Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
jsoup 的主要功能如下:
1. 从一个 URL,文件或字符串中解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找、取出数据;
3. 可操作 HTML 元素、属性、文本;
jsoup 是基于 MIT 协议发布的,可放心使用于商业项目。
jsoup 可以从包括字符串、URL 地址以及本地文件来加载 HTML 文档,并生成 Document 对象实例。
Document
每个载入浏览器的 HTML 文档都会成为 Document 对象。
Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问。
提示:Document 对象是 Window 对象的一部分,可通过 window.document 属性对其进行访问。
Element
在 HTML DOM 中,Element 对象表示 HTML 元素。
文本节点Element 对象可以拥有类型为元素节点、、注释节点的子节点。
NodeList 对象表示节点列表,比如 HTML 元素的子节点集合。
元素也可以拥有属性。属性是属性节点。
Node
在 HTML DOM (文档对象模型)中,每个部分都是节点:
文档本身是文档节点
所有 HTML 元素是元素节点
所有 HTML 属性是属性节点
HTML 元素内的文本是文本节点
注释是注释节点
代码:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*
* 苏宁易购 图片爬虫
*
* */
public class GetPic {
/**
* 获取所有的图片列表页面
* url:苏宁易购的首页网址
* return map<图片的种类,图片下载的父链接>
*
* */
public static Map<String,String> getAllPicPage(String url){
Map<String,String> map=new HashMap<>();
try {
Document document= Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0")
.header("Host","res.suning.cn")
.header("Accept-Encoding","gzip, deflate, br")
