoop集群环境,而且经过本宝宝测试,hadoop集群也是可用的,所以就省了搭hadoop集群的功夫。
2.配置集群host
四台机器的hostname如下:
namenodetest01.hadoop.xxx.com 192.168.9.247
datanodetest01.hadoop.xxx.com 192.168.9.248
datanodetest02.hadoop.xxx.com 192.168.9.249
datanodetest03.hadoop.xxx.com 192.168.9.228
请确认在四台机器的/etc/hosts里都添加上相应节点的信息。
3.配置集群免密登录
因为之前搭好了hadoop环境,最开始我以为这几个节点的免密登录时配置好的,所以事先没有配置。后来等把spark布好启动以后,才发现提示让我输密码,很明显就是事先没配置好免密登录。
配置的方式也很简单,因为我打算让namenodetest01机器做master,cd到home目录下的.ssh,然后执行:
ssh-keygen -t rsa此时会在.ssh目录下生成id_rsa跟id_rsa.pub,分别对应的为私钥与公钥。
接下来,将namenodetest01的公钥scp到另外三台机器上:
scp id_rsa.pub root@datanodetest01:~/.ssh
scp id_rsa.pub root@datanodetest02:~/.ssh
scp id_rsa.pub root@datanodetest03:~/.ssh再分别登到01,02,03两台机器,将刚传过来的公钥添加到authorized_keys中:
[root@datanodetest02 .ssh]# pwd
/root/.ssh
cat id_rsa.pub >> authorized_keys至此,master免密登录另外两个节点配置完毕。
4.安装jdk,确保jdk版本1.7以上
因为之前搭建好了hadoop环境,所以jdk已经配置好。
需要注意的是:spark需要jdk1.7及以上。有一个节点的spark配置好以后,最开始spark-shell无法启动,但是其他两个节点的spark-shell正常启动没有问题。后来发现无法启动那个节点的jdk被人配置为1.6。。。后来修改jdk为1.7以后即可正常启动 spark-shell。
5.安装scala
因为spark是scala开发,所以scala是需要配置的。去scala官网下载相应的scala包,比如我下载的是scala-2.11.8.tar,tar -zxvf 解压以后,生成scala-2.11.8目录。查看一下里面的结构
[root@datanodetest02 soft]# tree -L 1 scala-2.11.8
scala-2.11.8
├── bin
├── doc
├── lib
└── man
4 directories, 0 files然后在/etc/profile里配置scala的环境变量:
export SCALA_HOME=/data/wanglei/soft/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH保存退出,source一下配置文件让其立刻生效。然后再运行scala:
[root@datanodetest02 soft]# scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_51).
