15.1. 磁盘配额 (Quota) 的应用与实作
Quota 就是有多少『限额』的意思!在 Linux 来说,就是有多少容量限制的意思。我们可以使用 quota 来让磁盘的容量使用较为公平!
15.1.1. 什么是 Quota:一般用途, 限制, 规范 (inode/block, soft/hard, grace time)
在 Linux 系统中,由于是多人多任务的环境,所以会有多人共同使用一个硬盘空间的情况发生, 如果其中有少数几个使用者大量的占掉了硬盘空间的话,那势必压缩其他使用者的使用权力! 因此管理员应该适当的限制硬盘的容量给用户,以妥善的分配系统资源!这个时候就得要靠 quota 的帮忙了!
一、Quota 的一般用途
quota 比较常使用的几个情况是:
- 针对 WWW server ,例如:每个人的网页空间的容量限制!
- 针对 mail server,例如:每个人的邮件空间限制。
- 针对 file server,例如:每个人最大的可用网络硬盘空间 (教学环境中最常见!)
上头讲的是针对网络服务的设计,如果是针对 Linux 系统主机上面的设定那么使用的方向有底下这一些:
- 限制某一群组所能使用的最大磁盘配额 (使用群组限制):
你可以将你的主机上的用户分门别类。 - 限制某一用户的最大磁盘配额 (使用用户限制):
在限制了群组之后,你也可以再继续针对个人来进行限制,使得同一群组之下还可以有更公平的分配! - 以 Link 的方式,来使邮件可以作为限制的配额 (更改 /var/spool/mail 这个路径):
如果是分为付费与免付费会员的『邮件主机系统』,不需要重新再规划一个硬盘!直接使用 Link 的方式指向 /home (或者其他已经做好的 quota 磁盘) 就可以! 这通常是用在原本磁盘分区的规划不好,但是却又不想要更动原有主机架构的情况中!
二、Quota 的使用限制
使用上还是有些限制要先了解的:
- 仅能针对整个 filesystem:
quota 实际在运作的时候,是针对『整个 filesystem』进行限制的, 例如:如果你的 /dev/sda5 是挂载在 /home 底下,那么在 /home 底下的所有目录都会受到限制! - 核心必须支持 quota :
Linux 核心必须有支持 quota 这个功能才行:如果你是使用 CentOS 5.x 的预设核心, 你的系统已经默认有支持 quota 这个功能!如果你是自行编译核心的, 那么请特别留意你是否已经『真的』开启了 quota 这个功能?否则底下的功夫将全部都视为『白工』。 - Quota 的记录文件:
目前新版的 Linux distributions 使用的是 Kernel 2.6.xx 的核心版本,这个核心版本支持新的 quota 模块,使用的默认档案 (aquota.user, aquota.group )将不同于旧版本的 quota.user, quota.group ! (多了一个 a !) 而由旧版本的 quota 可以藉由 convertquota 这个程序来转换! - 只对一般身份使用者有效:
并不是所有在 Linux 上面的账号都可以设定 quota ,例如 root 就不能设定 quota , 因为整个系统所有的数据几乎都是他的!
所以你不能针对『某个目录』来进行 Quota 的设计,但你可以针对『某个文件系统(filesystem) 』来设定。 如果不明白目录与挂载点还有文件系统的关系,请回到第八章去瞧瞧再回来!
三、Quota 的规范设定项目:
quota 对整个 filesystem 的限制项目主要分为底下几个部分:
容量限制或档案数量限制 (block 或 inode):
我们在第八章谈到文件系统中,说到文件系统主要规划为存放属性的 inode 与实际档案数据的 block 区块,Quota 既然是管理文件系统,所以当然也可以管理 inode 或 block ! 这两个管理的功能为:
o 限制 inode 用量:可以管理使用者可以建立的『档案数量』;
o 限制 block 用量:管理用户磁盘容量的限制,较常见为这种方式。柔性劝导与硬性规定 (soft/hard):
既然是规范,当然就有限制值。不管是 inode/block ,限制值都有两个,分别是 soft 与 hard。 通常 hard 限制值要比 soft 还要高。举例来说,若限制项目为 block ,可以限制 hard 为 500MBytes 而 soft 为 400MBytes。这两个限值的意义为:
o hard:
表示使用者的用量绝对不会超过这个限制值,以上面的设定为例, 用户所能使用的磁盘容量绝对不会超过 500Mbytes ,若超过这个值则系统会锁住该用户的磁盘使用权;
o soft:
表示使用者在低于 soft 限值时 (此例中为 400Mbytes),可以正常使用磁盘,但若超过 soft 且低于 hard 的限值 (介于 400~500Mbytes 之间时),每次用户登入系统时,系统会主动发出磁盘即将爆满的警告讯息, 且会给予一个宽限时间 (grace time)。不过,若使用者在宽限时间倒数期间就将容量再次降低于 soft 限值之下, 则宽限时间会停止。会倒数计时的宽限时间 (grace time):
这个宽限时间只有在用户的磁盘用量介于 soft 到 hard 之间时,才会出现! 由于达到 hard 限值时,用户的磁盘使用权可能会被锁住。为了担心用户没有注意到这个磁盘配额的问题, 因此设计了 soft 。当你的磁盘用量即将到达 hard 且超过 soft 时,系统会给予警告,但也会给一段时间让用户自行管理磁盘。 一般预设的宽限时间为七天,如果七天内你都不进行任何磁盘管理,那么 soft 限制方式会即刻改变为 hard 来作为 quota 的限制。
以上面设定的例子来说,假设你的容量高达 450MBytes 了,那七天的宽限时间就会开始倒数, 若七天内你都不进行任何删除档案的动作来替你的磁盘用量瘦身, 那么七天后你的磁盘最大用量将变成 400MBytes (那个 soft 的限制值),此时你的磁盘使用权就会被锁住而无法新增档案了。
整个 soft, hard, grace time 的相关性我们可以用底下的图示来说明:

图中的直方图为用户的磁盘容量,soft/hard 分别是限制值。只要小于 400M 就一切 OK , 若高于 soft 就出现 grace time 并倒数且等待使用者自行处理,若到达 hard 的限制值,就被锁定!
15.1.2. 一个 Quota 的实作范例
这里我们使用一个范例来设计一下如何处理 Quota 的设定流程:
1. 目的与账号:现在我想要让我的专题生五个为一组,这五个人的账号分别是 myquota1, myquota2, myquota3, myquota4, myquota5,这五个用户的密码都是 password ,且这五个用户所属的初始群组都是 myquotagrp 。 其他的账号属性则使用默认值。
2. 账号的磁盘容量限制值:我想让这五个用户都能够取得 300MBytes 的磁盘使用量(hard),档案数量则不予限制。 此外,只要容量使用率超过 250MBytes ,就予以警告 (soft)。
3. 群组的限额:由于我的系统里面还有其他用户存在,因此我仅承认 myquotagrp 这个群组最多仅能使用 1GBytes 的容量。 这也就是说,如果 myquota1, myquota2, myquota3 都用了 280MBytes 的容量了,那么其他两人最多只能使用 (1000MB - 280x3 = 160MB) 的磁盘容量!这就是使用者与群组同时设定时会产生的后果。
4. 宽限时间的限制:最后,我希望每个使用者在超过 soft 限制值之后,都还能够有 14 天的宽限时间。
Quota 设定方法:
首先,在这个小节我们先来将账号相关的属性与参数搞定!
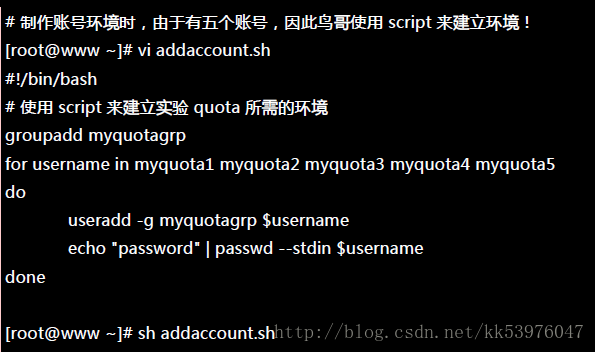
接下来,就让我们来实作 Quota 的练习吧!
15.1.3. 实作 Quota 流程-1:文件系统支援 (/etc/fstab, /etc/mtab)
前面我们就谈到,要使用 Quota 必须要核心与文件系统支持才行!假设你已经使用了预设支持 Quota 的核心, 那么接下来就是要启动文件系统的支持!不过,由于 Quota 仅针对整个文件系统来进行规划,所以我们得先查一下, /home 是否是个独立的 filesystem 呢?
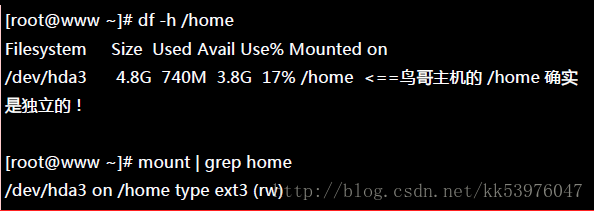
这部主机的 /home 确实是独立的 filesystem,因此可以直接限制 /dev/hda3 。 如果你的系统的 /home 并非独立的文件系统,那么可能就得要针对根目录 (/) 来规范了!不过,不太建议在根目录设定 Quota。 此外,由于 VFAT 文件系统并不支持 Linux Quota 功能,所以我们得要使用 mount 查询一下 /home 的文件系统为何? 看起来是 Linux 传统的 ext2/ext3 ,这种文件系统肯定有支援 Quota !
如果只是想要在这次开机中实验 Quota ,那么可以使用如下的方式来手动加入 quota 的支持:

事实上,当你重新挂载时,系统会同步更新 /etc/mtab 这个档案, 所以你必须要确定 /etc/mtab 已经加入 usrquota, grpquota 得支持到你所想要设定的文件系统中。 另外也要特别强调,使用者与群组的 quota 文件系统支持参数分别是:usrquota, grpquota !千万不要写错了!这一点非常多初接触 Quota 的朋友常常搞错。
不过手动挂载的数据在下次重新挂载就会消失,因此最好写入配置文件中!在这部主机的案例中, 我可以直接修改 /etc/fstab 成为底下这个样子:
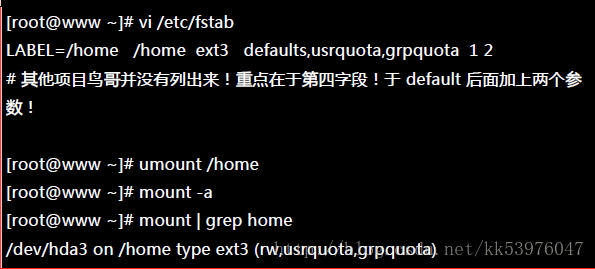
还是要再次的强调,修改完 /etc/fstab 后,务必要测试一下!若有发生错误得要赶紧处理! 因为这个档案如果修改错误,是会造成无法开机完全的情况!最好使用 vim 来修改! 因为会有语法的检验,就不会让你写错字了!启动文件系统的支持后,接下来让我们建立起 quota 的记录文件吧!
15.1.4. 实作 Quota 流程-2:建立 quota 记录文件 (quotacheck)
其实 Quota 是透过分析整个文件系统中,每个使用者(群组)拥有的档案总数与总容量, 再将这些数据记录在该文件系统的最顶层目录,然后在该记录文件中再使用每个账号(或群组)的限制值去规范磁盘使用量的。 所以建置这个 Quota 记录文件就显的非常的重要。扫瞄有支持 Quota 参数 (usrquota, grpquota) 的文件系统, 就使用 quotacheck 这个指令!这个指令的语法如下:
一、quotacheck :扫瞄文件系统并建立 Quota 的记录文件

quotacheck 的选项你只要记得『 -avug 』一起下达即可!那个 -f 与 -M 是在文件系统可能已经启动 quota 了, 但是你还想要重新扫瞄文件系统时,系统会要求你加入那两个选项(担心有其他人已经使用 quota 中) !平时没必要不要加上那两个项目。好了,那就让我们来处理我们的任务吧!
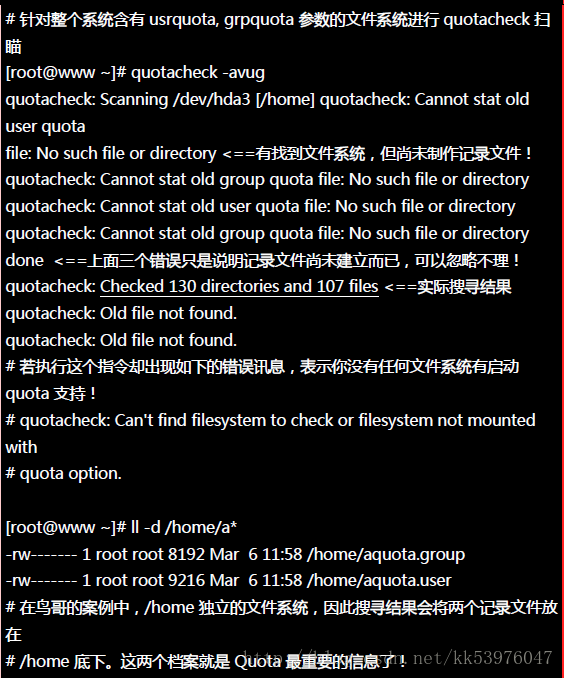
这个指令只要进行到这里就够了,不要反复的进行!因为等一下我们会启动 quota 功能,若启动后你还要进行 quotacheck , 系统会担心破坏原有的记录文件,所以会产生一些错误讯息警告你。如果你确定没有任何人在使用 quota 时, 可以强制重新进行 quotacheck 的动作。强制执行的情况可以使用如下的选项功能:

这样记录文件就建立起来了!你不用手动去编辑那两个档案~因为那两个档案是 quota 自己的数据文件,并不是纯文本档! 且该档案会一直变动,这是因为当你对 /home 这个文件系统进行操作时,你操作的结果会影响磁盘吧! 所以当然会同步记载到那两个档案中!所以要建立 aquota.user, aquota.group,记得使用的是 quotacheck 指令! 不是手动编辑的!
15.1.5. 实作 Quota 流程-3:启动、关闭与限制值设定 (quotaon, quotaoff, edquota)
制作好 Quota 配置文件之后,接下来就是要启动 quota 了!使用 quotaon ,至于关闭就用 quotaoff 即可 :
一、quotaon :启动 quota 的服务

