import numpy as np
import pandas as pdSeries
Series 1、是一种类似于一维数组的对象,组成: 一组数据(各种NumPy数据类型) 一组与之对应的索引(数据标签) 索引(index)在左,数据(values)在右 索引是自动创建的。
示例:
ser_obj = pd.Series(range(10,30))
print(ser_obj)
print(ser_obj.head(3))
print(type(ser_obj))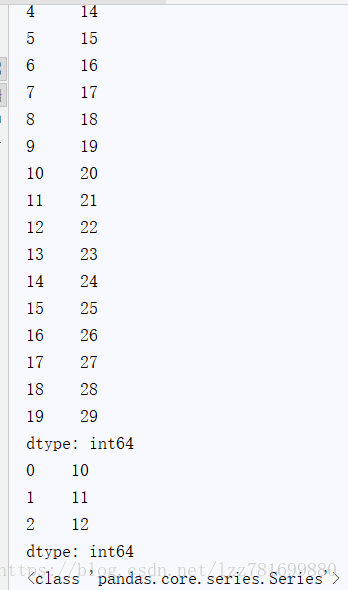
Series 2、 通过dict构建Series
范例
dict = {1000:"hello",2000:"world",3000:"!"}
ser_obj = pd.Series(dict)
print(ser_obj)

DataFrame
一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,数据是以二维结构存放的。 类似多维数组/表格数据 (如,excel, R中的data.frame) 每列数据可以是不同的类型 索引包括列索引和行索引
1,示例:
1、通过list构建Series
ser_obj = pd.Series(range(10,30))
不指定索引的话,默认从0开始
范例
print(ser_obj)
print(ser_obj.head(3)) #打印前三行数据
print(type(ser_obj)) #打印数据类型

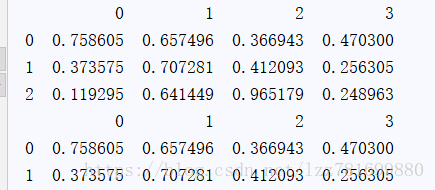
DtataFrame 1. 通过ndarray构建DataFrame
范例
arr_obj = np.random.rand(3,4)
df_obj = pd.DataFrame(arr_obj)
print(df_obj)
print(df_obj.head(2)) #看前两行
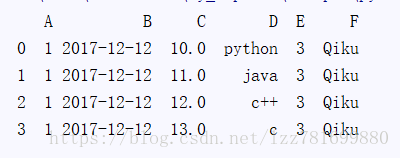
2. 通过dict构建DataFrame 范例
dict = {
"A":1,
"B":pd.Timestamp("20171212"),
"C":pd.Series(range(10,14),dtype="float64"),
"D":["python","java","c++","c"],
"E":np.array([3] *4,dtype="int32"),
"F":"Qiku" }
df_obj = pd.DataFrame(dict)
print(df_obj)