Type in expressions for evaluation. Or try :help.
scala>可见在02这个机器上scala已经成功配置好。其余两台机器也按照此过程安装配置即可。
6.开始布spark
因为我们打算用namenodetest01机器做master,所以先在namenode机器上配置spark。
先下载spark的gz包,我下载的是spark-1.6.0-bin-hadoop2.4.tgz,然后tar -zxvf解压。
看看里头有些什么
[root@namenodetest01 soft]# tree -L 1 spark-1.6.0-bin-hadoop2.4
spark-1.6.0-bin-hadoop2.4
├── bin
├── CHANGES.txt
├── conf
├── data
├── ec2
├── examples
├── lib
├── LICENSE
├── licenses
├── logs
├── NOTICE
├── python
├── R
├── README.md
├── RELEASE
├── sbin
└── work然后cd到bin目录里,执行spark-shell脚本。如果能正常启动,说明在本机上没问题。如果不能正常启动,那就需要再排查其他原因。比如我前面提到的jdk版本问题。
7.对master进行相应的配置
cd到spark目录里的conf文件夹下。首先将spark-env.sh.template文件mv为spark-env.sh。然后添加配置项:
示例1:没有将spark跑在yarn上面的配置
export JAVA_HOME=/usr/java/default/###scala或者是spark-shell export SCALA_HOME=/data/wanglei/soft/scala-2.11.8 export HADOOP_HOME=/usr/lib/hadoop export STANDALONE_SPARK_MASTER_HOST=namenodetest01 export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST ### Let's run everything with JVM runtime, instead of Scala export SPARK_LAUNCH_WITH_SCALA=0 export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib export SPARK_MASTER_WEBUI_PORT=18080 #export SPARK_MASTER_PORT=7077 #export SPARK_WORKER_PORT=7078 #export SPARK_WORKER_WEBUI_PORT=18081 #export SPARK_WORKER_DIR=/var/run/spark/work #export SPARK_LOG_DIR=/var/log/spark #export SPARK_PID_DIR='/var/run/spark/' if [ -n "$HADOOP_HOME" ]; then export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:${HADOOP_HOME}/lib/native fi export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