这个『 quotaon -auvg 』的指令几乎只在第一次启动 quota 时才需要进行!因为下次等你重新启动系统时, 系统的 /etc/rc.d/rc.sysinit 这个初始化脚本就会自动的下达这个指令了!因此你只要在这次实例中进行一次即可, 未来都不需要自行启动 quota ,因为 CentOS 5.x 系统会自动帮你搞定他!
二、quotaoff :关闭 quota 的服务


这个指令就是关闭了 quota 的支持!我们这里需要练习 quota 实作,所以这里请不要关闭他! 接下来让我们开始来设定使用者与群组的 quota 限额吧!
三、edquota :编辑账号/群组的限值与宽限时间
edquota 是 edit quota 的缩写,所以就是用来编辑使用者或者是群组限额的指令。我们先来看看 edquota 的语法吧, 看完后再来实际操作一下。

好了,先让我们来看看当进入 myquota1 的限额设定时,会出现什么画面:
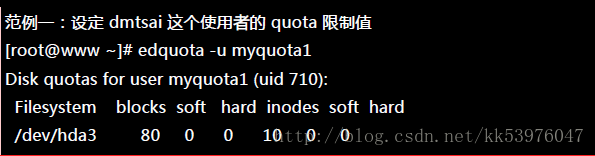
上头第一行在说明针对哪个账号 (myquota1) 进行 quota 的限额设定,第二行则是标头行,里面共分为七个字段, 七个字段分别的意义为:
- 文件系统 (filesystem):说明该限制值是针对哪个文件系统 (或 partition);
- 磁盘容量 (blocks):这个数值是 quota 自己算出来的,单位为 Kbytes,请不要更动他;
- soft:磁盘容量 (block) 的 soft 限制值,单位亦为 KB;
- hard:block 的 hard 限制值,单位 KB;
- 档案数量 (inodes):这是 quota 自己算出来的,单位为个数,请不要更动他;
- soft:inode 的 soft 限制值;
- hard:inode 的 hard 限制值;
当 soft/hard 为 0 时,表示没有限制的意思。好,依据我们的范例说明,我们需要设定的是 blocks 的 soft/hard ,至于 inode 则不要去更动他!因此上述的画面我们将他改成如下的模样:


设定完成之后,我们还有其他 5 个用户要设定,由于设定值都一样,此时可以使用 quota 复制!

这样就方便多了!然后,赶紧更改一下群组的 quota 限额!
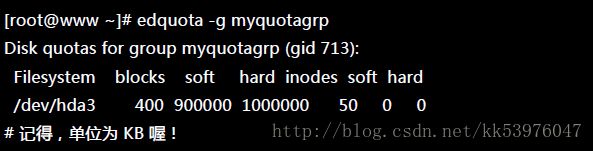
最后,将宽限时间给他改成 14 天!

透过这个简单的小步骤,我们已经将使用者/群组/宽限时间都设定妥当!接下来观察设定有没有生效!
15.1.6. 实作 Quota 流程-4:Quota 限制值的报表 (quota, repquota)
quota 的报表主要有两种模式,一种是针对每个个人或群组的 quota 指令,一个是针对整个文件系统的 repquota 指令。 我们先从较简单的 quota 来介绍!你也可以顺道看看你的设定值对不对啊!
一、quota :单一用户的 quota 报表
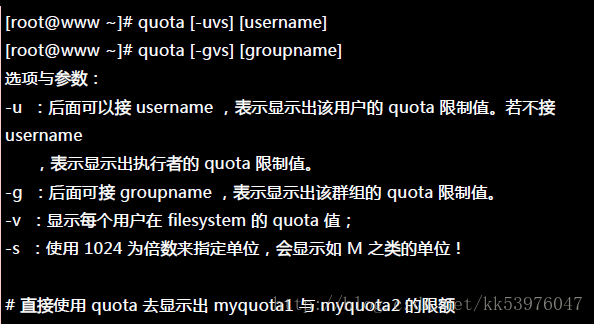
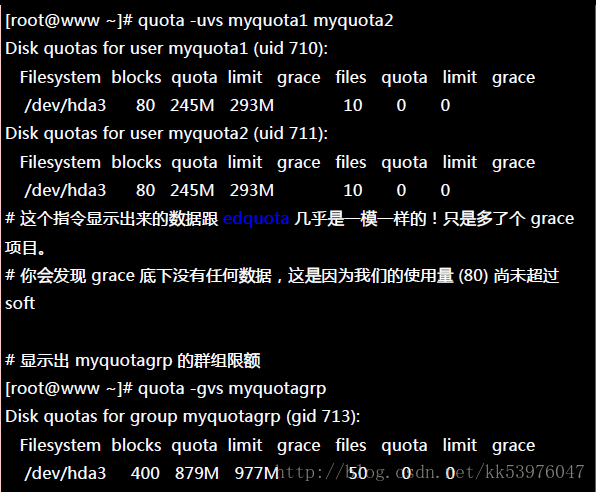
由于使用常见的 K, M, G 等单位比较好算,因此上头我们使用了『 -s 』的选项,就能够以 M 为单位显示了。 不过由于我们使用 edquota 设定限额时,使用的是近似值 (1000) 而不是实际的 1024 倍数, 所以看起来会有点不太一样!由于 quota 仅能针对某些用户显示报表,如果要针对整个 filesystem 列出报表时, 那个 repquota 就派上用场了!
二、repquota :针对文件系统的限额做报表
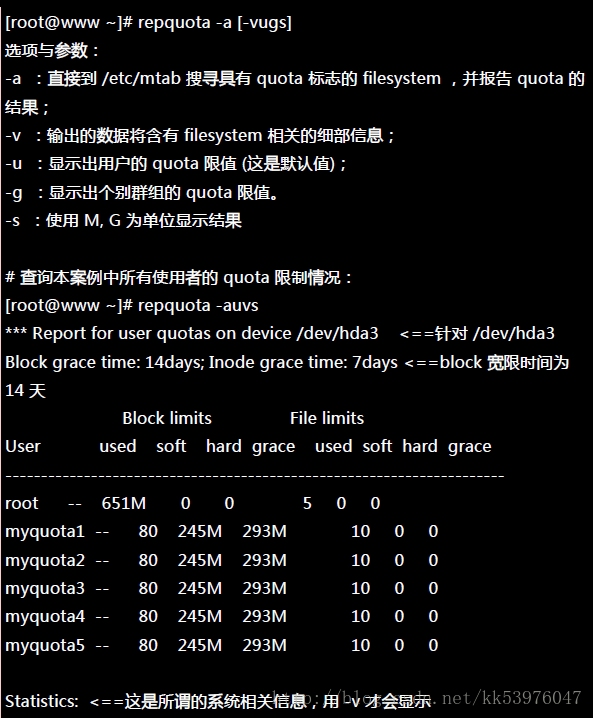

根据这些信息,您就可以知道目前的限制情况!你可以赶紧针对你的系统设定一下磁盘使用的规则,让你的用户不会抱怨磁盘怎么老是被耗光!
15.1.7. 实作 Quota 流程-5:测试与管理 (测试, warnquota, setquota)
Quota 到底有没有效果?让我们使用 myquota1 去测试看看,如果建立一个大档案时, 整个系统会便怎样呢?

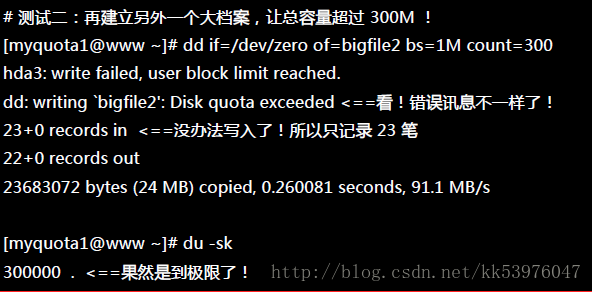
此时 myquota1 可以开始处理他的文件系统了!如果不处理的话,最后宽限时间会归零,然后出现如下的画面:
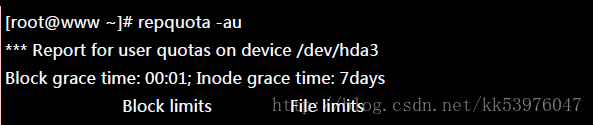
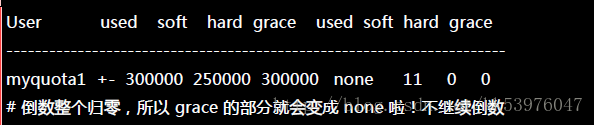
其实倒数归零也不会有什么特殊的意外!只是如果你的磁盘使用量介于 soft/hard 之间时, 当倒数归零那么 soft 的值会变成严格限制,此时你就没有多余的容量可以使用了。登入系统去删除档案即可解决!没有想象中那么可怕!问题是,使用者通常傻傻分不清楚到底系统出了什么问题, 所以我们可能需要寄送一些警告信 (email) 给用户比较妥当。那么如何处理呢?透过 warnquota 来处置即可。
一、warnquota :对超过限额者发出警告信
warnquota字面上的意义就是 quota 的警告 (warn) !他可以依据 /etc/warnquota.conf 的设定,然后找出目前系统上面 quota 用量超过 soft (就是有 grace time 出现的那些家伙) 的账号,透过 email 的功能将警告信件发送到用户的电子邮件信箱。 warnquota 并不会自动执行,所以我们需要手动去执行他。单纯执行『 warnquota 』之后,他会发送两封信出去, 一封给 myquota1 一封给 root !
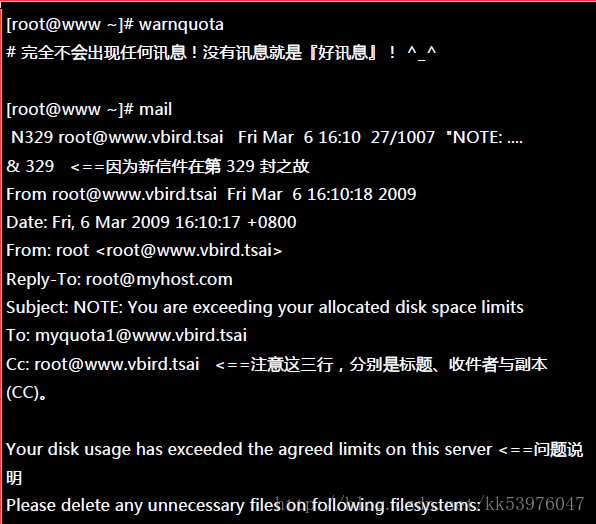
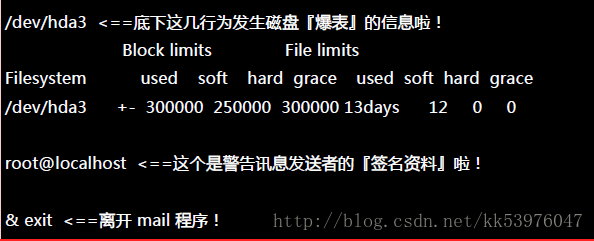
执行 warnquota 可能也不会产生任何讯息以及信件,因为只有当使用者的 quota 有超过 soft 时, warnquota 才会发送警告信!上表的内容中,包括标题、信息内容说明、签名文件等数据放在 /etc/warnquota !因为上述的资料是英文,不好理解吗?你可以自己转成中文! 所以你可以这样处理的:

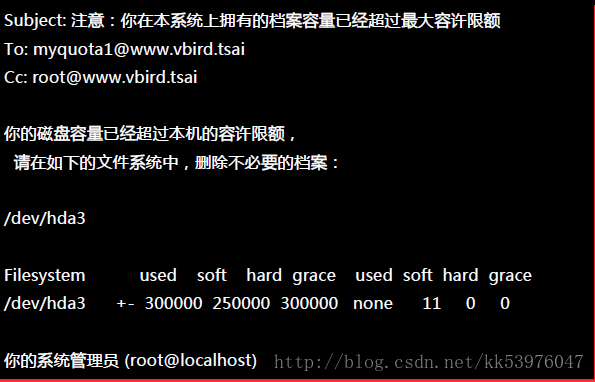
如果你重复执行 warnquota ,那么 myquota1 就会收到类似如下的信件内容:
不过这个方法并不适用在 /var/spool/mail 也爆表的 quota 控管中,因为如果使用者在这个 filesystem 的容量已经爆表,那么新的信件当然就收不下来啦!此时就只能等待使用者自己发现并跑来这里删除资料, 或者是请求 root 帮忙处理!那么我们怎么让系统自动的执行 warnquota 呢? 你可以这样做:

