摘要: 本文是一篇pandas/networkx图分析入门,对所举的欺诈检测用例进行了简单的图论分析,便于可视化及操作。
对于图论而言,大家或多或少有些了解,数学专业或计算机相关专业的读者可能对其更加清楚。图论中的图像是由若干给定的点及连接两点的线所构成的图形,这样的图像通常用来描述某些事物之间的某种特定关系,用点代表事物,用两点之间的连接线表示二者具有的某种关系,在互联网与通信行业中应用广泛。图论分析(Graph analysis)并不是数据科学领域中的新分支,也不是数据科学家目前应用的常用首选方法。然而,图论可以做一些疯狂的事情,一些经典用例包括欺诈检测、推荐或社交网络分析等,下图是 NLP中的非经典用例——处理主题提取。
欺诈检测用例
假设现在你有一个客户数据库,并想知道它们是如何相互连接的。特别是,你知道有些客户涉及复杂的欺诈结构,但是在个人层面上可视化数据并不会带来欺诈证据,欺诈者看起来像其他普通客户一样。
只需查看原始数据,处理用户之间的连接就可以显示更多信息。具体而言,对于通常的基于机器学习的评分模型而言,这些特征不会被视为风险,但这些不会被认为存在风险的特征可能成为基于图表分析评分模型中的风险特征。
示例:三个具有相同电话号码的人,连接到具有相同电子邮件地址的其他人,这是不正常的,且可能存在风险。电话号码本身没有什么价值,并不会提供任何信息(因此,即使最好的深度学习模型也不能从中获取任何价值信息),但个人通过相同的电话号码或电子邮件地址连接这一问题,可能是一种风险。
下面在Python中进行一些处理:
设置数据、清理和创建图表
(构造的仿真数据)
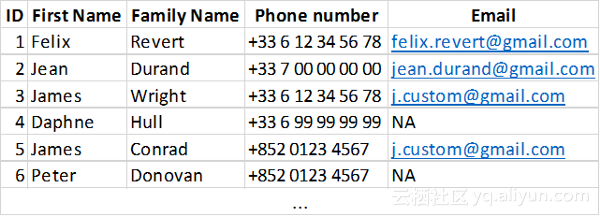
首先从一个pandas DataFrame开始(它基本上是Python中的Excel表)
import pandas as pd
df = pd.DataFrame({'ID':[1,2,3,4,5,6],
'First Name':['Felix', 'Jean', 'James', 'Daphne', 'James', 'Peter'],
'Family Name': ['Revert', 'Durand', 'Wright', 'Hull', 'Conrad', 'Donovan'],
'Phone number': ['+33 6 12 34 56 78',
'+33 7 00 00 00 00', '+33 6 12 34 56 78', '+33 6 99 99 99 99', '+852 0123 4567', '+852 0123 4567'],
'Email': ['[email protected]', '[email protected]', '[email protected]',
pd.np.nan, '[email protected]', pd.np.nan]})从代码中看到,先加载数据,以df表示。下面对其做一些准备,需要连接具有相同电话号码和相同电子邮件的个人(由其ID表示)。首先从电话号码开始:
column_edge = 'Phone number'
column_ID = 'ID'
data_to_merge = df[[column_ID, column_edge]].dropna(subset=[column_edge]).
drop_duplicates() # select columns, remove NaN
# To create connections between people who have the same number,
# join data with itself on the 'ID' column.
data_to_merge = data_to_merge.merge(
data_to_merge[[column_ID, column_edge]].rename(columns={column_ID:column_ID+"_2"}),
on=column_edge
)处理的数据看起来像这样:
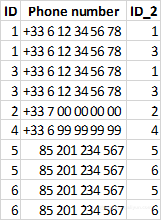
从图中看到,里面有一些联系,但存在两个问题:
- 个人与自己联系在一起
- 从数据中看到,当X与Y连接时,Y也与X连接,有两行数据用于同一连接。下面让我们清理一下:
