软件测试的最关键问题
- 软件测试中最重要的因素是设计和生成有效的测试用例
- 软件测试不论进行的多么具有创造性,多么完全,也不能保证软件中不存在任何错误
- 完全的软件测试是不可能的,对任何程序的测试必定是不完全的
- 测试策略:努力使测试尽可能完全
- 所以出于对时间和成本的约束,软件测试的最关键问题是:在所有可能的测试用例中,哪个子集最有可能发现最多的错误?
测试用例的设计
白盒测试
- 关注点:测试用例的执行程度 && 覆盖程序逻辑结构(源代码)的程度
- 完全的白盒测试:将程序中的每条路径都执行一遍。显然对于一个非常多层的循环程序,那么要想将程序中的每条路径都执行一遍,是非常不切实际的
- 下面的测试用例的设计方法我们将以下面这个例子举例:
public void foo(int a, int b, int x)
{
if(A > 1 && B == 0)
X = X / A;
if(A == 2 || X > 1)
X = X + 1;
}
- 为了更清楚的看到这个程序的执行路径,我们用程序框图来表示这个程序,如下图所示:
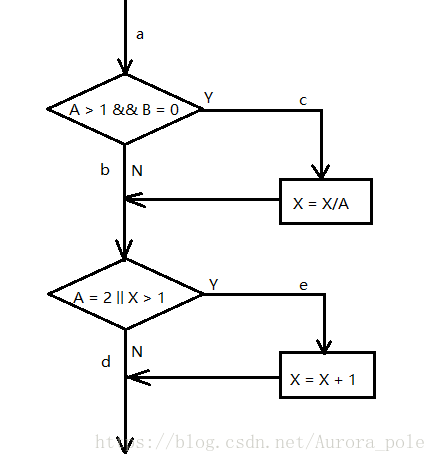
- 此程序涵盖了路径:acd、abe、abd、ace
语句覆盖
- 要求编写测试用例,使得每条语句被执行一次
- 通常语句覆盖没有多大的作用
判定覆盖(分支覆盖)
- 要求必须编写足够的测试用例,使得每一个判断都至少有一个为真和为假的输出结果(即每条分支路径都必须遍历一次)
- 分支或判定语句的例子包括:switch、do-while 和 if-else 语句
- 判定覆盖通常可以满足语句覆盖。一般情况下,若每条分支路径都被执行到了,那么每条语句也应该执行到了
- 例外情况:
- 程序中不存在判断
- 程序有着多重入口点,只有从程序的特定入口点进入时,某条特定的语句才能被执行到
- 判定覆盖要求每个判断都要有”是”或”否”的结果。但是若是多重选择的判断,判定/分支覆盖准则将所有判断的每个可能结果都至少执行一遍,以及将程序或子程序的每个入口点都至少执行一次
- 如上所示程序,若我们选择 acd、abe 路径,则满足判定覆盖的条件,即每个判断都有”是”或”否”的结果,针对这两条路径,设计连个测试用例输入是:
A = 3, B = 0, X = 3
A = 2, B = 1, X = 1
- 判定覆盖比语句覆盖好,但是有不足,若我们的判断条件写错(例如第二个判断,将 X > 1 写成 X < 1),上面的测试用例并不能发现错误
条件覆盖
- 要求编写足够的测试用例以确保将判断中的每个条件的所有可能结果至少执行一次
- 上例中,共有四个条件:
A > 1 , B = 0 , A = 2 , X > 1
A > 1, A <= 1, B = 0, B <> 0
A = 2, A <> 2, X > 1, X <= 1
A = 2, B = 0, X = 4 (ace)
A = 1, B = 1, X = 1 (abd)