那么未来每天早上 4:02am 时,这个档案就会主动被执行,那么系统就能够主动的通知磁盘配额爆表的用户!至于为何要写入上述的档案呢?留待下一章工作排程时我们再来加强介绍!
二、setquota :直接于指令中设定 quota 限额
如果你想要使用 script 的方法来 建立大量的账号,并且所有的账号都在建立时就给予 quota ,那该如何是好? 其实有两个方法可以考虑:
- 先建立一个原始 quota 账号,再以『 edquota -p old -u new 』写入 script 中;
- 直接以 setquota 建立用户的 quota 设定值。
不同于 edquota 是呼叫 vi 来进行设定,setquota 直接由指令输入所必须要的各项限制值。 他的语法有点像这样:
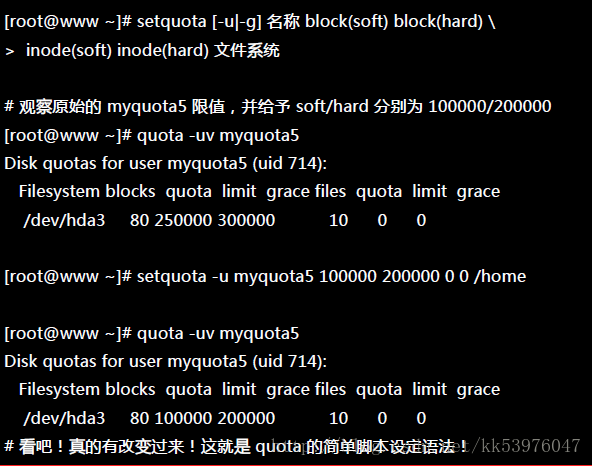
15.1.8. 不更动既有系统的 Quota 实例
如果你的主机原先没有想到要设定成为邮件主机,所以并没有规划将邮件信箱所在的 /var/spool/mail/ 目录独立成为一个 partition ,然后目前你的主机已经没有办法新增或分割出任何新的分割槽了。那我们知道 quota 是针对整个 filesystem 进行设计的,因此,你是否就无法针对 mail 的使用量给予 quota 的限制呢?
此外,如果你想要让使用者的邮件信箱与家目录的总体磁盘使用量为固定,那又该如何是好? 由于 /home 及 /var/spool/mail 根本不可能是同一个 filesystem (除非是都不分割,使用根目录,才有可能整合在一起), 所以,该如何进行这样的 quota 限制呢?
既然 quota 是针对整个 filesystem 来进行限制,假设你又已经有 /home 这个独立的分割槽了, 那么你只要:
- 将 /var/spool/mail 这个目录完整的移动到 /home 底下;
- 利用 ln -s /home/mail /var/spool/mail 来建立链接数据;
- 将 /home 进行 quota 限额设定 ;
只要这样的一个小步骤,您家主机的邮件就有一定的限额!也可以依据不同的使用者与群组来设定 quota 然后同样的以上面的方式来进行 link 的动作!就有不同的限额针对不同的使用者提出了!
15.2. 软件磁盘阵列 (Software RAID)
在过去年轻的时代,我们能使用的硬盘容量都不大,几十 GB 的容量就是大硬盘了!但是某些情况下,我们需要很大容量的储存空间, 例如鸟哥在跑的空气质量模式所输出的数据文件一个案例通常需要好几 GB ,连续跑个几个案例,磁盘容量就不够用了。 此时我该如何是好?其实可以透过一种储存机制,称为磁盘阵列 (RAID) 的就是了。这种机制的功能是什么?他有哪些等级?什么是硬件、软件磁盘阵列?Linux 支持什么样的软件磁盘阵列?
15.2.1. 什么是 RAID: RAID-0, RAID-1, RAID0+1, RAID-5, Spare disk
磁盘阵列全名是『 Redundant Arrays of Inexpensive Disks, RAID 』,英翻中的意思是:容错式廉价磁盘阵列。 RAID 可以透过一个技术(软件或硬件),将多个较小的磁盘整合成为一个较大的磁盘装置; 而这个较大的磁盘功能可不止是储存而已,他还具有数据保护的功能。整个 RAID 由于选择的等级 (level) 不同,而使得整合后的磁盘具有不同的功能, 基本常见的 level 有这几种(注1):
一、RAID-0 (等量模式, stripe):效能最佳
这种模式如果使用相同型号与容量的磁盘来组成时,效果较佳。这种模式的 RAID 会将磁盘先切出等量的区块 (举例来说, 4KB), 然后当一个档案要写入 RAID 时,该档案会依据区块的大小切割好,之后再依序放到各个磁盘里面去。由于每个磁盘会交错的存放数据, 因此当你的数据要写入 RAID 时,数据会被等量的放置在各个磁盘上面。举例来说,你有两颗磁盘组成 RAID-0 , 当你有 100MB 的数据要写入时,每个磁盘会各被分配到 50MB 的储存量。RAID-0 的示意图如下所示:
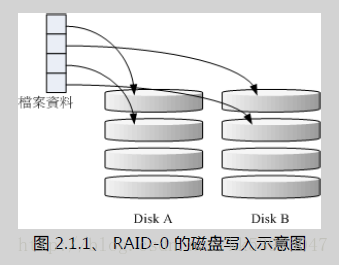
在组成 RAID-0 时,每颗磁盘 (Disk A 与 Disk B) 都会先被区隔成为小区块 (chunk)。 当有数据要写入 RAID 时,资料会先被切割成符合小区块的大小,然后再依序一个一个的放置到不同的磁盘去。 由于数据已经先被切割并且依序放置到不同的磁盘上面,因此每颗磁盘所负责的数据量都降低了!照这样的情况来看, 越多颗磁盘组成的 RAID-0 效能会越好,因为每颗负责的资料量就更低了 ! 这表示我的资料可以分散让多颗磁盘来储存,当然效能会变的更好!此外,磁盘总容量也变大了! 因为每颗磁盘的容量最终会加总成为 RAID-0 的总容量!
只是使用此等级你必须要自行负担数据损毁的风险,由上图我们知道档案是被切割成为适合每颗磁盘分区区块的大小, 然后再依序放置到各个磁盘中。如果某一颗磁盘损毁了,那么档案数据将缺一块,此时这个档案就损毁了。 由于每个档案都是这样存放的,因此 RAID-0 只要有任何一颗磁盘损毁,在 RAID 上面的所有数据都会遗失而无法读取。
另外,如果使用不同容量的磁盘来组成 RAID-0 时,由于数据是一直等量的依序放置到不同磁盘中,当小容量磁盘的区块被用完了, 那么所有的数据都将被写入到最大的那颗磁盘去。举例来说,我用 200G 与 500G 组成 RAID-0 , 那么最初的 400GB 数据可同时写入两颗磁盘 (各消耗 200G 的容量),后来再加入的数据就只能写入 500G 的那颗磁盘中了。 此时的效能就变差了,因为只剩下一颗可以存放数据!
二、RAID-1 (映像模式, mirror):完整备份
这种模式也是需要相同的磁盘容量的,最好是一模一样的磁盘!如果是不同容量的磁盘组成 RAID-1 时,那么总容量将以最小的那一颗磁盘为主!这种模式主要是『让同一份数据,完整的保存在两颗磁盘上头』。举例来说,如果我有一个 100MB 的档案,且我仅有两颗磁盘组成 RAID-1 时, 那么这两颗磁盘将会同步写入 100MB 到他们的储存空间去。 因此,整体 RAID 的容量几乎少了 50%。由于两颗硬盘内容一模一样,好像镜子映照出来一样, 所以我们也称他为 mirror 模式~
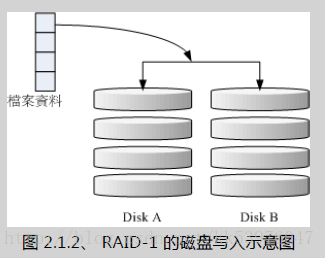
如上图所示,一份数据传送到 RAID-1 之后会被分为两股,并分别写入到各个磁盘里头去。 由于同一份数据会被分别写入到其他不同磁盘,因此如果要写入 100MB 时,数据传送到 I/O 总线后会被复制多份到各个磁盘, 结果就是数据量感觉变大了!因此在大量写入 RAID-1 的情况下,写入的效能可能会变的非常差 (因为我们只有一个南桥!)。 好在如果你使用的是硬件 RAID (磁盘阵列卡) 时,磁盘阵列卡会主动的复制一份而不使用系统的 I/O 总线,效能方面则还可以。 如果使用软件磁盘阵列,可能效能就不好了。
由于两颗磁盘内的数据一模一样,所以任何一颗硬盘损毁时,你的资料还是可以完整的保留下来的! 所以我们可以说, RAID-1 最大的优点大概就在于数据的备份!不过由于磁盘容量有一半用在备份, 因此总容量会是全部磁盘容量的一半而已。虽然 RAID-1 的写入效能不佳,不过读取的效能则还可以!这是因为数据有两份在不同的磁盘上面,如果多个 processes 在读取同一笔数据时, RAID 会自行取得最佳的读取平衡。
三、RAID 0+1,RAID 1+0
RAID-0 的效能佳但是数据不安全,RAID-1 的数据安全但是效能不佳,那么能不能将这两者整合起来设定 RAID 呢? 可以啊!那就是 RAID 0+1 或 RAID 1+0。所谓的 RAID 0+1 就是: (1)先让两颗磁盘组成 RAID 0,并且这样的设定共有两组; (2)将这两组 RAID 0 再组成一组 RAID 1。这就是 RAID 0+1 !反过来说,RAID 1+0 就是先组成 RAID-1 再组成 RAID-0 的意思。
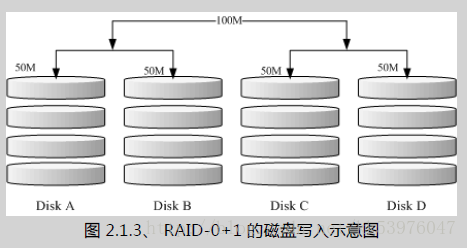
如上图所示,Disk A + Disk B 组成第一组 RAID 0,Disk C + Disk D 组成第二组 RAID 0, 然后这两组再整合成为一组 RAID 1。如果我有 100MB 的数据要写入,则由于 RAID 1 的关系, 两组 RAID 0 都会写入 100MB,但由于 RAID 0 的关系,因此每颗磁盘仅会写入 50MB 而已。 如此一来不论哪一组 RAID 0 的磁盘损毁,只要另外一组 RAID 0 还存在,那么就能够透过 RAID 1 的机制来回复数据。
由于具有 RAID 0 的优点,所以效能得以提升,由于具有 RAID 1 的优点,所以数据得以备份。 但是也由于 RAID 1 的缺点,所以总容量会少一半用来做为备份!
四、RAID 5:效能与数据备份的均衡考虑
RAID-5 至少需要三颗以上的磁盘才能够组成这种类型的磁盘阵列。这种磁盘阵列的数据写入有点类似 RAID-0 , 不过每个循环的写入过程中,在每颗磁盘还加入一个同位检查数据 (Parity) ,这个数据会记录其他磁盘的备份数据, 用于当有磁盘损毁时的救援。RAID-5 读写的情况有点像底下这样:
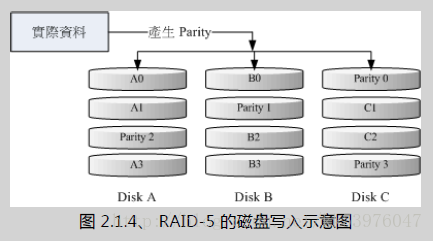
如上图所示,每个循环写入时,都会有部分的同位检查码 (parity) 被记录起来,并且记录的同位检查码每次都记录在不同的磁盘, 因此,任何一个磁盘损毁时都能够藉由其他磁盘的检查码来重建原本磁盘内的数据!不过需要注意的是, 由于有同位检查码,因此 RAID 5 的总容量会是整体磁盘数量减一颗。以上图为例, 原本的 3 颗磁盘只会剩下 (3-1)=2 颗磁盘的容量。而且当损毁的磁盘数量大于等于两颗时,这整组 RAID 5 的资料就损毁了。 因为 RAID 5 预设仅能支持一颗磁盘的损毁情况。
在读写效能的比较上,读取的效能还不赖!与 RAID-0 有的比!不过写的效能就不见得能够增加很多! 这是因为要写入 RAID 5 的数据还得要经过计算同位检查码 (parity) 的关系。由于加上这个计算的动作, 所以写入的效能与系统的硬件关系较大!尤其当使用软件磁盘阵列时,同位检查码是透过 CPU 去计算而非专职的磁盘阵列卡, 因此效能方面还需要评估。
另外,由于 RAID 5 仅能支持一颗磁盘的损毁,因此近来还有发展出另外一种等级,就是 RAID 6 ,这个 RAID 6 则使用两颗磁盘的容量作为 parity 的储存,因此整体的磁盘容量就会少两颗,但是允许出错的磁盘数量就可以达到两颗了! 也就是在 RAID 6 的情况下,同时两颗磁盘损毁时,数据还是可以救回来!
五、Spare Disk:预备磁盘的功能:
当磁盘阵列的磁盘损毁时,就得要将坏掉的磁盘拔除,然后换一颗新的磁盘。换成新磁盘并且顺利启动磁盘阵列后, 磁盘阵列就会开始主动的重建 (rebuild) 原本坏掉的那颗磁盘数据到新的磁盘上!然后你磁盘阵列上面的数据就复原了! 这就是磁盘阵列的优点。不过,我们还是得要动手拔插硬盘,此时通常得要关机才能这么做。
为了让系统可以实时的在坏掉硬盘时主动的重建,因此就需要预备磁盘 (spare disk) 的辅助。 所谓的 spare disk 就是一颗或多颗没有包含在原本磁盘阵列等级中的磁盘,这颗磁盘平时并不会被磁盘阵列所使用, 当磁盘阵列有任何磁盘损毁时,则这颗 spare disk 会被主动的拉进磁盘阵列中,并将坏掉的那颗硬盘移出磁盘阵列! 然后立即重建数据系统。如此你的系统则可以永保安康!若你的磁盘阵列有支持热拔插那就更完美了! 直接将坏掉的那颗磁盘拔除换一颗新的,再将那颗新的设定成为 spare disk ,就完成了!
举例来说,以前所待的研究室有一个磁盘阵列可允许 16 颗磁盘的数量,不过我们只安装了 10 颗磁盘作为 RAID 5。 每颗磁盘的容量为 250GB,我们用了一颗磁盘作为 spare disk ,并将其他的 9 颗设定为一个 RAID 5, 因此这个磁盘阵列的总容量为: (9-1)*250G=2000G。运作了一两年后真的有一颗磁盘坏掉了,我们后来看灯号才发现! 不过对系统没有影响!因为 spare disk 主动的加入支持,坏掉的那颗拔掉换颗新的,并重新设定成为 spare 后, 系统内的数据还是完整无缺的!
六、磁盘阵列的优点
说的口沫横飞,重点在哪里呢?其实你的系统如果需要磁盘阵列的话,其实重点在于:
- 数据安全与可靠性:指的并非信息安全,而是当硬件 (指磁盘) 损毁时,数据是否还能够安全的救援或使用之意;
- 读写效能:例如 RAID 0 可以加强读写效能,让你的系统 I/O 部分得以改善;
- 容量:可以让多颗磁盘组合起来,故单一文件系统可以有相当大的容量。
尤其数据的可靠性与完整性更是使用 RAID 的考虑重点!毕竟硬件坏掉换掉就好了,软件数据损毁那可不是闹着玩的!
15.2.2. software, hardware RAID
为何磁盘阵列又分为硬件与软件呢?所谓的硬件磁盘阵列 (hardware RAID) 是透过磁盘阵列卡来达成数组的目的。 磁盘阵列卡上面有一块专门的芯片在处理 RAID 的任务,因此在效能方面会比较好。在很多任务 (例如 RAID 5 的同位检查码计算) 磁盘阵列并不会重复消耗原本系统的 I/O 总线,理论上效能会较佳。此外目前一般的中高阶磁盘阵列卡都支持热拔插, 亦即在不关机的情况下抽换损坏的磁盘,对于系统的复原与数据的可靠性方面非常的好用。
不过一块好的磁盘阵列卡动不动就上万元台币,便宜的在主板上面『附赠』的磁盘阵列功能可能又不支持某些高阶功能, 例如低阶主板若有磁盘阵列芯片,通常仅支持到 RAID0 与 RAID1 ,鸟哥喜欢的 RAID 5 并没有支持。 此外,操作系统也必须要拥有磁盘阵列卡的驱动程序,才能够正确的捉到磁盘阵列所产生的磁盘驱动器!
由于磁盘阵列有很多优秀的功能,然而硬件磁盘阵列卡偏偏又贵的很~因此就有发展出利用软件来仿真磁盘阵列的功能, 这就是所谓的软件磁盘阵列 (software RAID)。软件磁盘阵列主要是透过软件来仿真数组的任务, 因此会损耗较多的系统资源,比如说 CPU 的运算与 I/O 总线的资源等。不过目前我们的个人计算机实在已经非常快速了, 因此以前的速度限制现在已经不存在!所以我们可以来玩一玩软件磁盘阵列!
我们的 CentOS 提供的软件磁盘阵列为 mdadm 这套软件,这套软件会以 partition 或 disk 为磁盘的单位,也就是说,你不需要两颗以上的磁盘,只要有两个以上的分割槽 (partition) 就能够设计你的磁盘阵列了。此外, mdadm 支持刚刚我们前面提到的 RAID0/RAID1/RAID5/spare disk 等! 而且提供的管理机制还可以达到类似热拔插的功能,可以在线 (文件系统正常使用) 进行分割槽的抽换! 使用上也非常的方便!
另外你必须要知道的是,硬件磁盘阵列在 Linux 底下看起来就是一颗实际的大磁盘,因此硬件磁盘阵列的装置文件名为 /dev/sd[a-p] ,因为使用到 SCSI 的模块之故。至于软件磁盘阵列则是系统仿真的,因此使用的装置文件名是系统的装置文件, 文件名为 /dev/md0, /dev/md1…,两者的装置文件名并不相同!不要搞混了!因为很多朋友常常觉得奇怪, 怎么他的 RAID 档名跟我们这里测试的软件 RAID 文件名不同,所以这里特别强调说明!
15.2.3. 软件磁盘阵列的设定: mdadm –create
软件磁盘阵列的设定很简单!因为你只要使用一个指令即可!那就是 mdadm 这个指令。 这个指令在建立 RAID 的语法有点像这样:


上面的语法中,最后面会接许多的装置文件名,这些装置文件名可以是整颗磁盘,例如 /dev/sdb , 也可以是分割槽,例如 /dev/sdb1 之类。不过,这些装置文件名的总数必须要等于 –raid-devices 与 –spare-devices 的个数总和才行!我利用测试机来建置一个 RAID 5 的软件磁盘阵列给您瞧瞧! 首先,将系统里面过去练习过而目前用不到的分割槽通通删除掉:
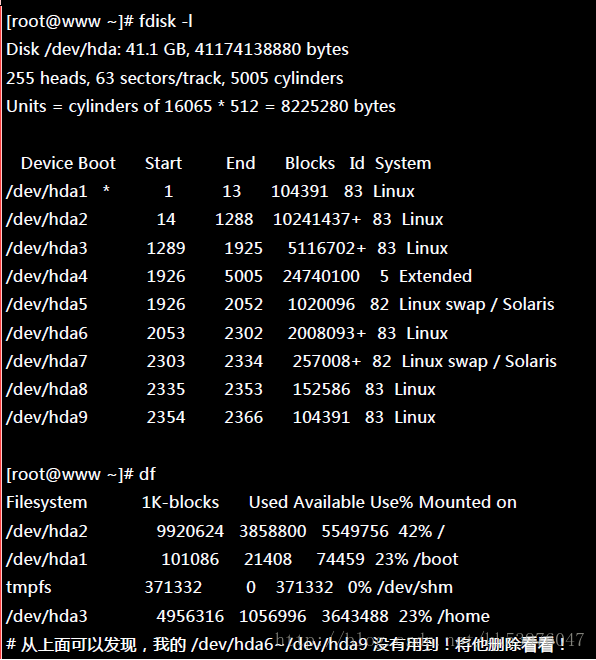
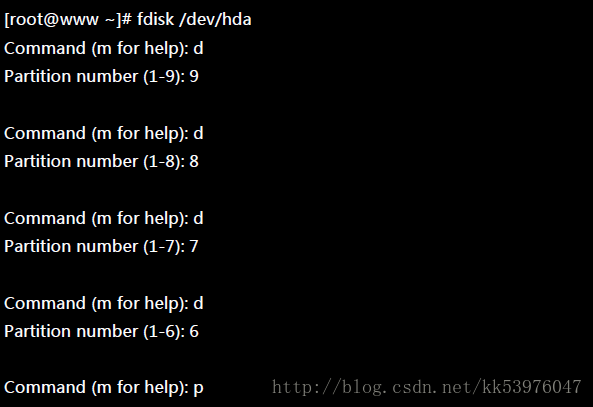
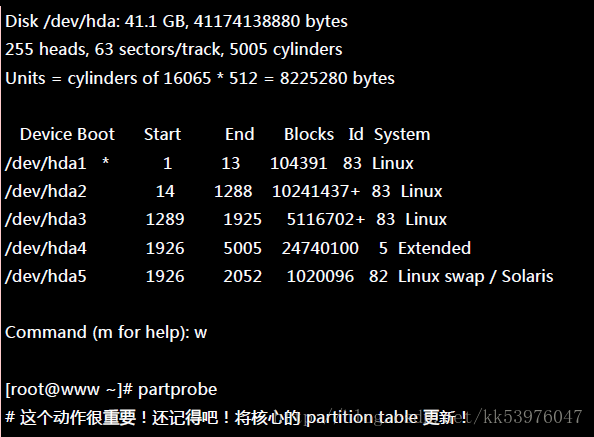
底下是我希望做成的 RAID 5 环境:
- 利用 4 个 partition 组成 RAID 5;
- 每个 partition 约为 1GB 大小,需确定每个 partition 一样大较佳;
- 利用 1 个 partition 设定为 spare disk
- 这个 spare disk 的大小与其他 RAID 所需 partition 一样大!
- 将此 RAID 5 装置挂载到 /mnt/raid 目录下;
最终我需要 5 个 1GB 的 partition 。由于我的系统仅有一颗磁盘,这颗磁盘剩余容量约 20GB 是够用的, 分割槽代号仅使用到 5 号,所以要制作成 RAID 5 应该是不成问题!接下来就是连续的建置流程啰!
一、建置所需的磁盘装置
如前所述,我需要 5 个 1GB 的分割槽,请利用 fdisk 来建置吧!
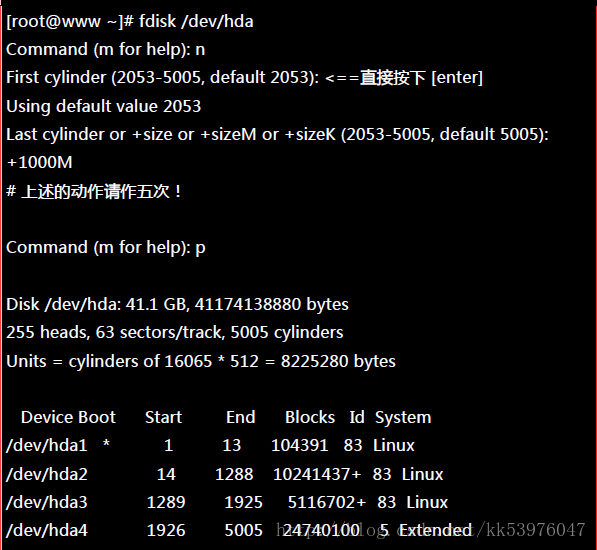
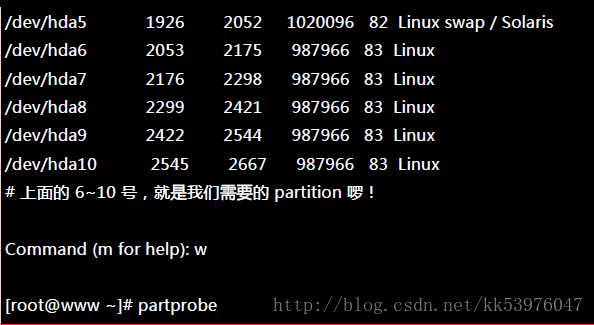
二、以 mdadm 建置 RAID
透过 mdadm 来建立磁盘阵列!
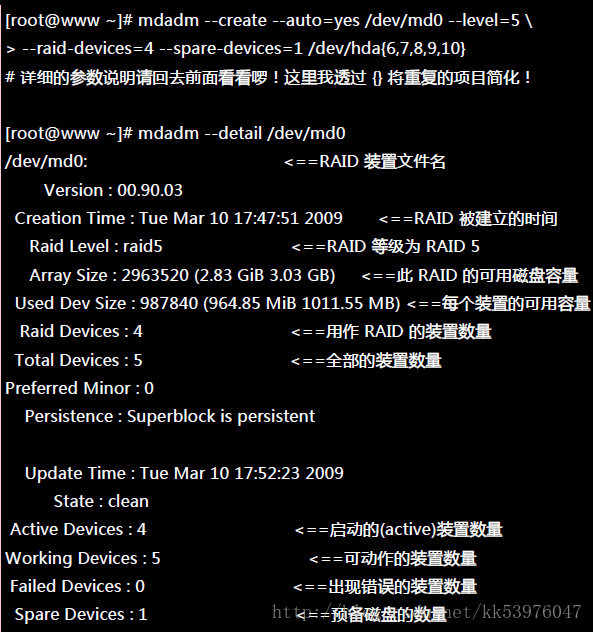
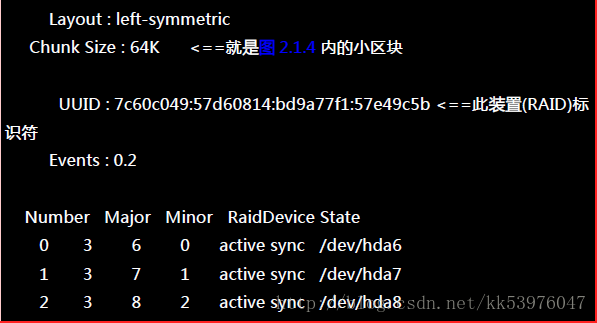

由于磁盘阵列的建置需要一些时间,所以你最好等待数分钟后再使用『 mdadm –detail /dev/md0 』去查阅你的磁盘阵列详细信息! 否则有可能看到某些磁盘正在『spare rebuilding』之类的建置字样!透过上面的指令, 你就能够建立一个 RAID5 且含有一颗 spare disk 的磁盘阵列! 除了指令之外,你也可以查阅如下的档案来看看系统软件磁盘阵列的情况:
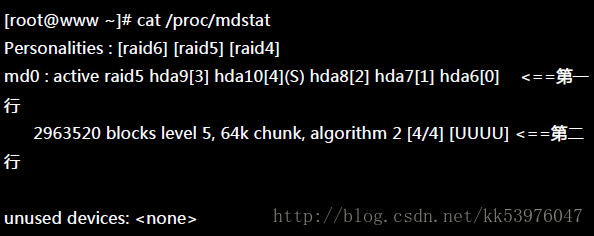
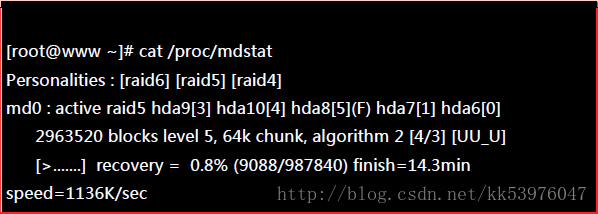
上述的资料比较重要的在特别指出的第一行与第二行部分(注2):
- 第一行部分:指出 md0 为 raid5 ,且使用了 hda9, hda8, hda7, hda6 等四颗磁盘装置。每个装置后面的中括号 [] 内的数字为此磁盘在 RAID 中的顺序 (RaidDevice);至于 hda10 后面的 [S] 则代表 hda10 为 spare 之意。
- 第二行部分:此磁盘阵列拥有 2963520 个block(每个 block 单位为 1K),所以总容量约为 3GB, 使用 RAID 5 等级,写入磁盘的小区块 (chunk) 大小为 64K,使用 algorithm 2 磁盘阵列算法。 [m/n] 代表此数组需要 m 个装置,且 n 个装置正常运作。因此本 md0 需要 4 个装置且这 4 个装置均正常运作。 后面的 [UUUU] 代表的是四个所需的装置 (就是 [m/n] 里面的 m) 的启动情况,U 代表正常运作,若为 _ 则代表不正常。
这两种方法都可以知道目前的磁盘阵列状态!
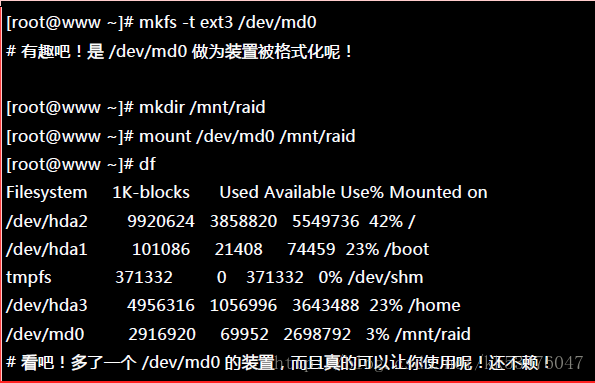
三、格式化与挂载使用 RAID
接下来就是开始使用格式化工具了!这部分就简单到爆!
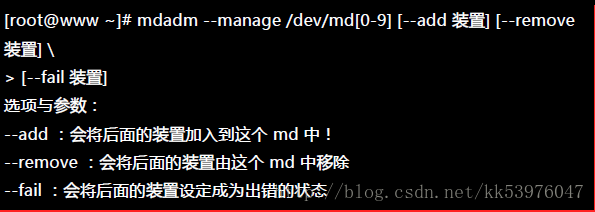
15.2.4. 仿真 RAID 错误的救援模式: mdadm –manage
谁也不知道你的磁盘阵列内的装置啥时会出差错,因此, 了解一下软件磁盘阵列的救援还是必须的!首先来了解一下 mdadm 这方面的语法:
一、设定磁盘为错误 (fault)
首先,我们来处理一下,该如何让一个磁盘变成错误,然后让 spare disk 自动的开始重建系统呢?