示例二: 如果是配置spark on yarn的配置(并且使用了zk做HA)
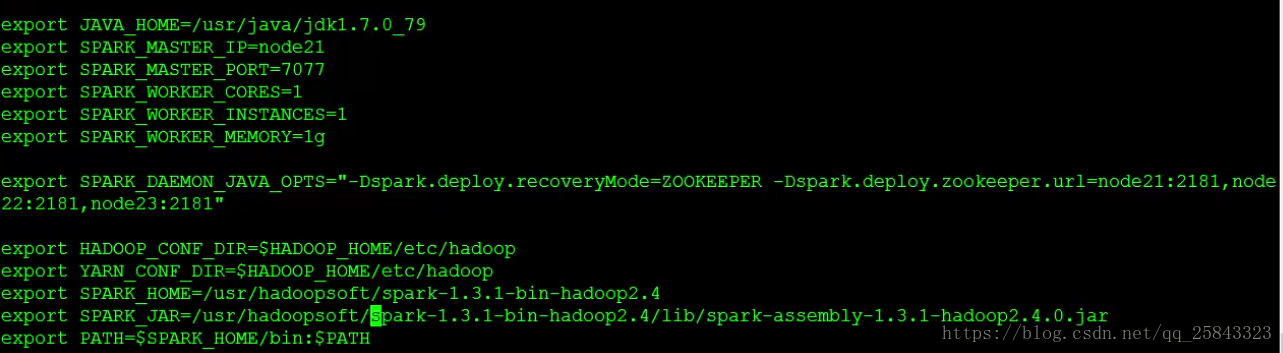
spark_jar是配置spark跑在yarn上面 的时候找到spark所在的路径
配置完就可以直接提交任务了(会将相应的任务jar包和spark的jar包上传到hdfs里面去,然后分发到yarn)


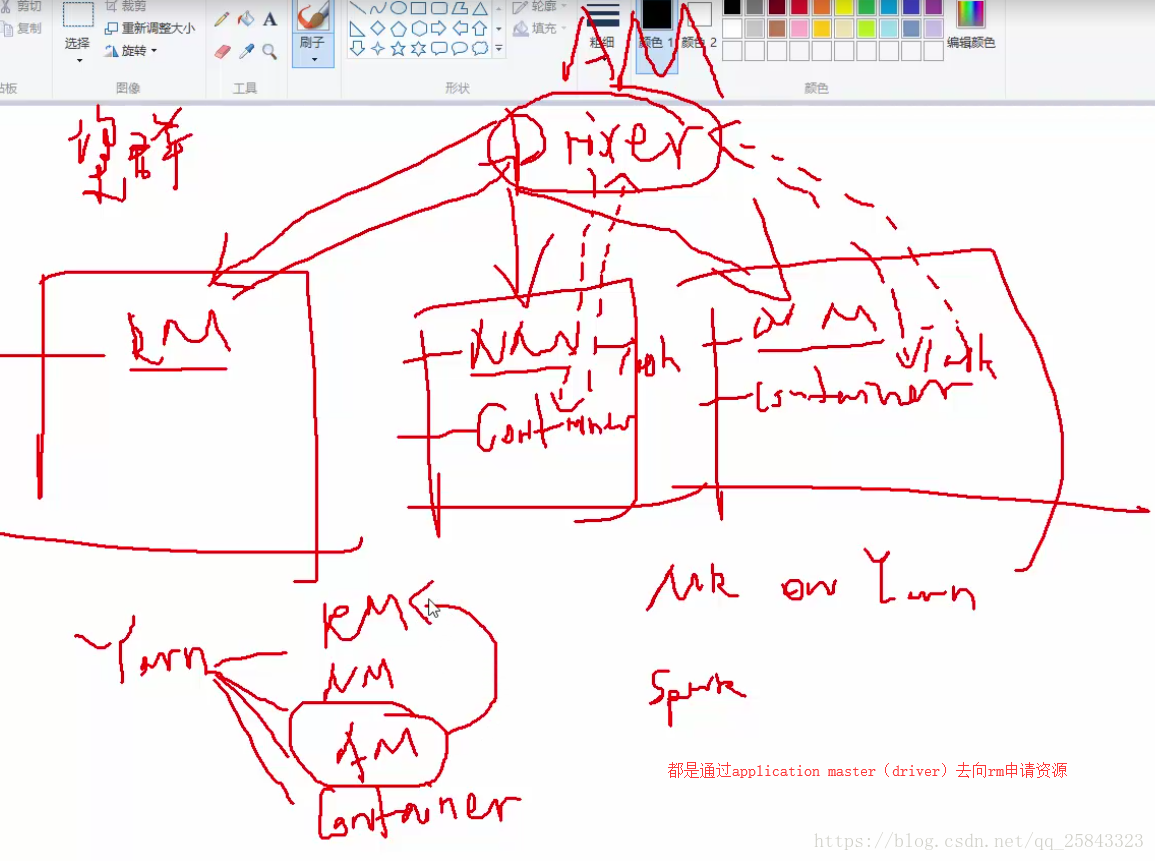
说明:
参数SPARK_WORKER_MEMORY用于指定在worker可用最大内存。这里分配了6GB,读者可以根据自己机器的配置自行分配,但是要为操作系统和其它服务预留足内存。
参数SPARK_MASTER_IP和MASTER根据自己主机的ip修改即可。
需要注意的是SPARK_MASTER_WEBUI_PORT默认的端口是8080,实际中8080端口是最为常用的端口,很可能被其他应用所占用。所以我们将其改为18080。经过测试发现,即使8080端口被其他应用程序占用,我们将其配为8080端口后,spark-shell能够正常启用,但是看到的页面是其他应用程序的界面。
2、修改conf/slaves文件:
本次示例集群有两个节点,一个master节点和一个slave1节点。所以在slaves文件中只需要添加:
然后将slaves.template文件cp一份为slaves,在slaves里添加如下配置:
datanodetest01
datanodetest02
datanodetest03很明显,这个就是我们的三个worker节点。
8.分发到其他三个节点
master配置完成以后,将spark的整个包内容scp到另外三个节点上,不需要修改任何配置项。
注意:因为按集群模式启动时,会按master上的路径去找spark。所以其他节点spark的路径需要跟master保持一致。
分发完成以后,去分别取另外三个节点执行spark-shell,看看能不能正常启动,以便提早发现问题。
9.启动spark集群
在master上,cd到spark里的sbin目录,执行start-all.sh脚本:
start-all.sh然后看到shell输出如下:
starting org.apache.spark.deploy.master.Master, logging to /data/wanglei/soft/spark-1.6.0-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-datanodetest01.hadoop.xxx.com.out
datanodetest01: starting org.apache.spark.deploy.worker.Worker, logging to /data/wanglei/soft/spark-1.6.0-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-datanodetest01.hadoop.xxx.com.out
datanodetest02: starting org.apache.spark.deploy.worker.Worker, logging to /data/wanglei/soft/spark-1.6.0-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-datanodetest02.hadoop.xxx.com.out
