这系列的blog有点扎心的,大多是面试不会的,或者觉得回答不够完美的题目,不过话说回来,被问到不会一次,回来看看,下次就不会扎心啦啦啦!
1. JDK vs JRE vs JVM
JDK:Java Development Kit,JDK顾名思义是java开发工具包,是程序员使用java语言编写java程序所需的开发工具包,是提供给程序员使用的。JDK包含了JRE,同时还包含了编译java源码的编译器javac,还包含了很多java程序调试和分析的工具:jconsole,jvisualvm等工具软件,还包含了java程序编写所需的文档和demo例子程序。
JRE:Java Development Kit,JRE顾名思义是java运行时环境,包含了java虚拟机,java基础类库。是使用java语言编写的程序运行所需要的软件环境,是提供给想运行java程序的用户使用的。
JVM:Java Virtual Machine,JVM是java虚拟机,是Java编程语言的核心。当我们运行一个程序时,JVM负责将字节码转换为特定机器代码。JVM也是平台特定的,并提供核心的Java方法,例如内存管理、垃圾回收和安全机制等。JVM 是可定制化的,我们可以通过Java 选项(java options)定制它,比如配置JVM 内存的上下界。JVM之所以被称为虚拟的是因为它提供了一个不依赖于底层操作系统和机器硬件的接口。这种独立于硬件和操作系统的特性正是Java程序可以一次编写多处执行的原因。
区别:
- JDK是用于开发的而JRE是用于运行Java程序的,JDK包含JRE。
- JDK和JRE都包含了JVM,从而使得我们可以运行Java程序。
- JVM是Java编程语言的核心并且具有平台独立性。
2. Java中final,finally和finalize()
final:修饰变量---值不可以被修改;修饰方法---方法不可以被重写;修饰类---类不可以被继承。
finally:一般是用于异常处理中,提供finally块来执行任何的清楚操作,try{} catch(){} finally{}。finally关键字是对java异常处理模型的最佳补充。finally结构使代码总会执行,不关有无异常发生。使得finally可以维护对象的内部状态,并可以清理非内存资源。finally在try,catch中可以有,可以没有。如果try-catch中有finally则必须执行finally块中的操作。一般情况下,用于关闭文件的读写操作,或者是关闭数据库的连接等等。
finalize():finalize()是方法名。在java中,允许使用finalize()方法在垃圾收集器将对象从内存中清理出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是Object类中定义的,因此,所有的类都继承了它。
3. Java中创建线程的几种方法
- 继承Thread类创建线程类
(1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2)创建Thread子类的实例,即创建了线程对象。
(3)调用线程对象的start()方法来启动该线程。
public class ThreadTest extends Thread{
int i = 0;
//重写run方法,run方法的方法体就是现场执行体
public void run()
{
for(;i<100;i++){
System.out.println(getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i< 100;i++)
{
System.out.println(Thread.currentThread().getName()+" : "+i);
if(i==20)
{
new FirstThreadTest().start();
new FirstThreadTest().start();
}
}
}
}
上述代码中Thread.currentThread()方法返回当前正在执行的线程对象。GetName()方法返回调用该方法的线程的名字。
- 通过Runnable接口创建线程类
(1)定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程。
- 通过Callable和Future创建线程
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
下面具体整理一下继承Callable和Runnable的两种创建线程的方法。估计会有点长,另开一个blog吧。(贴链接的地方……)
4. Java中的克隆
为什么要克隆:需要使用一个对象在某个时刻的状态(比如某个时刻对象中已经被赋值的属性),为了能够保存当时对象的状态,Java出现了克隆的操作。
操作:首先需要实现Cloneable接口,然后重写clone()方法即可。Cloneable接口是一个空接口,它的作用是做标记;clone()方法是Object类中的protected方法,也是一个native方法(本地方法,和平台有关,native方法一般可移植性不高,JVM中运行时在本地方法区,native方法主要用于加载文件和动态链接库)。
深克隆vs浅克隆vs多层克隆:
深克隆:当拷贝的对象中含有引用类型属性时,我们在重写clone()方法时除了调用父类中的clone()方法,也需要调用引用类型的clone()方法,这样才能保证克隆后的对象跟原对象完全相互独立,没有任何关联。
首先修改引用类型,让它能够进行克隆:
public class Student implements Cloneable{
private String name;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}然后重写本类的clone()方法:
public class School implements Cloneable {
private int year;
private Student student;
@Override
protected Object clone() throws CloneNotSupportedException {
School school = (School) super.clone();
school.student = (Student) student.clone();
return school;
}
}这样就能够实现对School对象的深克隆。
深克隆适用于对含有引用类型属性的对象的克隆。
浅克隆:如果重写时没有调用引用类型的clone()方法,只是调用父类中的clone()方法,那么两个对象虽然在内存地址上彼此独立,但是对象中的引用类型属性却指向同一个对象,当原对象中的引用类型属性发生变化时,克隆的对象也会跟着发生变化。
浅克隆适用于对只包含原始数据域或者不可变对象域(比如String类型)的克隆。
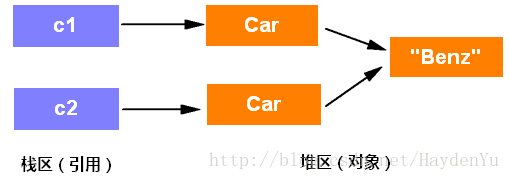
public class Car implements Cloneable {
private String name;
public Car(String name){
this.name = name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone(); //只调用了父类的clone()方法,没有调用引用类型的clone()方法
}
public static void main(String[] args) {
try {
Car c1 = new Car("Benz");
Car c2 = (Car) c1.clone();
System.out.println(c1 == c2); //false
System.out.println(c1.name.equals(c2.name)); //true
System.out.println(c1.name == c2.name); //true
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}这段代码实现了对Car对象的一个浅克隆,重写的clone()方法中只是返回了Car的父类clone()方法,String是一个引用类型,因此System.out.println(c1.name == c2.name) 会输出为true,表示原对象跟克隆对象中的String属性指向了同一个字符串。但是String类型是不可变对象域,所以这段代码实现的克隆不会有任何问题。
原理图:
多层克隆:如果一个对象中包含了很多引用类型属性,或者内层引用类型的类里面又包含引用类型,使用clone()方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。
public class School implements Serializable{
private static final long serialVersionUID = 1L;
private Student student;
public School doClone() {
School school = null;
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
school = (School) ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return school;
}
}School中的引用类型Student也要实现序列化:
public class Student implements Serializable{
private String name;
}这样就可以通过序列化来对对象进行深拷贝。
总结一下:需要使用一个对象在某个时刻的状态(比如某个时刻对象中已经被赋值的属性),为了能够保存当时对象的状态,Java出现了克隆的操作。克隆有两种方法:实现Cloneable接口,重写clone()方法;实现Serializable接口使用Java对象串行化的特性。
克隆分为浅克隆和深克隆,浅克隆没有克隆对象中引用的其他对象,适用于数值或其他基本类型,如果原对象和浅克隆的子对象不可变,则共享线程安全,如果子对象属于一个不可变类(如String),则也使用浅克隆;而深克隆要克隆所有的子对象。
clone方法是Object类的protected方法,必须重新定义clone为public才能允许所有方法克隆对象。
Cloneable是一个标记接口,不包含任何方法,唯一作用就是在类型查询中使用instanceof。