- 条件覆盖要强于判定覆盖,因为条件覆盖可能会使每个条件各取到”真”和”假”的结果,判定覆盖做不到这一点
- 通常条件覆盖都会满足判定覆盖准则,但并不总是如此,比如说输入下面两个测试用例:
A = 1,B = 0, X = 3
A = 2,B = 1, X = 1
- 虽然涵盖了全部的条件结果,但是只涵盖了四个判断结果中的两个(abe),因而不会执行第一个判断的”真”,第二个判断的”假”
判定/条件覆盖
- 要求设计出充足的测试用例,讲一个判断中的每个条件的所有可能的结果至少执行一次,将每个判断的所有可能的结果至少执行一次,每个入口点都至少调用一次
- 缺点:尽管看上去所有的条件的所有结果似乎都执行到了,但是由于有些特定的条件会屏蔽掉其他条件,常常不能全部都执行
- 比如说,”与”条件表达式若第一个条件为假,则不会去执行第二个条件;”或”条件表达式若第一个条件为真,则后面的条件不会去执行
多重条件覆盖
- 要求编写足够的测试用例,将每个判定中的所有可能的条件的组合,以及所有的入口点都至少执行一次
- 通常满足多重条件的测试用例集,同样满足判定覆盖准则、条件覆盖准则以及判定/条件覆盖准则
- 针对上例,根据多重条件覆盖准则,测试用例必须覆盖以下 8 种组合:
1.A > 1, B = 0 2.A > 1, B <> 0
3.A <= 1, B = 0 4.A <= 1, B <> 0
5.A = 2, X > 1 6.A = 2, X <= 1
7.A <> 2, X > 1 8.A <> 2, X <= 1
A = 2, B = 0, X = 4 覆盖组合 1,5
A = 2, B = 1, X = 1 覆盖组合 2,6
A = 1, B = 0, X = 2 覆盖组合 3,7
A = 1, B = 1, X = 1 覆盖组合 4,8
黑盒测试
等价类划分
- 有效等价类:代表对程序有效的输入
- 无效等价类:代表其他任何可能的输入条件(即不正确的输入值),无效等价类的划分使得我们的测试用例可以注意到无效和为预料到的输入情况
- 我们可以使用一下的表格进行划分:
| 输入条件 |
有效等价类 |
无效等价类 |
| 数量是1-999 |
1<数量<999 |
数量<1,数量>999 |
| 标识符的第一个字符必须是字母 |
首字符是字母 |
首字符不是字母 |
| 汽车可登记一至六名车主 |
1<车主<6 |
没有车主、车主多于六个 |
| …… |
…… |
…… |
边界条件
- 考虑了边界条件的测试用例比起没有考虑的测试用例具有更高的测试回报率
- 边界条件:指输入和输出等价类中那些恰好处于边界、或超过边界、或在边界一下的状态,通常是等价类的补充
- 边界值分析法与等价划分法存在两方面的不同:
- 边界值分析需要选择一个或多个元素一遍等价类的每个边界都经过测试;而等加划分法是从等价类中挑选任意一个元素做代表
- 与仅仅关注输入条件不同,还需要考虑从输出等价设计测试用例
- 举例说明:
| 等价类 |
边界值 |
| 【1,50】 |
0、1、50、51 |