.get();
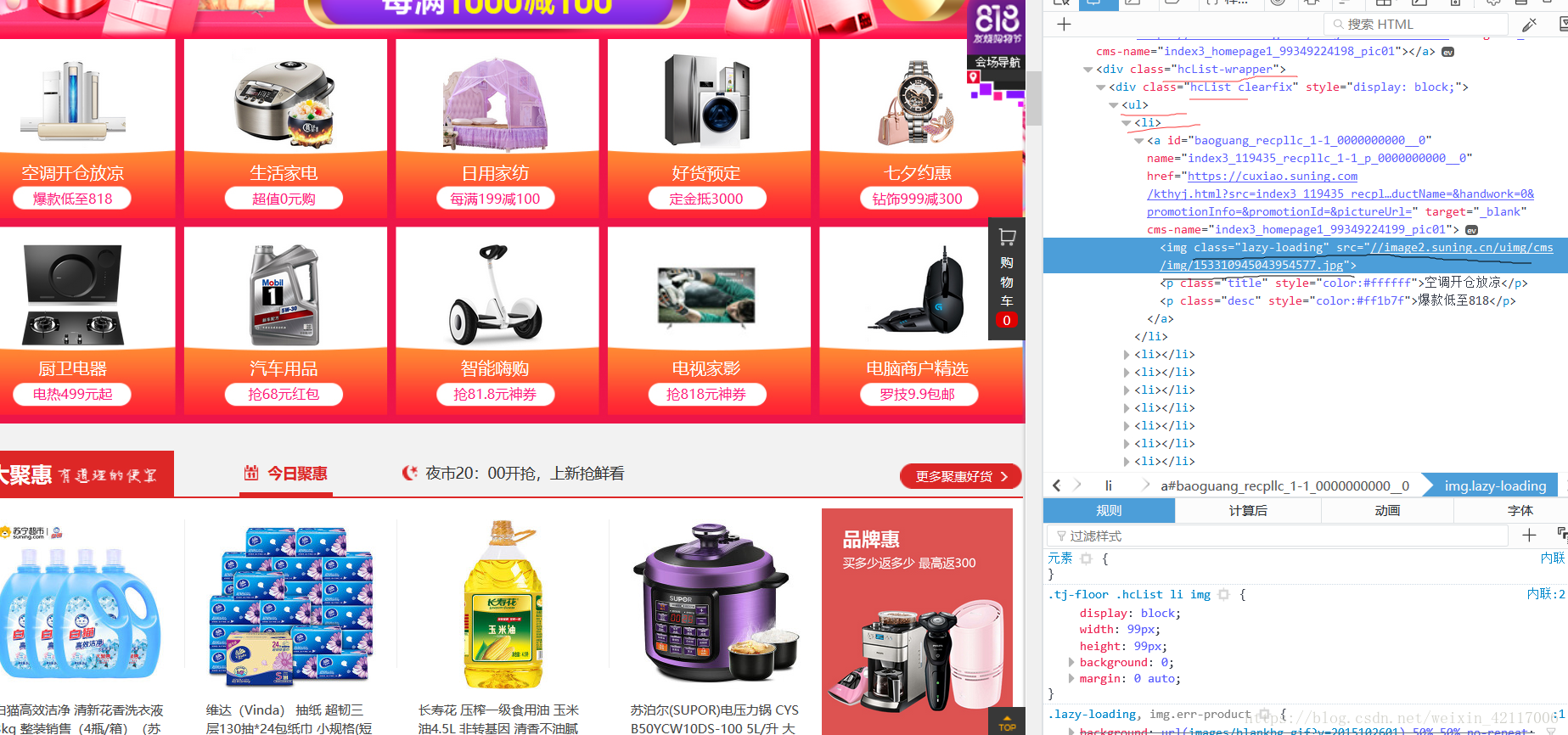
Elements elements= document.select(".hcList-wrapper")
.select(".hcList")
.select("ul")
.select("li").select("a");
for(Element element:elements){
String subUrl=element.attr("href");
System.out.println("href:"+subUrl);
System.out.println(element.text());
map.put(element.text(),subUrl);
}
} catch (IOException e) {
e.printStackTrace();
}
return map;
}
/**
* 获取所有的图片列表页面
* title :图片所属的种类
* url:图片下载的路径
* return list<图片种类-图片下载的路径>
* */
public static List<String> getAllPicPageFromOnePage(String title,String url){
List<String> list=new ArrayList<>();
try {
Document document= Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0")
.header("Accept-Encoding","gzip, deflate, br")
.header("Host","res.suning.cn")
.get();
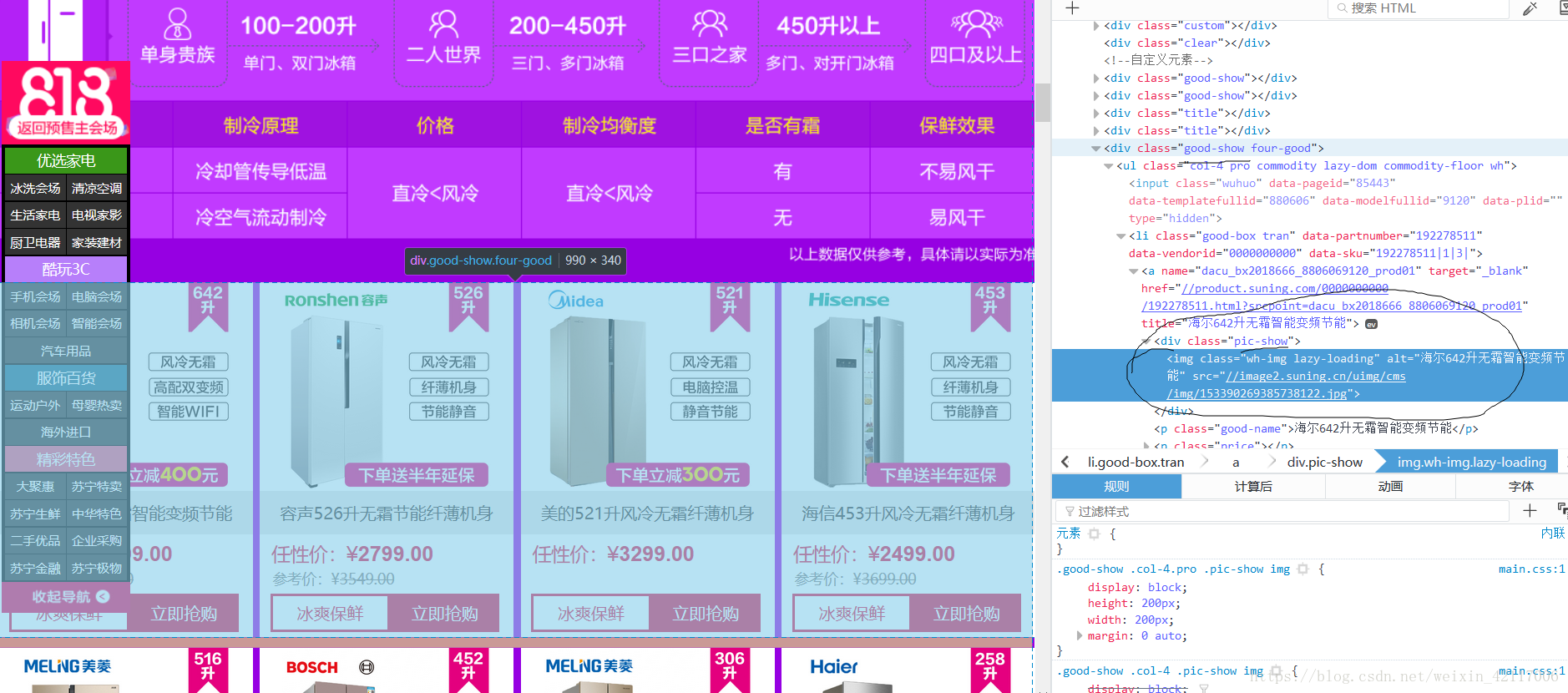
Elements elements= document.select(".good-show").select("div").select("a").select(".pic-show").select("img");
for(Element element:elements){
String src=title+"-"+element.attr("lazy-src");
System.out.println(src);
list.add(src);