上面的画面你得要快速的连续输入那些 mdadm 的指令才看的到!因为你的 RAID 5 正在重建系统! 若你等待一段时间再输入后面的观察指令,则会看到如下的画面了:

又恢复正常了!我们的 /mnt/raid 文件系统是完整的!并不需要卸除!
二、将出错的磁盘移除并加入新磁盘
首先,我们再建立一个新的分割槽,这个分割槽要与其他分割槽一样大才好!然后再利用 mdadm 移除错误的并加入新的!
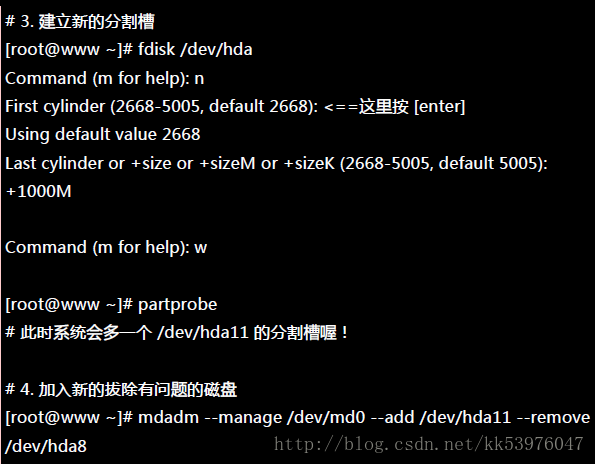
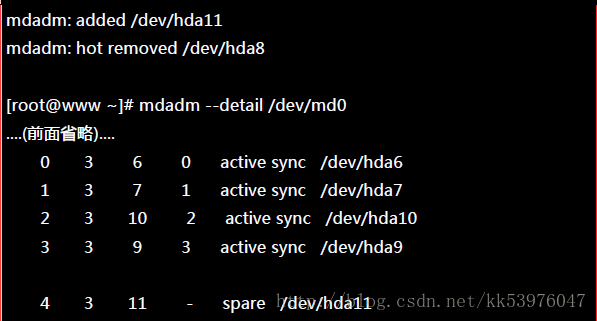
你的磁盘阵列内的数据不但一直存在,而且你可以一直顺利的运作 /mnt/raid 内的数据,即使 /dev/hda8 损毁了!然后透过管理的功能就能够加入新磁盘且拔除坏掉的磁盘!注意,这一切都是在上线 (on-line) 的情况下进行!
15.2.5. 开机自动启动 RAID 并自动挂载
新的 distribution 大多会自己搜寻 /dev/md[0-9] 然后在开机的时候给予设定好所需要的功能。不过还是建议你修改一下配置文件吧!software RAID 也是有配置文件的,这个配置文件在 /etc/mdadm.conf !这个配置文件内容很简单, 你只要知道 /dev/md0 的 UUID 就能够设定这个档案!这里仅介绍他最简单的语法:
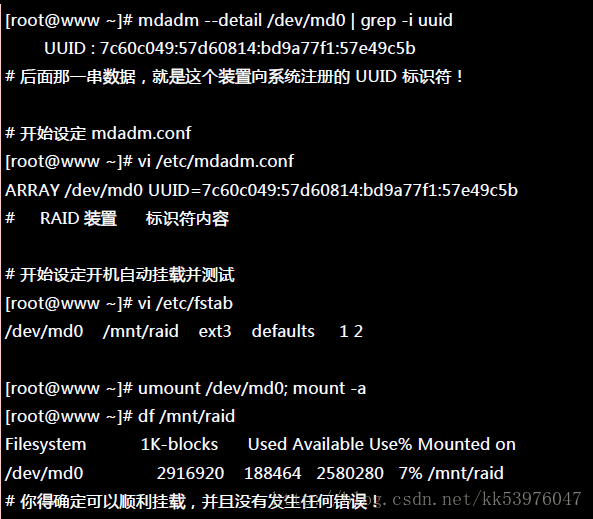
如果到这里都没有出现任何问题!接下来就请 reboot 你的系统并等待看看能否顺利的启动吧!
15.2.6. 关闭软件 RAID(重要!)
除非你未来就是要使用这颗 software RAID (/dev/md0),否则你势必要将这个 /dev/md0 关闭! 因为他毕竟是我们在这个测试机上面的练习装置!为什么要关掉他呢?因为这个 /dev/md0 其实还是使用到我们系统的磁盘分区槽, 在我的例子里面就是 /dev/hda{6,7,8,9,10,11},如果你只是将 /dev/md0 卸除,然后忘记将 RAID 关闭, 结果就是….未来你在重新分割 /dev/hdaX 时可能会出现一些莫名的错误状况!所以才需要关闭 software RAID 的步骤! 那如何关闭呢?(请注意,确认你的 /dev/md0 确实不要用且要关闭了才进行底下的玩意儿)

15.3. 逻辑滚动条管理员 (Logical Volume Manager)
若你在当初规划主机的时候将 /home 只给他 50G ,等到使用者众多之后导致这个 filesystem 不够大, 此时你能怎么作?多数的朋友都是这样:再加一颗新硬盘,然后重新分割、格式化,将 /home 的数据完整的复制过来, 然后将原本的 partition 卸除重新挂载新的 partition 。好忙碌啊!有没有更简单的方法呢? 有的!那就是我们这个小节要介绍的 LVM 这玩意儿!
LVM 的重点在于『可以弹性的调整 filesystem 的容量!』而并非在于效能与数据保全上面。 需要档案的读写效能或者是数据的可靠性,请参考前面的 RAID 小节。 LVM 可以整合多个实体 partition 在一起, 让这些 partitions 看起来就像是一个磁盘一样!而且,还可以在未来新增或移除其他的实体 partition 到这个 LVM 管理的磁盘当中。 如此一来,整个磁盘空间的使用上,实在是相当的具有弹性!
15.3.1. 什么是 LVM: PV, PE, VG, LV 的意义
LVM 的全名是 Logical Volume Manager,中文可以翻译作逡辑滚动条管理员。之所以称为『滚动条』可能是因为可以将 filesystem 像滚动条一样伸长或缩短之故!LVM 的作法是将几个实体的 partitions (或 disk) 透过软件组合成为一块看起来是独立的大磁盘 (VG) ,然后将这块大磁盘再经过分割成为可使用分割槽 (LV), 最终就能够挂载使用了。但是为什么这样的系统可以进行 filesystem 的扩充或缩小呢?其实与一个称为 PE 的项目有关!
一、Physical Volume, PV, 实体滚动条
我们实际的 partition 需要调整系统标识符 (system ID) 成为 8e (LVM 的标识符),然后再经过 pvcreate 的指令将他转成 LVM 最底层的实体滚动条 (PV) ,之后才能够将这些 PV 加以利用! 调整 system ID 的方法就是透过 fdisk !
二、Volume Group, VG, 滚动条群组
所谓的 LVM 大磁盘就是将许多 PV 整合成这个 VG 的东西!所以 VG 就是 LVM 组合起来的大磁盘! 那么这个大磁盘最大可以到多少容量呢?这与底下要说明的 PE 有关~因为每个 VG 最多仅能包含 65534 个 PE 而已。 如果使用 LVM 预设的参数,则一个 VG 最大可达 256GB 的容量!(参考底下的 PE 说明)
三、Physical Extend, PE, 实体延伸区块
LVM 预设使用 4MB 的 PE 区块,而 LVM 的 VG 最多仅能含有 65534 个 PE ,因此预设的 LVM VG 会有 4M*65534/(1024M/G)=256G。 这个 PE 很有趣!他是整个 LVM 最小的储存区块,也就是说,其实我们的档案资料都是藉由写入 PE 来处理的。 简单的说,这个 PE 就有点像文件系统里面的 block 大小。 这样说应该就比较好理解了吧?所以调整 PE 会影响到 VG 的最大容量!
四、Logical Volume, LV, 逻辑滚动条
最终的 VG 还会被切成 LV,这个 LV 就是最后可以被格式化使用的类似分割槽的咚咚了!那么 LV 是否可以随意指定大小呢? 当然不可以!既然 PE 是整个 LVM 的最小储存单位,那么 LV 的大小就与在此 LV 内的 PE 总数有关。 为了方便用户利用 LVM 来管理其系统,因此 LV 的装置文件名通常指定为『 /dev/vgname/lvname 』的样式!
此外,我们刚刚有谈到 LVM 可弹性的变更 filesystem 的容量,那是如何办到的?其实他就是透过『交换 PE 』来进行数据转换, 将原本 LV 内的 PE 移转到其他装置中以降低 LV 容量,或将其他装置的 PE 加到此 LV 中以加大容量! VG、LV 与 PE 的关系有点像下图:
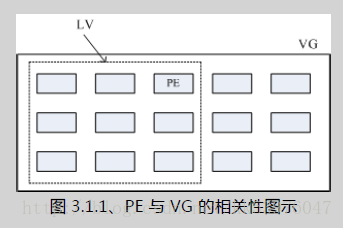
如上图所示,VG 内的 PE 会分给虚线部分的 LV,如果未来这个 VG 要扩充的话,加上其他的 PV 即可。 而最重要的 LV 如果要扩充的话,也是透过加入 VG 内没有使用到的 PE 来扩充的!
五、实作流程
透过 PV, VG, LV 的规划之后,再利用 mkfs 就可以将你的 LV 格式化成为可以利用的文件系统了!而且这个文件系统的容量在未来还能够进行扩充或减少, 而且里面的数据还不会被影响! 整个流程由基础到最终的结果可以这样看:
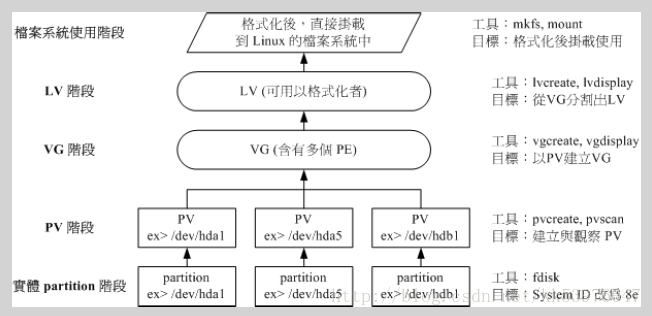
如此一来,我们就可以利用 LV 这个玩意儿来进行系统的挂载了。 那么我的数据写入这个 LV 时,到底他是怎么写入硬盘当中的? 其实,依据写入机制的不同有两种方式:
- 线性模式 (linear):假如我将 /dev/hda1, /dev/hdb1 这两个 partition 加入到 VG 当中,并且整个 VG 只有一个 LV 时,那么所谓的线性模式就是:当/dev/hda1 的容量用完之后,/dev/hdb1 的硬盘才会被使用到, 这也是我们所建议的模式。
- 交错模式 (triped):就是我将一笔数据拆成两部分,分别写入 /dev/hda1 与 /dev/hdb1 的意思,感觉上有点像 RAID 0 !如此一来,一份数据用两颗硬盘来写入,理论上,读写的效能会比较好。
基本上,LVM 最主要的用处是在实现一个可以弹性调整容量的文件系统上, 而不是在建立一个效能为主的磁盘上,所以,我们应该利用的是 LVM 可以弹性管理整个 partition 大小的用途上,而不是着眼在效能上的。因此, LVM 默认的读写模式是线性模式! 如果你使用 triped 模式,要注意,当任何一个 partition 『归天』时,所有的数据都会『损毁』的! 所以不是很适合使用这种模式!如果要强调效能与备份,那么就直接使用 RAID 即可, 不需要用到 LVM !
15.3.2. LVM 实作流程: PV 阶段, VG 阶段, LV 阶段, 文件系统阶段
LVM 必需要核心有支持且需要安装 lvm2 这个软件,好在是CentOS 与其他较新的 distributions 已经预设将 lvm 的支持与软件都安装妥当了!所以你不需要担心这方面的问题!
才使用的测试机又要出动了!刚刚我们才练习过 RAID,必须要将一堆目前没有用到的分割槽先杀掉, 然后再重建新的分割槽。并且由于我仅有一个 40GB 的磁盘,所以底下的练习都仅针对同一颗磁盘来作的。 我的要求有点像这样:
- 先分割出 4 个 partition ,每个 partition 的容量均为 1.5GB 左右,且system ID 需要为 8e;
- 全部的 partition 整合成为一个 VG,VG 名称设定为 vbirdvg;且 PE 的大小为 16MB;
- 全部的 VG 容量都丢给 LV ,LV 的名称设定为 vbirdlv;
- 最终这个 LV 格式化为 ext3 的文件系统,且挂载在 /mnt/lvm 中;
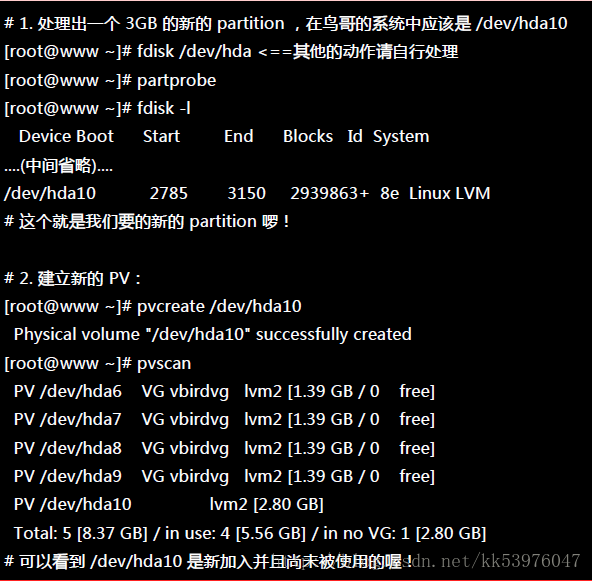
这就不仔细的介绍实体分割了,请您自行参考第八章的 fdisk 来达成底下的范例:(注意:修改系统标识符请使用 t 这个 fdisk 内的指令来处理即可)
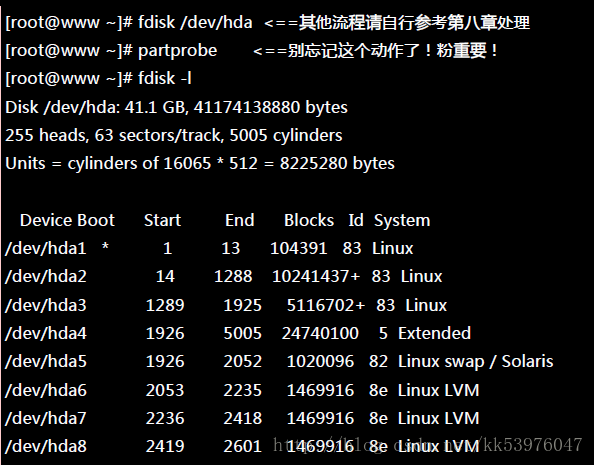

