最近有个客户需求私有化部署,但不需要大数据. 需要将数据统计改造,查了下,发现pandas和SparkSql比较像.
所以采用pandas做数据统计改造.
#读数据库
import pandas as pd
import pymysql
conn=pymysql.connect(host='xxx.xx.xx.xxx',port=3306,user='username',passwd='password',charset='UTF8',db='iot_register')
#统计当天所有地区新增
sql="select product_id,country_zh as country,province_zh as province,count(distinct device_id) as new_num from iot_register.device_info where create_time between '2017-08-17 00:00:00' and '2017-08-17 23:59:59' group by product_id,country,province"
result_new=pd.read_sql(sql,conn)
result_new.head()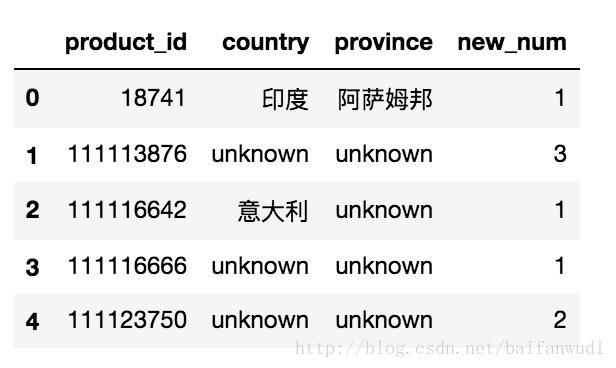
#统计历史所有新增
sql="select product_id,country_zh as country,province_zh as province,count(distinct device_id) as total_num from iot_register.device_info where create_time <='2017-08-17 23:59:59' group by product_id,country_zh,province_zh"
result_total=pd.read_sql(sql,conn)
result_total.head(10)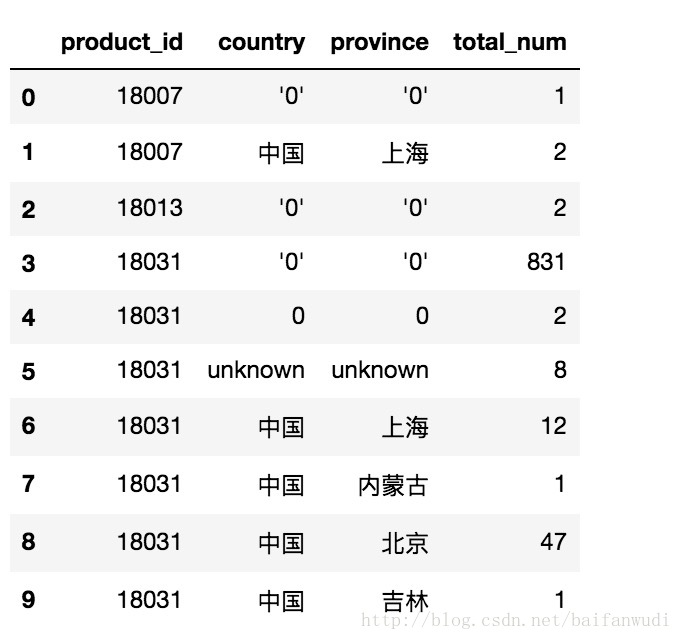
合并结果
result_merge=pd.merge(result_new,result_total,how='outer',on=['product_id','country','province'])
#将Nan值添补为0
result_without_na=result_merge.fillna(value={'new_num':0,"total_num":0})
#增加时间列
result_without_na['pt']='2017-08-17'
result_without_na.head()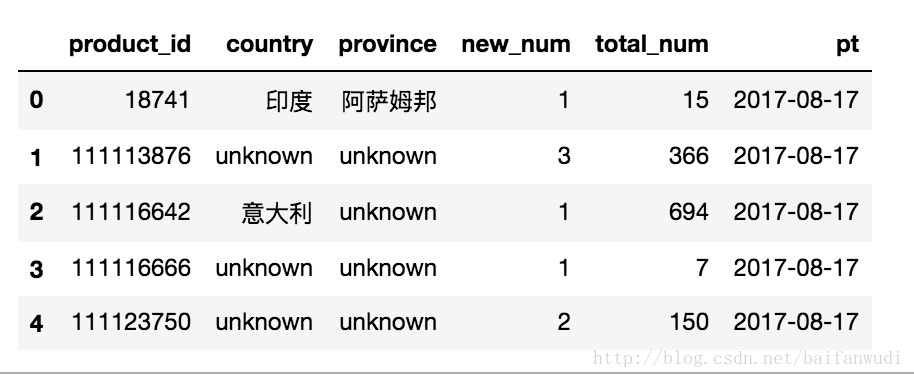
最后方法抽象,最后完整版
sql_config.py
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import pandas as pd
from sqlalchemy import create_engine
class SQLConfig(object):
def __init__(self):
self.ip = 'xxx.xx.xx.xxx'
self.port = '3306'
self.database = 'iot'
self.username = 'username'
self.password = 'password'
self.line = "mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8" % (self.username, self.password, self.ip, self.port, self.database)
self.engine = self.__get_engine()
self.table=None
self.dataframe=None
def __get_engine(self):
return create_engine(self.line)
def execute(self,*args,**kwargs):
pass
def delete_result(self, pt):
print "delete table:"+self.table+" in day("+pt+") 's data!"
self.engine.execute("delete from {tablename} where pt='{date}'".format(tablename=self.table,date=pt))
def save_result(self, *args,**kwargs):
pd.io.sql.to_sql(self.dataframe, self.table, con=self.engine, if_exists="append",index=False, chunksize=10000)
def run_all(self,*args,**kwargs):
self.execute(*args,**kwargs)
self.delete_result(*args,**kwargs)
self.save_result(*args,**kwargs)
if __name__ == '__main__':
a = SQLConfig()
print(a.line)
stats_device_area.py
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import sys
import datetime
import pandas as pd
from sql_config import SQLConfig
class DeviceArea(SQLConfig):
def __init__(self):
super(DeviceArea,self).__init__()
self.table='stats_device_area'
def execute(self,pt):
sql_new = "select product_id,country_zh as country,province_zh as province,count(*) as new_num from " \
" iot_register.device_info where create_time between '{date} 00:00:00' and '{date} 23:59:59' " \
"group by product_id,country,province".format(date=pt)
print(sql_new)
device_new = pd.read_sql(sql_new, con=self.engine)
sql_total = "select product_id,country_zh as country,province_zh as province,count(*) as total_num from" \
" iot_register.device_info where create_time <='{date} 23:59:59' group by product_id,country_zh,province_zh".format(date=pt)
print(sql_total)
device_total = pd.read_sql(sql_total, con=self.engine)
result_merge = pd.merge(device_new, device_total, how='outer', on=['product_id', 'country', 'province'])
result_fill_na = result_merge.fillna(value={'new_num': 0, "total_num": 0})
result_fill_na['pt'] = pt
self.dataframe = result_fill_na
if __name__ == '__main__':
if (len(sys.argv) < 2):
print '自动生成昨天天时间,时间格式为%Y-%m-%d'
yesterday = datetime.datetime.now() + datetime.timedelta(days=-1)
pt = yesterday.strftime('%Y-%m-%d')
else:
pt = sys.argv[1]
print '执行特定时间任务:' + pt
t = DeviceArea()
t.run_all(pt)大致流程:
生成所需要的dataframe结果,从数据库中删除那天的结果数据,将dataframe插入数据库.