datanodetest03: starting org.apache.spark.deploy.worker.Worker, logging to /data/wanglei/soft/spark-1.6.0-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-datanodetest03.hadoop.xxx.com.out很明显可以看出,集群显示启动了master,然后在启动了三个worker。
如果是用yarn作为调度器得话不能使用使用start-all,否则是很危险的,因为同时启动了yarn 的调度器,然后standalone的调度器也起来了
10.查看集群状态
spark集群的默认web管理页面端口为8080,url为http://master:8080
由于我们之前配置了18080端口,将上面的端口地址改为18080即可。
查看一下页面:
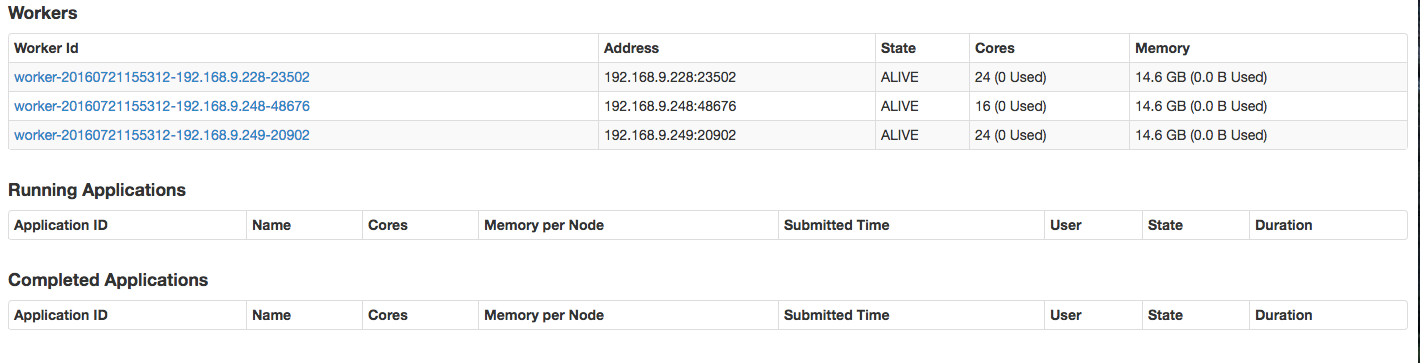
可以看出,集群有三个worker,而且现在都是处于正常工作状态。
正常情况下,master节点会出现master进程,可以用jps查看:
#jps
23526 Jps
2112 Master
7235 NameNode
7598 SecondaryNameNode
7569 ResourceManager
worker节点会有worker进程:
#jps
23489 Jps
1258 Worker
1364 DataNode
24587 NodeManager
11.运行第一个spark代码
在 ./examples/src/main 目录下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等语言的版本。我们可以先运行一个示例程序 SparkPi(即计算 π 的近似值),执行如下命令:
./run-example SparkPi然后会输出很多运行内容
[root@datanodetest02 bin]# ./run-example SparkPi
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/07/20 14:16:34 INFO SparkContext: Running Spark version 1.6.0
16/07/20 14:16:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/07/20 14:16:35 INFO SecurityManager: Changing view acls to: root
16/07/20 14:16:35 INFO SecurityManager: Changing modify acls to: root
16/07/20 14:16:35 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/07/20 14:16:35 INFO Utils: Successfully started service 'sparkDriver' on port 44304.
...里面有一行输出为:
Pi is roughly 3.14374这就把Pi的值给算出来了。
通过运行这个简单的测试代码,我们很容易就发现spark的优势:与MR相比,spark的速度快很多。MR即使最简单一个任务,从任务提交到分配资源到任务正式运行最后输出结果,都接近分钟级。大家看看spark的执行:
...