上面的 /dev/hda{6,7,8,9} 这四个分割槽就是我们的实体分割槽!也就是底下会实际用到的信息! 注意看,那个 8e 的出现会导致 system 变成『 Linux LVM 』!其实没有设定成为 8e 也没关系, 不过某些 LVM 的侦测指令可能会侦测不到该 partition 就是了!接下来,就一个一个的处理各流程吧!
一、PV 阶段
要建立 PV 其实很简单,只要直接使用 pvcreate 即可!我们来谈一谈与 PV 有关的指令吧!
- pvcreate :将实体 partition 建立成为 PV ;
- pvscan :搜寻目前系统里面任何具有 PV 的磁盘;
- pvdisplay :显示出目前系统上面的 PV 状态;
- pvremove :将 PV 属性移除,让该 partition 不具有 PV 属性。
那就直接来瞧一瞧吧!
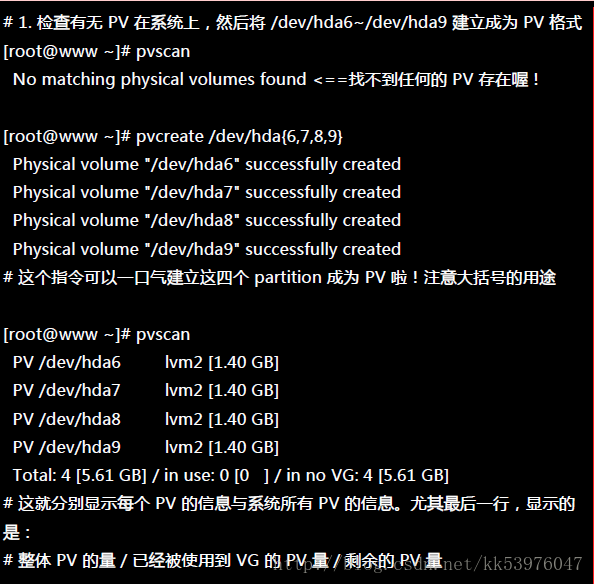


这样就将 PV 建立了两个!
二、VG 阶段
建立 VG 及 VG 相关的指令也不少,我们来看看:
- vgcreate :就是主要建立 VG 的指令!他的参数比较多,等一下介绍。
- vgscan :搜寻系统上面是否有 VG 存在?
- vgdisplay :显示目前系统上面的 VG 状态;
- vgextend :在 VG 内增加额外的 PV ;
- vgreduce :在 VG 内移除 PV;
- vgchange :设定 VG 是否启动 (active);
- vgremove :删除一个 VG !
与 PV 不同的是, VG 的名称是自定义的!我们知道 PV 的名称其实就是 partition 的装置文件名, 但是这个 VG 名称则可以随便自己取!在底下的例子当中,我将 VG 名称取名为 vbirdvg 。建立这个 VG 的流程是这样的:

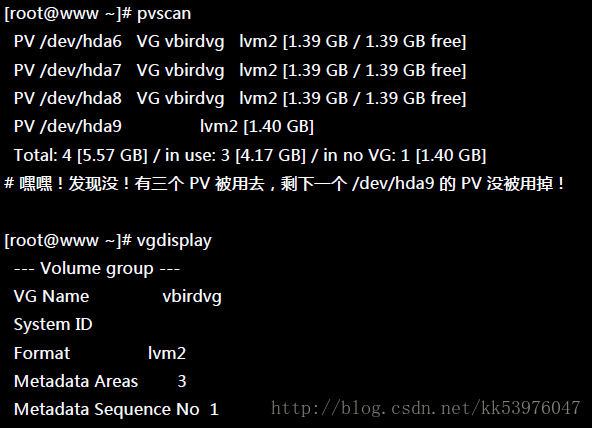
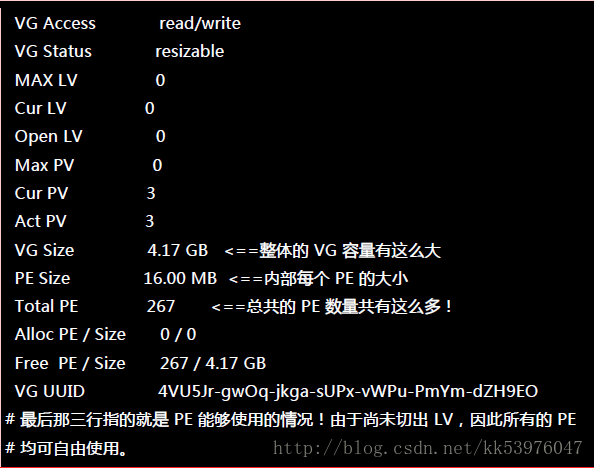
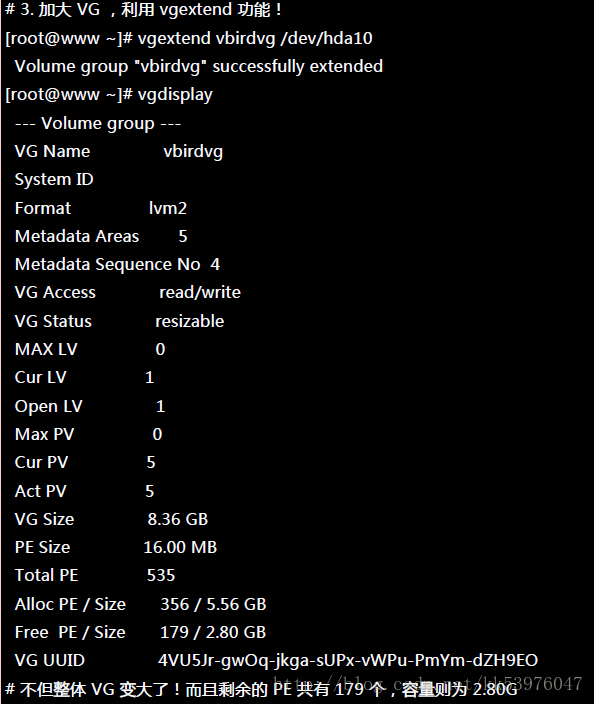
这样就建立一个 VG 了!假设我们要增加这个 VG 的容量,因为我们还有 /dev/hda9 !此时你可以这样做:
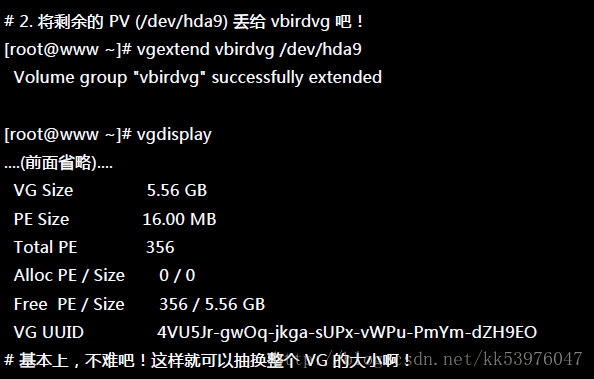
我们多了一个装置!接下来为这个 vbirdvg 进行分割吧!透过 LV 功能来处理!
三、LV 阶段
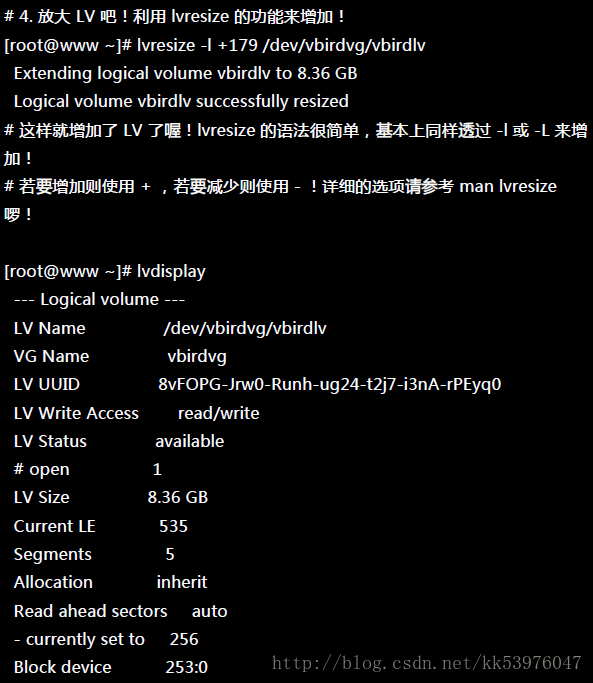
创造出 VG 这个大磁盘之后,再来就是要建立分割区啦!这个分割区就是所谓的 LV 啰!假设我要将刚刚那个 vbirdvg 磁盘,分割成为 vbirdlv ,整个 VG 的容量都被分配到 vbirdlv 里面去!先来看看能使用的指令后,就直接工作了先!
- lvcreate :建立 LV !
- lvscan :查询系统上面的 LV ;
- lvdisplay :显示系统上面的 LV 状态!
- lvextend :在 LV 里面增加容量!
- lvreduce :在 LV 里面减少容量;
- lvremove :删除一个 LV !
- lvresize :对 LV 进行容量大小的调整!
如此一来,整个 partition 也准备好了!接下来,就是针对这个 LV 来处理!要特别注意的是, VG 的名称为 vbirdvg , 但是 LV 的名称必须使用全名!亦即是 /dev/vbirdvg/vbirdlv 才对! 后续的处理都是这样的!这点初次接触 LVM 的朋友很容易搞错!

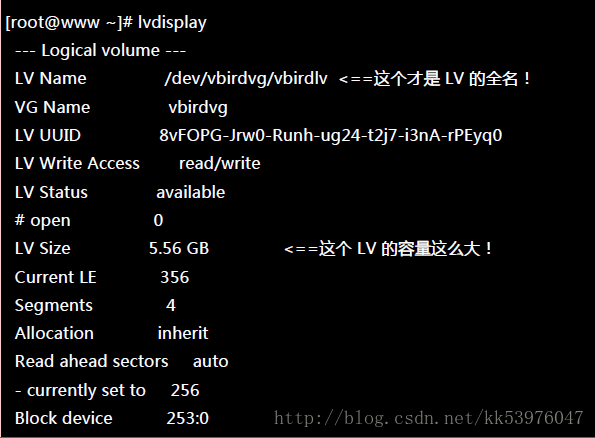
四、文件系统阶段
这个部分我就不再多加解释了!直接来进行吧!

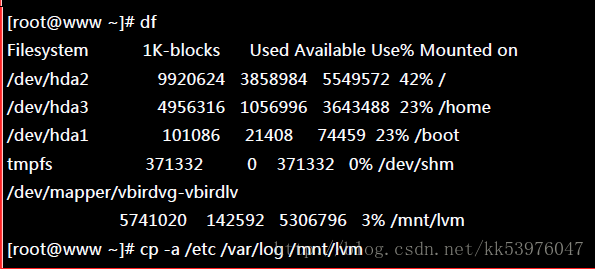
其实 LV 的名称建置成为 /dev/vbirdvg/vbirdlv 是为了让使用者直觉式的找到我们所需要的数据, 实际上 LVM 使用的装置是放置到 /dev/mapper/ 目录下的!所以你才会看到上表当中的特殊字体部分。 透过这样的功能,我们现在已经建置好一个 LV 了!你可以自由的应用 /mnt/lvm 内的所有资源!
15.3.3. 放大 LV 容量: resize2fs
我们不是说 LVM 最大的特色就是弹性调整磁盘容量吗?那我们就来处理一下,如果要放大 LV 的容量时, 该如何进行完整的步骤呢?你只要这样做即可:
- 用 fdisk 设定新的具有 8e system ID 的 partition;
- 利用 pvcreate 建置 PV;
- 利用 vgextend 将 PV 加入我们的 vbirdvg;
- 利用 lvresize 将新加入的 PV 内的 PE 加入 vbirdlv 中;
- 透过 resize2fs 将文件系统的容量确实增加!
其中最后一个步骤最重要!我们在第八章当中知道, 整个文件系统在最初格式化的时候就建立了 inode/block/superblock 等信息,要改变这些信息是很难的! 不过因为文件系统格式化的时候建置的是多个 block group ,因此我们可以透过在文件系统当中增加 block group 的方式来增减文件系统的量!而增减 block group 就是利用 resize2fs !所以最后一步是针对文件系统来处理的, 前面几步则是针对 LVM 的实际容量大小!
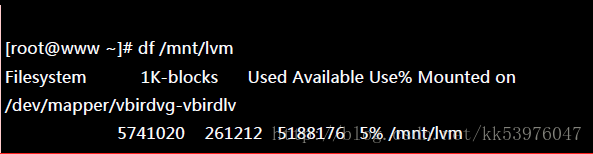
最终的结果中 LV 真的有放大到 8.36GB !但是文件系统却没有相对增加! 而且,我们的 LVM 可以在线直接处理,并不需要特别给他 umount !但是还是得要处理一下文件系统的容量!开始观察一下文件系统,然后使用 resize2fs 来处理一下!

