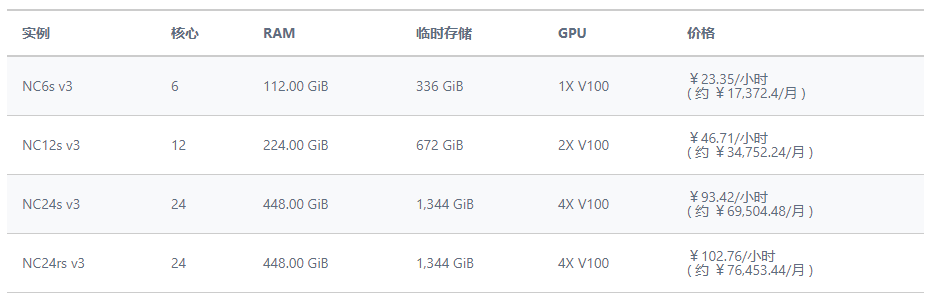
中国Azure两个新数据中心(分别位于两个新区域:中国东部 2 和中国北部 2)现已正式商用,在新数据中心中新增加了NCsv3 系列虚拟机,该系列虚拟机是 GPU 产品系列的新成员,装配了 NVIDIA Tesla V100 GPU。客户可将这些最新的 GPU 用于加速大数据分析与科学计算、VDI等其他高性能用途。该系列虚拟机提供 InfiniBand 网络的配置,以加快横向扩展功能并提升单个实例性能。具体的实例配置如下图:
下面将针对该系列VM进行部分深度学习应用场景下性能测试,并与CPU计算进行对比。
一、Openpose人体关键点检测性能测试
1. 测试环境
GPU机型:中国北部2,标准 NC6s_v3 (6 vcpu,112 GB 内存,1 X NVIDIA Tesla V100 16G PCI-E)
CPU机型:中国北部1,标准 DS4 v2 (8 vcpu,28 GB 内存)
OS: Ubuntu 18.04
Caffe:1.0.0
OpenCV:3.2.0
Boost:1.65
GPU机型的驱动版本:NVIDIA Driver 390.48,CUDA 9.0,cuDNN v7.0.5
CPU机型安装了Intel® Math Kernel Library (Intel® MKL) ,版本为2018.3.222
2. 测试内容
该测试使用了Openpose v1.3自带的Demo,对长度为6秒的avi格式sample视频进行关键点识别,对比GPU与CPU完成识别的耗时。
运行时命令和参数如下(分别为:仅身体,身体+脸,身体+手,身体+脸+手,四项测试):
# 仅身体
./build/examples/openpose/openpose.bin --video examples/media/video.avi --display 0 --render_pose 0 --write_video results/non.avi
# 身体+脸
./build/examples/openpose/openpose.bin --video examples/media/video.avi --face --display 0 --write_video results/face.avi
# 身体+手
./build/examples/openpose/openpose.bin --video examples/media/video.avi --hand --display 0 --write_video results/hand.avi
# 身体+脸+手
./build/examples/openpose/openpose.bin --video examples/media/video.avi --face --hand --display 0 --write_video results/face_hand.avi
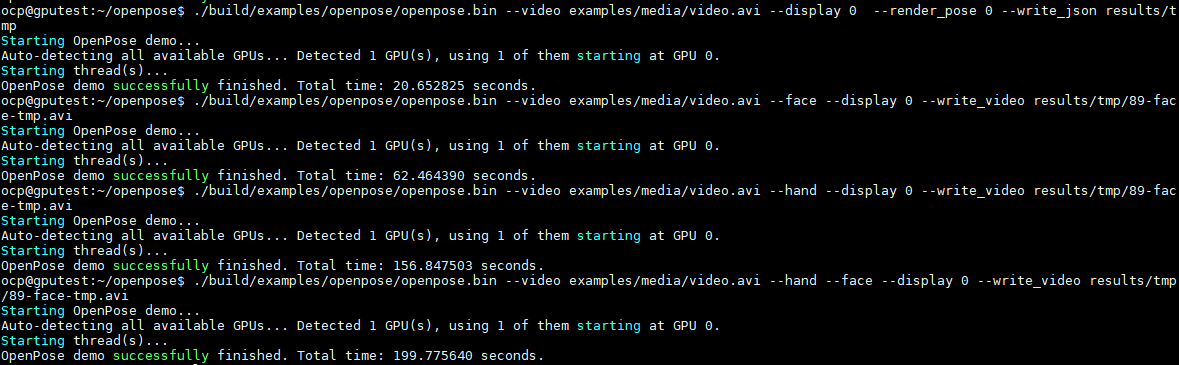
测试计时采用程序自带的时间统计,基于GPU的机型测试结果输出如下:
基于CPU的机型测试结果输出如下(由于耗时较长,部分结果输出到文件中查看):




