操作版本:
jdk1.8 hadoop-2.7.4 hive-2.3.3
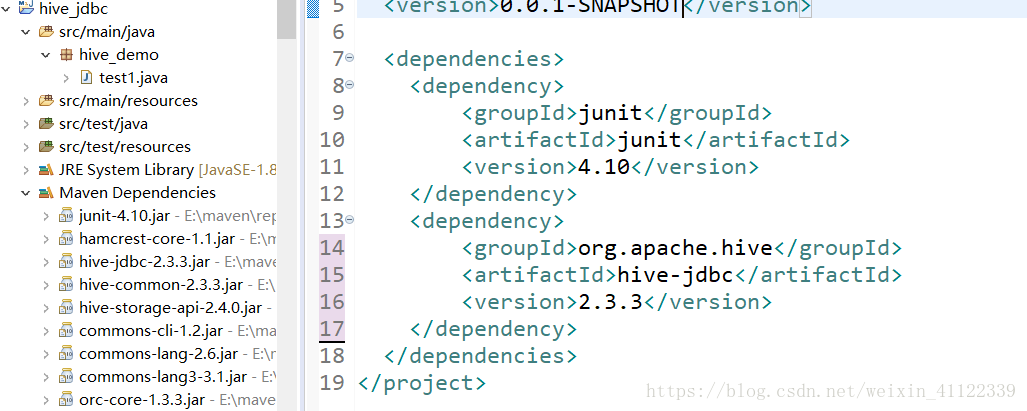
1,我们创建的maven项目在pom文件下添加依赖信息如下
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.3</version>
</dependency>
</dependencies>他会自动下载相应的hadoop依赖包好像是2.6的但这都没什么大问题,这可能会需要很长的时间
2,首先我们学过jdbc的同志们都知道连接jdbc都需要url和驱动hive也不例外
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn= DriverManager.getConnection("jdbc:hive2://192.168.14.128:10000");
相应的导包:
import java.sql.Connection;
import java.sql.DriverManager;3,其实后面的操作大家都可以很清楚了在这里我举两个例子一个没有结果集的sql和有结果集的
1,我们先来个简单的删除一个hive里的表
@Test
public void test_drop() throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn= DriverManager.getConnection("jdbc:hive2://192.168.14.128:10000");
Statement st = conn.createStatement();
st.execute("drop table zxz6");
st.close();
conn.close();
}2.现在我们再试试一个查询
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn= DriverManager.getConnection("jdbc:hive2://192.168.14.128:10000");
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("select * from zxz_5");
while(rs.next()) {
String name = rs.getString("name");
int nid = rs.getInt("nid");
String phone = rs.getString("phone");
Date ntime = rs.getDate("ntime");
int year = rs.getInt("year");
int month = rs.getInt("month");
System.out.println(name+","+nid+","+phone+","+ntime+","+year+","+month);
}
rs.close();
st.close();
conn.close();
}我们看看数据(是不是和jdbc一样的没什么变化):