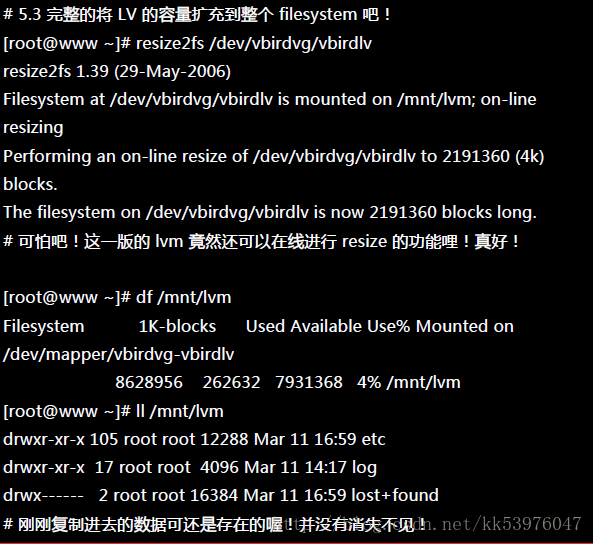
真的放大了!而且如果你已经有填数据在 LVM 扇区当中的话!这个数据是不会死掉的!还是继续存在原本的扇区当中! 整个动作竟然这么简单就完成了!原本的数据还是一直存在而不会消失!
此外,如果你再以 dumpe2fs 来检查 /dev/vbirdvg/vbirdlv 时,就会发现后续的 Group 增加了! 如果还是搞不清楚什么是 block group 时,请回到第八章看一下该章内图1.3.1的介绍吧!
15.3.4. 缩小 LV 容量
上一小节我们谈到的是放大容量,现在来谈到的是缩小容量!假设我们想将 /dev/hda6 抽离出来! 那该如何处理啊?就让上一小节的流程倒转过来即可!
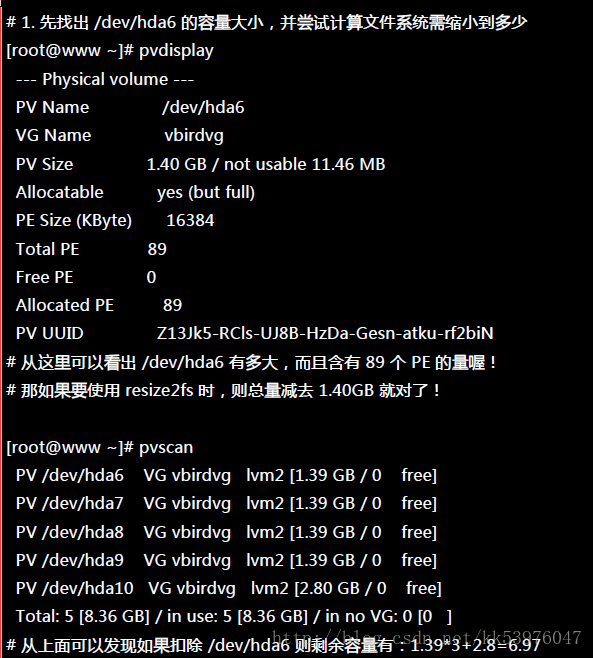

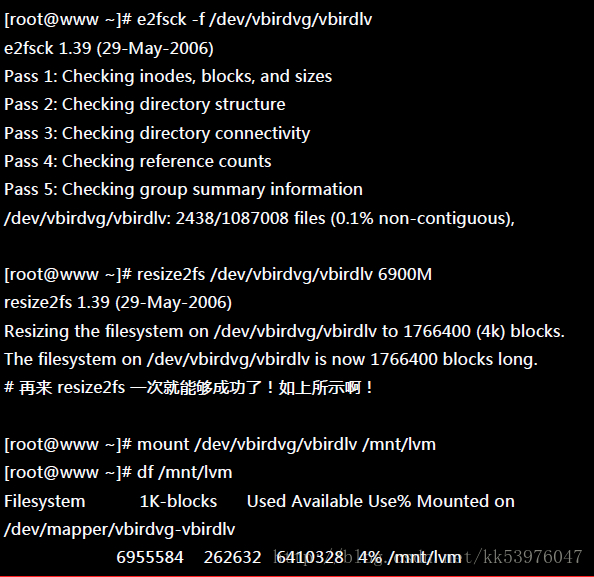
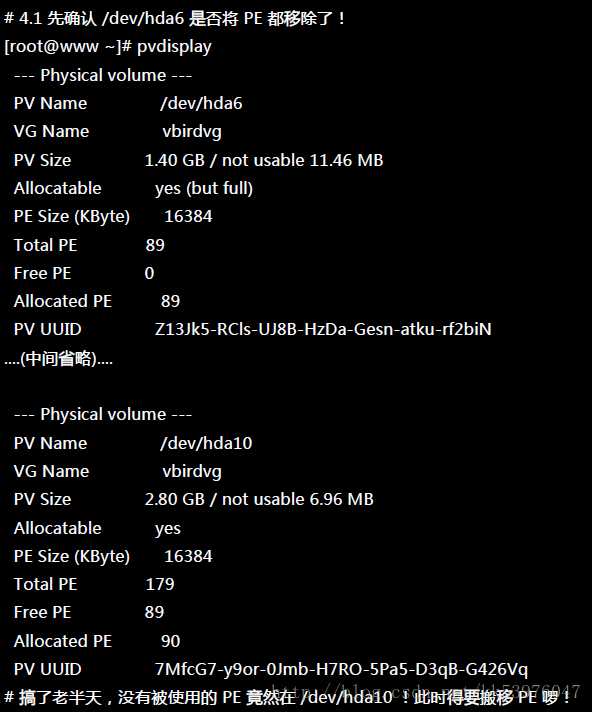
然后再来就是将 LV 的容量降低!要注意的是,我们想要抽离的是 /dev/hda6,这个 PV 有 89 个 PE (上面的 pvdisplay 查询到的结果)。所以要这样进行:
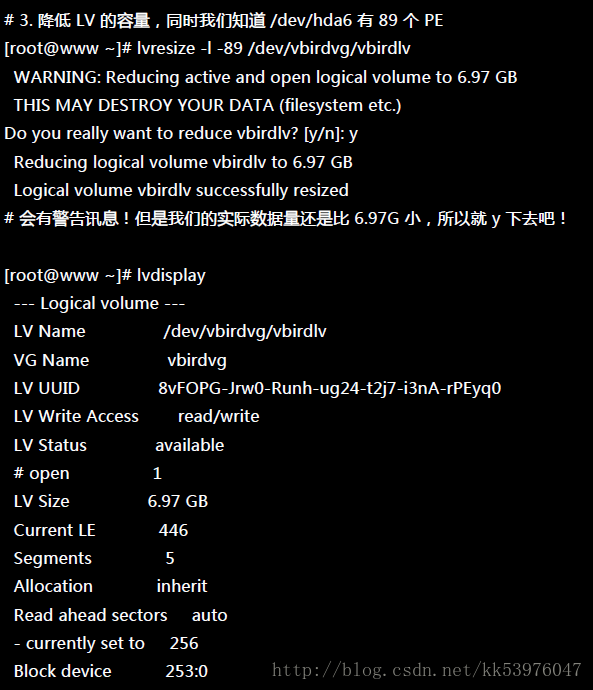
这样就将 LV 缩小了!接下来就要将 /dev/hda6 移出 vbirdvg 这个 VG 之外! 我们得要先确定 /dev/hda6 里面的 PE 完全不被使用后,才能够将 /dev/hda6 抽离! 所以得要这样进行:
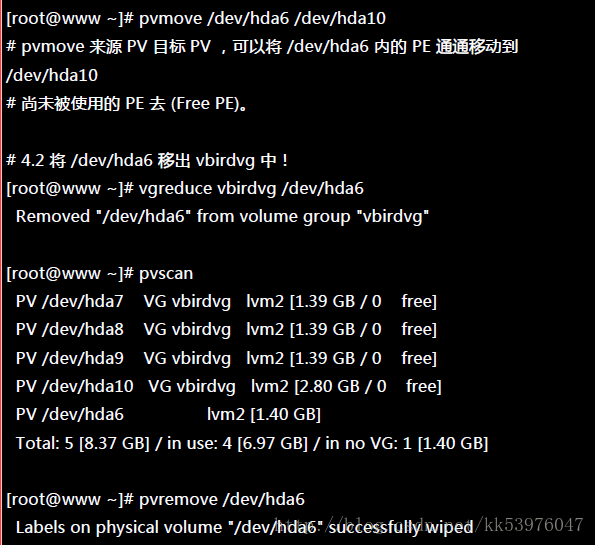
这样你的文件系统以及实际的 LV 与 VG 通通变小了,而且那个 /dev/hda6 还真的可以拿出来! 可以进行其他的用途!
15.3.5. LVM 的系统快照: 建立, 还原, 用于测试环境
现在你知道 LVM 的好处了,未来如果你有想要增加某个 LVM 的容量时,就可以透过这个放大、缩小的功能来处理。 那么 LVM 除了这些功能之外,还有什么能力呢?其实他还有一个重要的能力,那就是系统快照 (snapshot)。快照就是将当时的系统信息记录下来,就好像照相记录一般! 未来若有任何资料更动了,则原始资料会被搬移到快照区,没有被更动的区域则由快照区与文件系统共享。 用讲的好像很难懂,我们用图解说明一下好了:
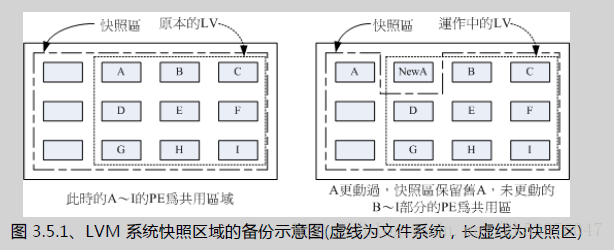
左图为最初建置系统快照区的状况,LVM 会预留一个区域 (左图的左侧三个 PE 区块) 作为数据存放处。 此时快照区内并没有任何数据,而快照区与系统区共享所有的 PE 数据, 因此你会看到快照区的内容与文件系统是一模一样的。 等到系统运作一阵子后,假设 A 区域的数据被更动了 (上面右图所示),则更动前系统会将该区域的数据移动到快照区, 所以在右图的快照区被占用了一块 PE 成为 A,而其他 B 到 I 的区块则还是与文件系统共享!
照这样的情况来看,LVM 的系统快照是非常棒的『备份工具』,因为他只有备份有被更动到的数据, 文件系统内没有被变更的数据依旧保持在原本的区块内,但是 LVM 快照功能会知道那些数据放置在哪里, 因此『快照』当时的文件系统就得以『备份』下来,且快照所占用的容量又非常小!所以您说,这不是很棒的工具又是什么?
那么快照区要如何建立与使用呢?首先,由于快照区与原本的 LV 共享很多 PE 区块,因此快照区与被快照的 LV 必须要在同一个 VG 上头。但是我们刚刚将 /dev/hda6 移除 vbirdvg 了,目前 vbirdvg 剩下的容量为 0 !因此,在这个小节里面我们得要再加入 /dev/hda6 到我们的 VG 后, 才能继续建立快照区!
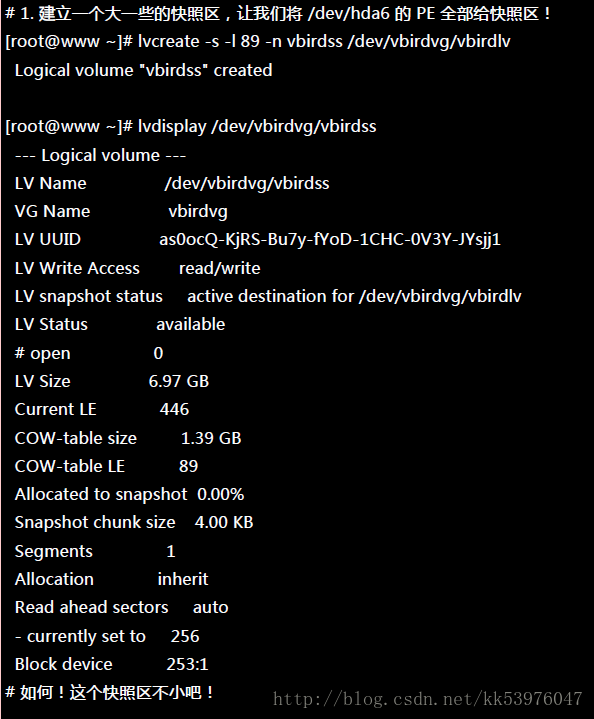
一、快照区的建立
底下的动作主要再增加需要的 VG 容量,然后再透过 lvcreate -s 的功能建立快照区
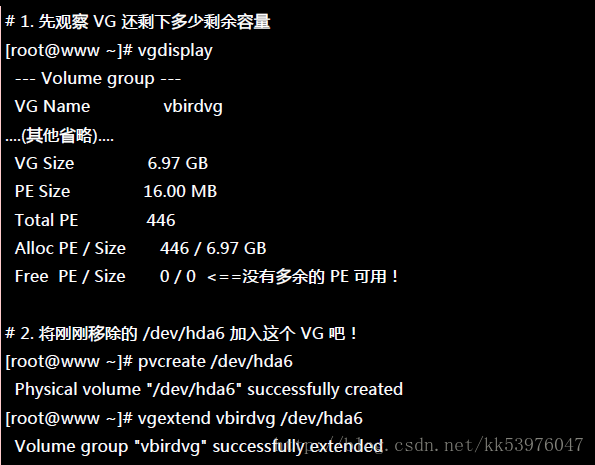
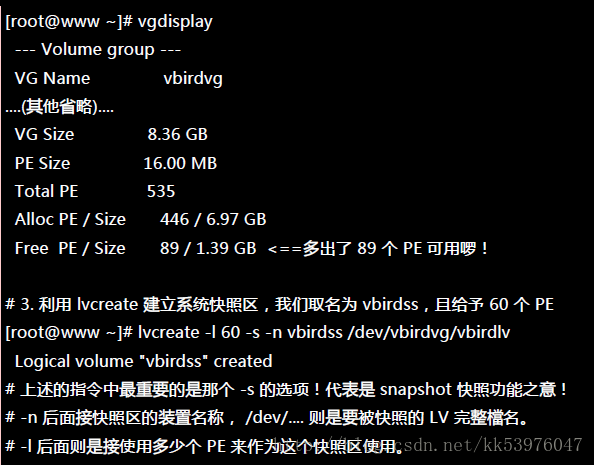
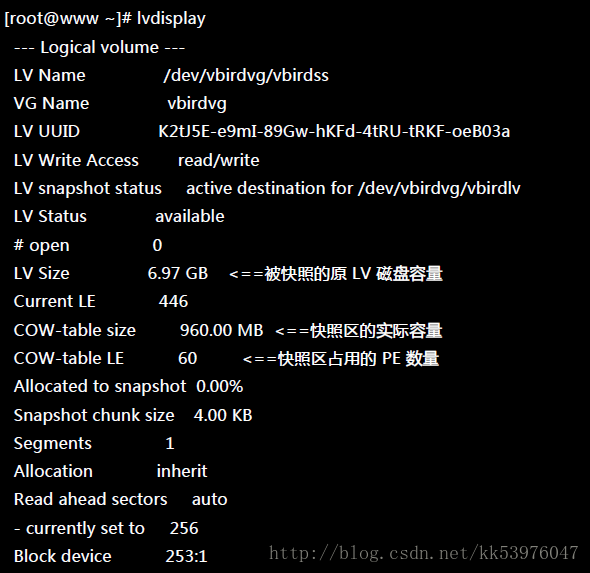
这个 /dev/vbirdvg/vbirdss 快照区就被建立起来了!而且他的 VG 量竟然与原本的 /dev/vbirdvg/vbirdlv 相同!也就是说,如果你真的挂载这个装置时,看到的数据会跟原本的 vbirdlv 相同!我们就来测试看看:
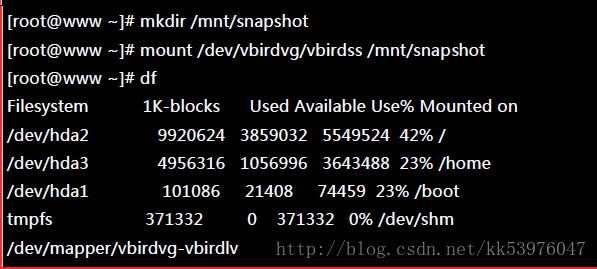
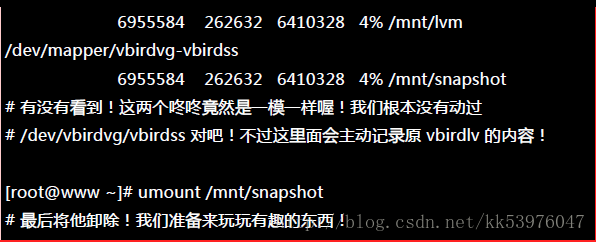
二、利用快照区复原系统
首先,我们来玩一下,如何利用快照区复原系统!不过你要注意的是,你要复原的数据量不能够高于快照区所能负载的实际容量。由于原始数据会被搬移到快照区, 如果你的快照区不够大,若原始资料被更动的实际数据量比快照区大,那么快照区当然容纳不了,这时候快照功能会失效! 所以上面的案例中才给予 60 个 PE (共 900MB) 作为快照区存放数据用。
我们的 /mnt/lvm 已经有 /mnt/lvm/etc, /mnt/lvm/log 等目录了,接下来我们将这个文件系统的内容作个变更, 然后再以快照区数据还原看看:
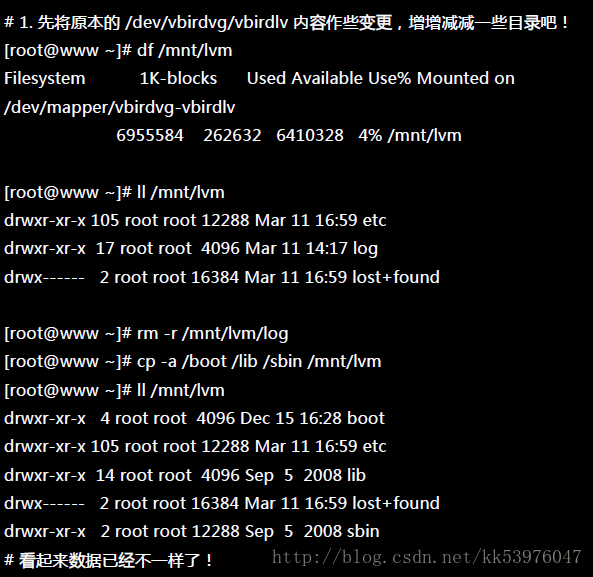
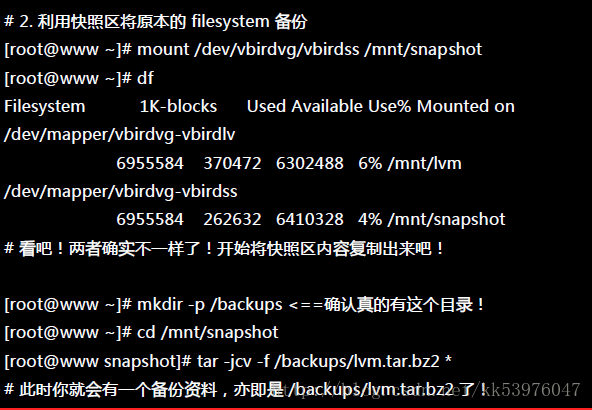
为什么要备份呢?为什么不可以直接格式化 /dev/vbirdvg/vbirdlv 然后将 /dev/vbirdvg/vbirdss 直接复制给 vbirdlv 呢? 要知道 vbirdss 其实是 vbirdlv 的快照,因此如果你格式化整个 vbirdlv 时,原本的文件系统所有数据都会被搬移到 vbirdss。 那如果 vbirdss 的容量不够大 (通常也真的不够大),那么部分数据将无法复制到 vbirdss 内,数据当然无法全部还原! 所以才要在上面表格中制作出一个备份文件的!
而快照还有另外一个功能,就是你可以比对 /mnt/lvm 与 /mnt/snapshot 的内容,就能够发现到最近你到底改了啥咚咚! 接下来让我们准备还原 vbirdlv 的内容吧!