测试完成输出的人体关键点识别结果样例截图:

3. 性能统计
在OpenPose部分性能测试结果统计如下表(耗时单位为秒):

由于Openpose测试时只能利用CPU的1个核心,没有充分发挥CPU的性能,因此还标注了理想情况下(CPU6核全利用)的性能提升倍数。可以看出GPU对性能的提升为数数十倍甚至上百倍,十分可观。
二、ResNet训练性能测试
在该项测试中使用了中国北部2,Azure标准 NC6s_v3 (6 vcpu,112 GB 内存,1 X NVIDIA Tesla V100 16G PCI-E)虚拟机,通过启用和禁用GPU加速来对比有无GPU的训练速度性能。软件环境具体如下:
OS: Ubuntu 18.04
NVIDIA Driver 390.48,CUDA 9.0,cuDNN v7.0.5
Python: Anaconda3-5.2.0-Linux-x86_64 (Python 3.6.5)
Pytorch 0.4.0
测试使用了3D-ResNets-PyTorch(链接:https://github.com/kenshohara/3D-ResNets-PyTorch),使用的模型为ResNet-34(CPU和GPU版本),数据集为UCF101(链接:http://crcv.ucf.edu/data/UCF101.php),进行行为识别的模型训练,可以识别视频中如跳水、骑马、理发、打字等行为。
1. 通过GPU训练
训练时使用的命令为:
ocp@gputest:~/3D-ResNets-PyTorch$ python main.py --root_path ~/3D-ResNets-PyTorch --video_path ucf101/jpg --annotation_path ucf101/anno/ucf101_01.json --result_path results --dataset ucf101 --n_classes 400 --n_finetune_classes 101 --pretrain_path models/resnet-34-kinetics.pth --ft_begin_index 4 --model resnet --model_depth 34 --resnet_shortcut A --batch_size 64 --n_threads 4 --checkpoint 5
训练时部分输出如下:

2. 通过CPU训练
训练时使用的命令为(禁用了CUDA,使用CPU的预训练模型):
ocp@gputest:~/3D-ResNets-PyTorch$ python main.py --root_path ~/3D-ResNets-PyTorch --video_path ucf101/jpg --annotation_path ucf101/anno/ucf101_01.json --result_path restmp --dataset ucf101 --n_classes 400 --n_finetune_classes 101 --pretrain_path models/resnet-34-kinetics-cpu.pth --ft_begin_index 4 --model resnet --model_depth 34 --resnet_shortcut A --batch_size 64 --n_threads 4 --checkpoint 5 --no_cuda
训练时部分输出如下:
3. 性能统计
在ResNet训练部分性能测试结果统计如下表,统计了Epoch 1的总耗时,Batch平均耗时,Validation耗时:

可以从结果中看出,在第一个Epoch中,GPU对训练速度的提升约为50倍,对验证速度的提升约为15倍,效果显著。
三、总结
从以上测试结果可以看出,GPU计算耗时相对CPU缩短数十倍,使用GPU可将数小时的计算耗时缩短到分钟级别。因此合理利用Azure新数据提供的GPU资源可以显著提升数据分析和处理的效率,缩短耗时,节约成本。
最后感谢Microsoft MTC的Guojun Zhang, Qi Gu, Zhixin Meng的帮助和支持