# By joining the data with itself, people will have a connection with themselves.
# Remove self connections, to keep only connected people who are different.
d = data_to_merge[~(data_to_merge[column_ID]==data_to_merge[column_ID+"_2"])] \
.dropna()[[column_ID, column_ID+"_2", column_edge]]
# To avoid counting twice the connections (person 1 connected to person 2 and person 2 connected to person 1)
# we force the first ID to be "lower" then ID_2
d.drop(d.loc[d[column_ID+"_2"]<d[column_ID]].index.tolist(), inplace=True)下面,数据看起来像这样:
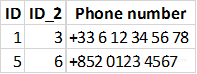
从图中看到,1和3连接,5和6也连接。我们对电子邮件地址也进行同样的处理。下面构建一个图表,将在这里只分享代码的一部分,因为添加全部代码比较棘手,项目代码地址在文末给出。
import networkx as nx
G = nx.from_pandas_edgelist(df=d, source=column_ID, target=column_ID+'_2', edge_attr=column_edge)
G.add_nodes_from(nodes_for_adding=df.ID.tolist())下面进行数据可视化
使用networkx进行图形可视化
简单的nx.draw(G)代码就能获得以下内容:
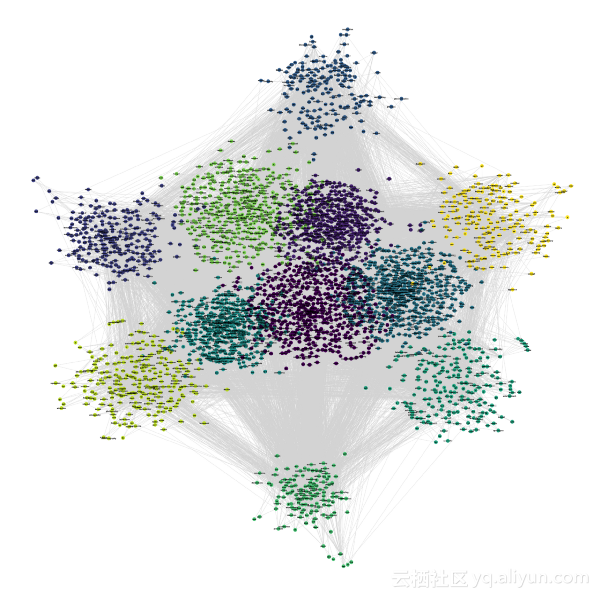
从图中看到,这是一个相当有趣的形式!但是我们看不出图中的每个点代表的是谁,谁和谁之间有什么连接。下面将其具体化:

从图中可以看到, 4个人通过2个不同的电话号码和1个电子邮件地址连接在一起,后续还应该进行更多的调查!
真正实现工业化的下一步
让我们回顾一下我们前面做过的事情:
- 根据用户数据库创建图表
- 自定义可视化,帮助我们发现潜在奇怪的模式
如果你是业务驱动的,并希望一些专家使用你已经完成的工作,那么你的下一个重点应该是: - 将查找多个人连接在一起的这一过程自动化,或风险模式检测
- 通过图形可视化和原始数据自动创建可视化和创建自定义仪表板的过程
本文不会在这里详细介绍上述内容,但是会告诉你如何继续进行上述两个步骤:
1.风险模式检测
这里有两种方法:
- 从你认为有风险的人(或你被发现为欺诈者的人)那里开始,检查他们与其他人的关系。这与机器学习相关,这是一种“有监督”方法。更进一步,你还可以从机器学习评分(例如,使用XGBoost)开始,寻找他们之间存在的紧密联系。
- 从奇怪的模式(太多的连接、密集的网络...),这是“无监督”的方法。
在我们举的例子中,我们没有已知的欺诈者,所以我们将采用上述的第二种方法。
Networkx已经实现了完全正确的算法:degree( )、centrality( )、pagerank( )、connected_components( )......这些算法可以让你以数学的形式定义风险。
2.为业务创建可视化和自动化分析
对于大多数数据科学家来说,这内容听起来是老派,但快速做到这一点的方法就是使用Excel。
Xlsxwriter软件包可帮助你粘贴风险人物图表中的数据,并将我们创建的图表图像直接粘贴到Excel文件中。通过这种操作之后你将获得每个风险网络的仪表板,如下所示:
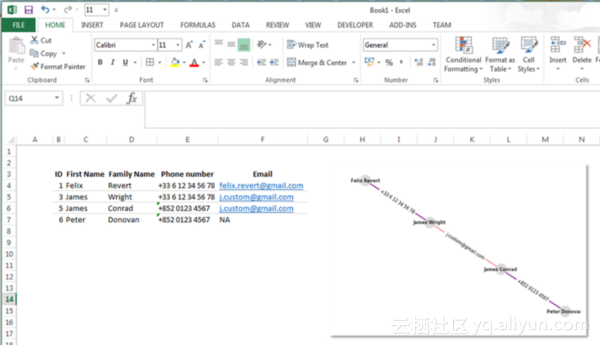
对于每个具有潜在风险的网络,你都可以自动地创建仪表板,让专家完成他们的工作。同样你也可以在信息中心中添加一些指标:涉及的人数、不同电话号码的数量及电子邮件地址等。
全文源码在此,希望这篇文章对你有所帮助。
本文为云栖社区原创内容,未经允许不得转载。