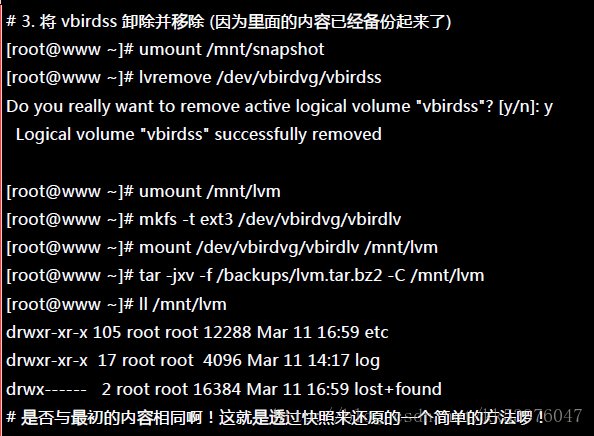
三、利用快照区进行各项练习与测试的任务,再以原系统还原快照
换个角度来想想,我们将原本的 vbirdlv 当作备份数据,然后将 vbirdss 当作实际在运作中的数据, 任何测试的动作都在 vbirdss 这个快照区当中测试,那么当测试完毕要将测试的数据删除时,只要将快照区删去即可! 而要复制一个 vbirdlv 的系统,再作另外一个快照区即可 !这样是否非常方便啊? 这对于教学环境中每年都要帮学生制作一个练习环境主机的测试,非常有帮助!
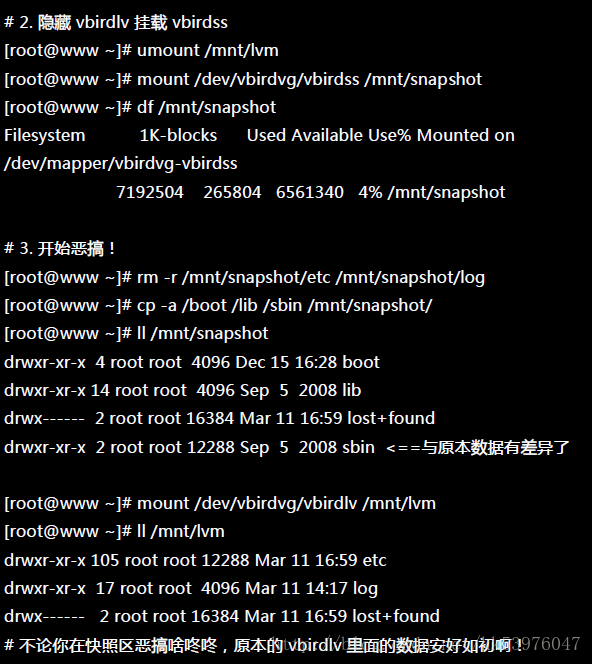

老实说,上面的测试有点无厘头~因为快照区损毁了就删除再建一个就好了!何必还要测试呢? 不过,为了让您了解到快照区也能够这样使用,上面的测试还是需要存在的!未来如果你有接触到虚拟机, 再回到这里来温习一下肯定会有收获的!
15.3.6. LVM 相关指令汇整与 LVM 的关闭
我们将上述用过的一些指令给他汇整一下,提供给您参考参考:
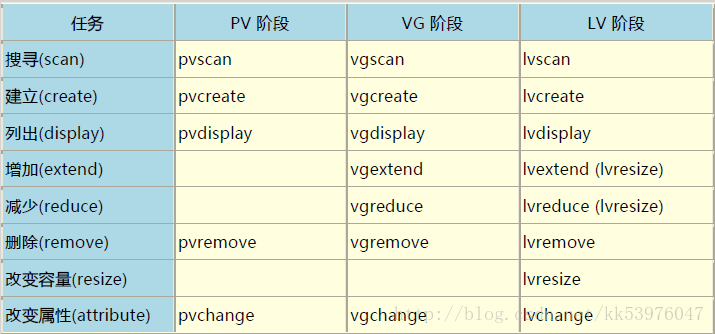
至于文件系统阶段 (filesystem 的格式化处理) 部分,还需要以 resize2fs 来修订文件系统实际的大小才行!至于虽然 LVM 可以弹性的管理你的磁盘容量,但是要注意,如果你想要使用 LVM 管理您的硬盘时,那么在安装的时候就得要做好 LVM 的规划了, 否则未来还是需要先以传统的磁盘增加方式来增加后,移动数据后,才能够进行 LVM 的使用!
会玩 LVM 还不行!你必须要会移除系统内的 LVM !因为你的实体 partition 已经被使用到 LVM 去, 如果你还没有将 LVM 关闭就直接将那些 partition 删除或转为其他用途的话,系统是会发生很大的问题的! 所以你必须要知道如何将 LVM 的装置关闭并移除才行! 依据以下的流程来处理即可:
- 先卸除系统上面的 LVM 文件系统 (包括快照与所有 LV);
- 使用 lvremove 移除 LV ;
- 使用 vgchange -a n VGname 让 VGname 这个 VG 不具有 Active 的标志;
- 使用 vgremove 移除 VG:
- 使用 pvremove 移除 PV;
- 最后,使用 fdisk 修改 ID 回来啊!
那就实际的将我们之前建立的所有 LVM 数据给删除吧!
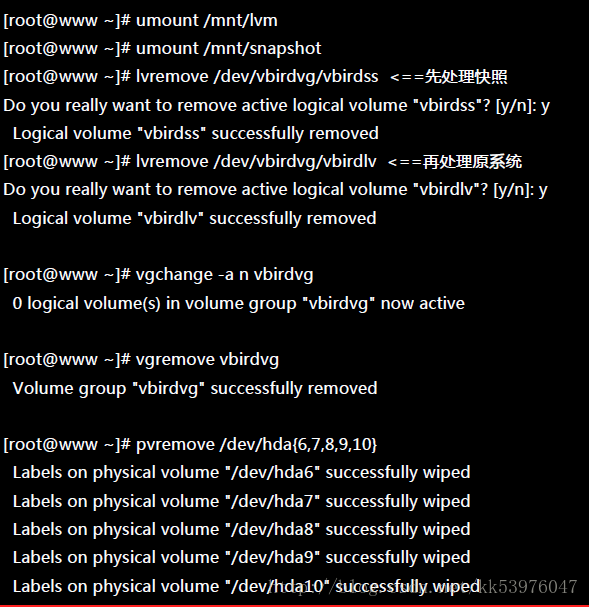
最后再用 fdisk 将磁盘的 ID 给他改回来 82 就好!整个过程就这样的啦!