| 【1,50) |
0、1、49、50 |
| (1,50】 |
1、2、50、51 |
| (1,50) |
1、2、49、50 |
因果图分析
- 边界值分析和等价划分的一个弱点是:为对输入条件的组合进行分析。
- 因果图有助于用一个系统的方法选择出高效的测试用例集。它还有一个额外的好处,可以指出规格说明的不完整性和不明确之处
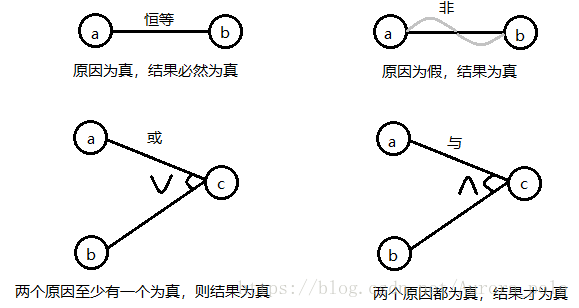
- 因果图是一种形式语言,用自然语言描述的规格说明可以转换为因果图,我们需要了解的是布尔逻辑(”与”、”或”、”非”)
- 因果图的基本符号如下图所示:
- 举例说明,考虑下面的规格说明:
第一列中的字符必须是“A”或“B”,第二列中的字符必须是一个数字
在这种条件下,对文件进行更新
如果第一个字符不正确,产生提示信息X12
如果第二个字符不正确,产生提示信息X13
- “因”如下:
- 1——第一列字符为”A”
- 2——第二列字符为”B”
- 3——第二列的字符为一个数字
- “果”如下:
- 70——对文件做了更新
- 71——产生提示信息X12
- 72——产生提示信息X13
- 因果图如下所示:

- 尽管上图的因果图代表了规格说明,但是图中包含了一个不可能的原因组合,即原因 1 和原因 2 不可能同时设置为1,这在程序中是常常可能出现的,所以为了表示出这种约束,我们采用如下图所示的符号:
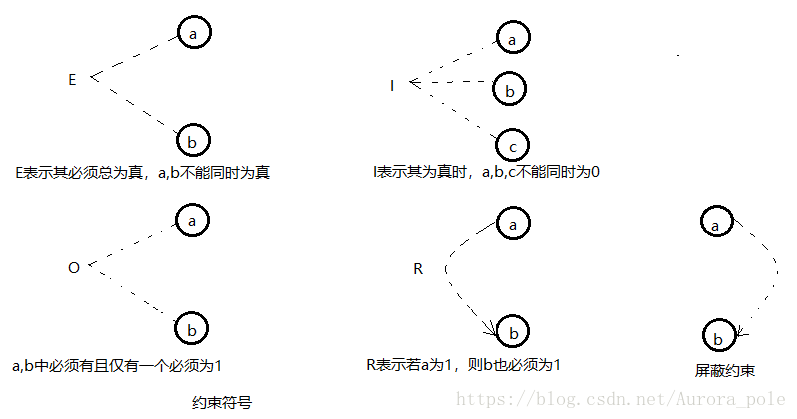 、
、
- 有了这些约束条件,我们就可以对我们的因果图做以修改,让它说明原因 1 和原因 2 不可能同时为1,如下图所示:
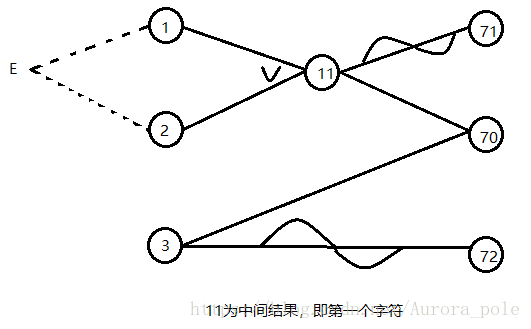
错误猜测
- 错误猜测是一项依赖于直觉的非正规过程,因此很难描述出这种方法的规程
- 依靠直觉和测试专家的经验来定位程序可能出错的地方,并由此设计出更高效的测试用例
- 基本思想1:列举出可能犯的错误或错误易发情况的清单,然后根据清单来编写测试用例
- 基本思想2:在阅读规格说明时练习程序员可能做的假设来确定测试用例(即规格说明中的一些内容会被忽略,要么是偶然因素,要么是程序员认为显而易见)
- 可以通过错误猜测来增加更多的测试用例
测试策略
上面的每一种方法都可以提供一组具体的有用的测试用例,但是都不能单独提供一个完整的测试用例集。一组合理的策略如下:
- 若规格说明中包含输入条件组合的情况,则应首先使用因果图分析法
- 在任何情况下都应该使用边界值分析法,这是对输入输出边界进行分析,边界值分析可以产生一系列补充的测试条件,但多数条件可以被整合到因果图分析中
- 应为输入输出确定有效和无效等价类,必要情况下对上面确认的测试用例进行补充
- 使用错误猜测技术(依靠直觉和经验)增加更多的测试用例
- 针对上述的测试用例检查程序的逻辑结构。应使用判定覆盖、条件覆盖、判定/条件覆盖或多重条件覆盖准则(最后一个最为完整),增加足够的测试用例使得覆盖准则得到满足