透视表pivot_table()
透视表pivot_table()是一种进行分组统计的函数,参数aggfunc决定统计类型。
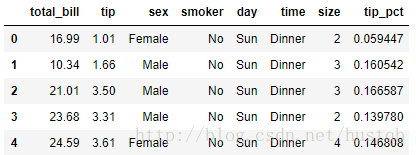
1、假设我想要根据sex和smoker计算分组平均数(pivot_table的默认聚合类型),并将sex和smoker放到行上:(因为day无法计算平均数,所以自动去除)
# 方法一:使用groupby
tips.groupby(['sex', 'smoker']).mean()
# 方法二:使用pivot_table
tips.pivot_table(row=['sex', 'smoker'])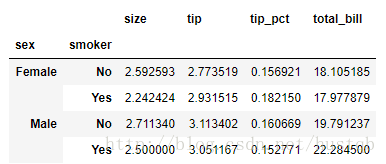
2、现在假设我们只想聚合tip_pct和size,而且想根据day进行分组。我将smoker放到列上,把day放到行上:
tips.pivot_table(values=['tip_pct', 'size'], index=['sex', 'day'], columns='smoker')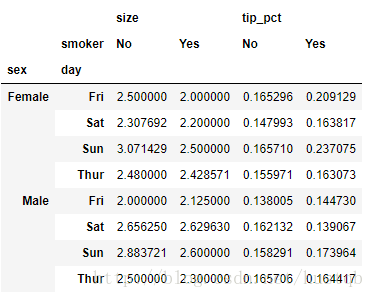
3、传入margins=True,添加加分小计
tips.pivot_table(values=['tip_pct', 'size'], index=['sex', 'day'], columns='smoker', margins=True)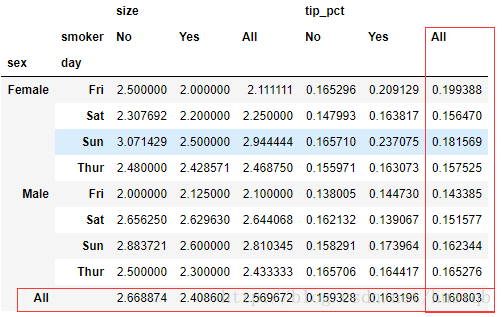
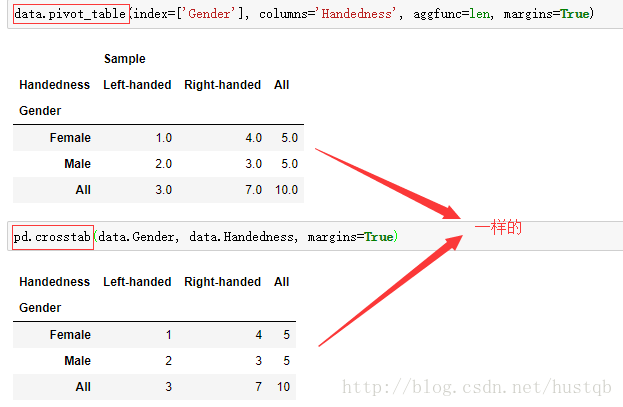
4、要使用其他的聚合函数,将其传给参数aggfunc即可。例如,使用count或len可以得到有关分组大小的交叉表:
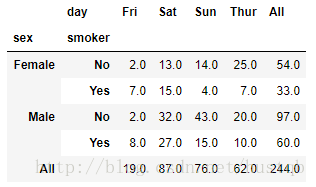
pivot_table()的参数
| 参数名 | 说明 |
|---|---|
| values | 待聚合的列的名称 |
| rows | 透视表的行 |
| cols | 透视表的列 |
| aggfunc | 聚合函数或函数列表 |
| fill_value | 用于替换缺失值 |
| margins | 添加行/列小计和总计 |
交叉表crosstab()
交叉表crosstab()是一种特殊的pivot_table(),专用于计算分组频率。
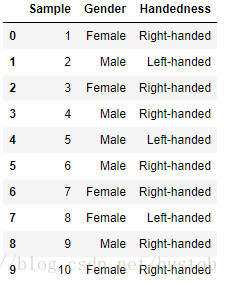
1、假设我们想要根据性别和用手习惯对这段数据进行统计汇总。虽然可以用pivot_table()实现该功能,但是pandas.crosstab()函数会更方便