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/**
* 下载图片指定的title目录上
* title :图片所属的种类
* fileName:图片名
* src:图片的下载路径
*
* */
public static void downloadPic(String title,String fileName,String src){
try {
URL url = new URL(src);
BufferedInputStream bis = new BufferedInputStream(url.openConnection().getInputStream());
byte myArray[] = new byte[1024*1024];
int len = 0;
File file=new File("E://images/" +title+"/");
if(!file.exists()){
file.mkdirs();
}
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("E://images/" +title+"/"+ fileName));
while((len = bis.read(myArray)) != -1){
bos.write(myArray, 0, len);
}
bos.flush();
bos.close();
bis.close();
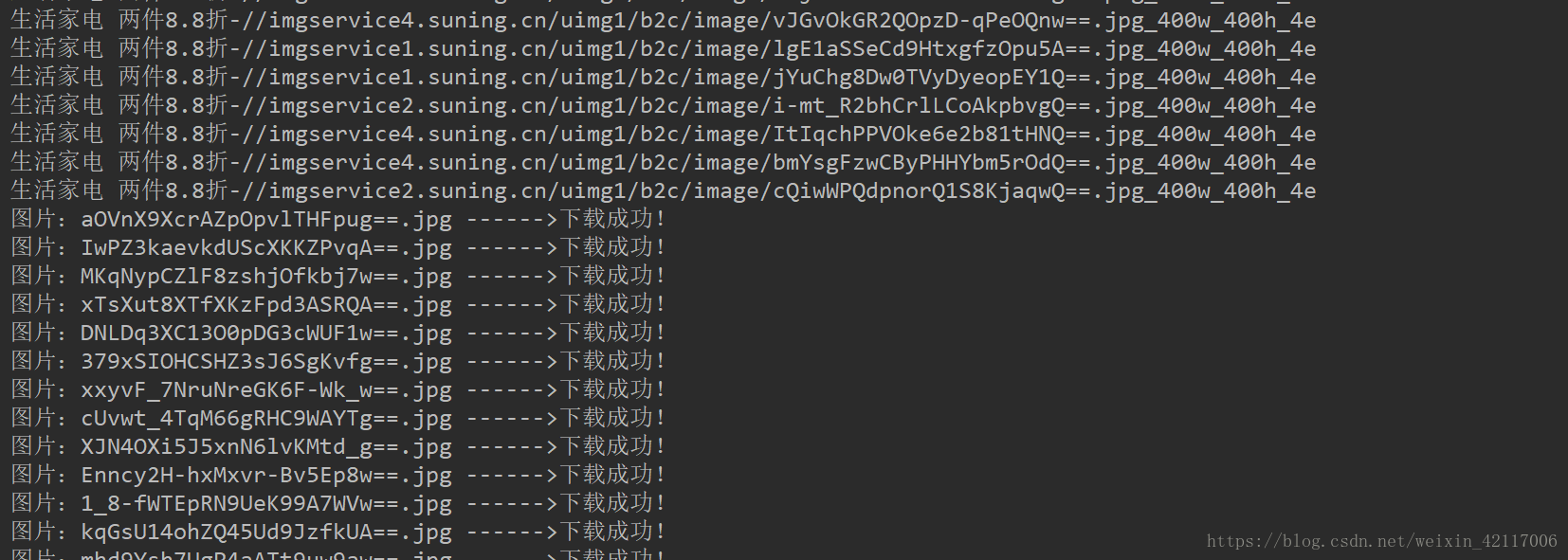
System.out.println("图片:" + fileName +" ------>下载成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
*
* 得到标题
* */
public static String getTitleFromUrl(String url){
int firstIndex= url.indexOf("-");
String title=url.substring(0,firstIndex);
return title;
}
/**
*
*得到图片的下载路径
* */
public static String getSrcFromUrl(String url){
int firstIndex= url.indexOf("-");
String src="http:"+url.substring(firstIndex+1);
