用户空间和内核空间:操作系统采用虚拟存储器,对于32位系统而言,寻址空间为4G。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户不能直接操作内核,保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对Linux操作系统而言,将最高的1G分给内核,成为内核空间,较低的3G给应用程序,成为用户空间。
网络IO的本质是socket的读取,socket在linux系统中被抽象为流,IO可以理解为对流的操作.对于一次IO访问,数据会先被拷到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
阻塞I/O:通常我们使用的I/O都是阻塞式I/O,在编程时使用的大多数也是阻塞式I/O。在默认情况下,所有的套接字(socket)都是阻塞的。
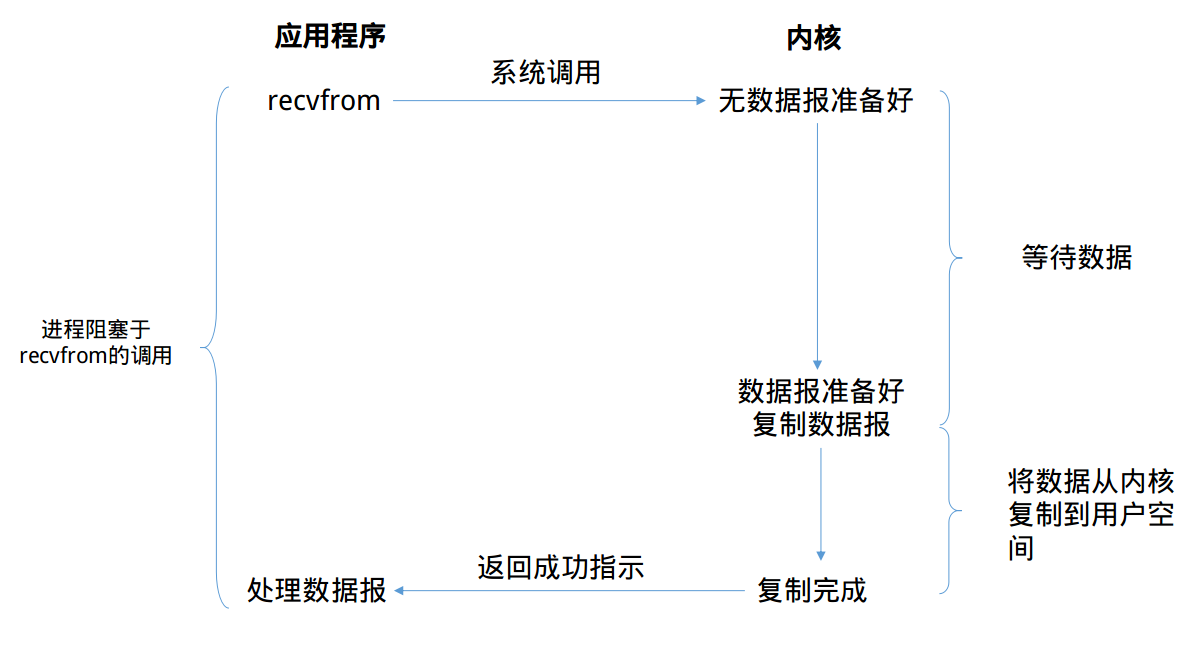
在这个IO模型中,用户空间的应用程序执行一个系统调用(recvform),这会导致应用程序阻塞,什么也不干,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络IO。在数据没到达的时候,应用程序等待数据到来——》把数据拷贝到操作系统内核的缓冲区中需要一个过程——》拷贝到用户内存,此时解除阻塞,重新运行该进程。
非阻塞I/O:同步非阻塞就是 “每隔一会儿瞄一眼进度条” 的轮询(polling)方式。在这种模型中,设备是以非阻塞的形式打开的。这意味着 IO 操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK)。
非阻塞的read调用之后,进程如果没有被阻塞,则内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再调用read。重复上面的过程,循环往复的进行read调用。这个过程称之为轮询。轮询检测内核数据,直到数据准备好,再拷贝到进程。但是拷贝数据进程的这个过程,还是阻塞的。
I/O多路复用: 由于同步非阻塞方式需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间,而 “后台” 可能有多个任务在同时进行,人们就想到了循环查询多个任务的完成状态,只要有任何一个任务完成,就去处理它。如果轮询不是进程的用户态,而是有人帮忙就好了。那么这就是所谓的 “IO 多路复用”。
当用户调用epoll之后,那么这个进程会被阻塞,此时epoll会等待内核事件表中的就绪文件描述符,等到socket中的数据准备好后,epoll_wait返回,此时进程调用read操作,当需要同时处理多个客户端接入请求时,I/O复用技术把多个I/O阻塞到同一个epoll上。
信号驱动I/O:信号驱动式I/O:首先我们允许Socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