16/07/20 14:16:38 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1031 bytes result sent to driver
16/07/20 14:16:38 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1031 bytes result sent to driver
16/07/20 14:16:38 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 701 ms on localhost (1/2)
16/07/20 14:16:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 730 ms on localhost (2/2)
16/07/20 14:16:38 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/07/20 14:16:38 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) finished in 0.744 s
16/07/20 14:16:38 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 1.009645 s
Pi is roughly 3.14374
...12.关闭spark集群
如果要关闭spark集群,很简单。cd到spark目录下的sbin目录,然后执行stop-all.sh脚本即可。
问题记录:
初次安装hadoop时参考网上文章,没有提到要配置HADOOP_CONF_DIR或者YARN_CONF_DIR变量。如果没有配置这两个变量,hadoop可以正常运行,hadoop上的hive也可以运行。但是spark会报错。所以需要确认添加了HADOOP_CONF_DIR或者YARN_CONF_DIR环境变量。配置示例:$HADOOP_HOME/etc/hadoop
方式二:Spark(standslone)集群安装
1.1. 安装
1.1.1. 机器部署(standslone模式)
准备两台以上Linux服务器,安装好JDK1.7
1.1.2. 下载Spark安装包
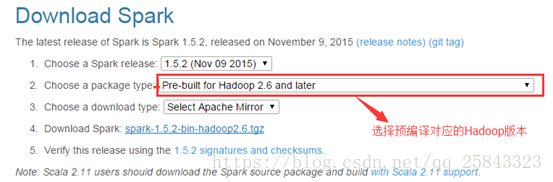
http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
上传解压安装包
上传spark-1.5.2-bin-hadoop2.6.tgz安装包到Linux上
解压安装包到指定位置
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz -C /usr/local
(sbin ------各种交互窗口 ;bin -----启动文件)
1.1.3. 配置Spark
进入到Spark安装目录
cd /usr/local/spark-1.5.2-bin-hadoop2.6
进入conf目录并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
在该配置文件中添加如下配置

保存退出
重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
node2.itcast.cn
node3.itcast.cn
node4.itcast.cn
保存退出
将配置好的Spark拷贝到其他节点上
scp -r spark-1.5.2-bin-hadoop2.6/ node2.itcast.cn:/usr/local/
scp -r spark-1.5.2-bin-hadoop2.6/ node3.itcast.cn:/usr/local/
scp -r spark-1.5.2-bin-hadoop2.6/ node4.itcast.cn:/usr/local/
Spark集群配置完毕,目前是1个Master,3个Work,在node1.itcast.cn上启动Spark集群
/usr/local/spark-1.5.2-bin-hadoop2.6/sbin/start-all.sh
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://node1.itcast.cn:8080/

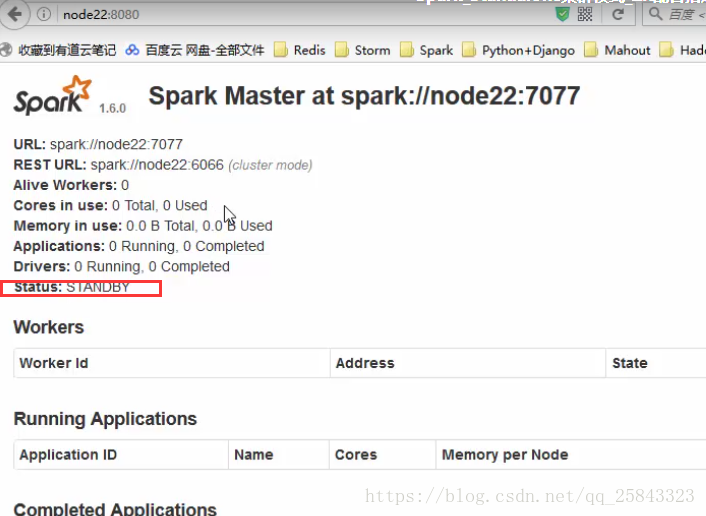
到此为止,Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单:
Spark集群规划:node1,node2是Master;node3,node4,node5是Worker
安装配置zk集群,并启动zk集群
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark"
1.在node1节点上修改slaves配置文件内容指定worker节点
2.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
client模式启动(driver和client提交任务是在同一个节点,所以可以在shell界面上看到日志)

cluster模式启动(会有一个driver,但是和提交程序的那个clinet不在同一台机器上,一个app对应一个driver,driver丢在worker虽在的机器执行)


配置高可靠的方式(这里采用的是zk的方式)
最为热备的机器的master要修改一下

然后单独启动这个节点master

其他几种运行模式:
1.本地模式,直接解压就可以使用了,不用配置其他的,等价于在eclipse本地跑