return src;
}
/**
* 将图片下载地址进行切割,得到图片名
*
*
* */
public static String getNameFromUrl(String url){
//找到最后一个 "/" 的位置
int beginIndex = url.lastIndexOf("/");
//截取 "/" 后面的内容
String name = url.substring(beginIndex + 1);
//处理文件名
int index= name.lastIndexOf(".");
String subName= name.substring(index);
if(subName.contains("jpg") && subName.length()>3){
subName="jpg";
name=name.substring(0,index+1).concat(subName);
}
if(subName.contains("png") && subName.length()>3){
subName="png";
name=name.substring(0,index+1).concat(subName);
}
return name;
}
public static void downloadAll(){
Map<String,String> map= getAllPicPage("https://www.suning.com");
for(Map.Entry<String,String> entry:map.entrySet()){
List<String> list= getAllPicPageFromOnePage(entry.getKey(),entry.getValue());
for(String url:list){
String title=getTitleFromUrl(url);
String fileName=getNameFromUrl(url);
String src=getSrcFromUrl(url);
downloadPic(title,fileName,src);
}
}
}
public static void main(String[] args){
downloadAll();
}
}
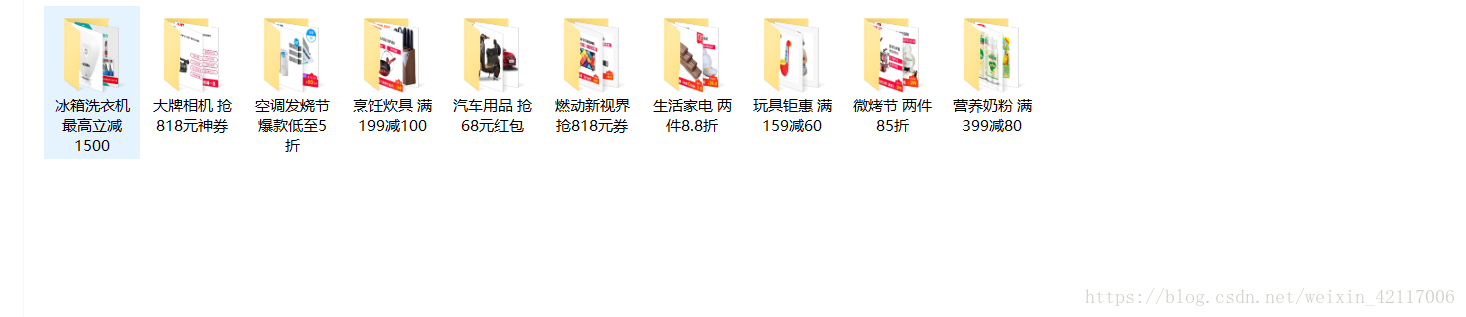
这是本人初学Jsoup 写的代码,如果有什么不足的地方,可以评论交流