女性对口红的上瘾只会迟到,不会缺席。

作为一个突然意识到自己是个女孩子的人,买口红是找不清方向的,所以不懈努力的去研究着各个美妆博主的账号。机缘巧合之下,得到了一份关于淘宝口红销售信息的数据资料,于是用R做了一个简单的数据统计。想看看那些所谓的“爆款”、“大热门”、“要断货”的口红究竟是不是真的,毕竟群众的眼光是贼亮的。
话不多说,简单描述一下数据,正如下边的表格所示,信息比较全面。
| 店名 | 描述分 | 价格分 | 质量分 | 服务分 | 标题 | 价格 | 总评价数 | 总销量 | 颜色 | 适合肤质 | 功效 | 防晒 | 保质期 | 规格类型 | 国家 | 是否进口 | 适合人群 |
首先我需要用两个包 RColorBrewer和 car,car包非常的强大,强大到我也说不出能干啥了,没事就加载用用吧。
install.packages("RColorBrewer")#安装包
install.packages("car")#安装包
library(RColorBrewer) #加载包
library(car)#加载包
data=read.csv("lipstick.csv", header=T, sep=',') #读取数据在这里提醒一句,记得选择镜像。接下来,让我们看一看到底有多少数据。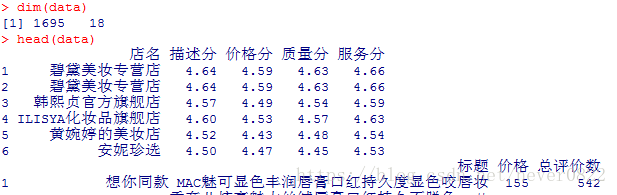
attach(data)#令人窒息的操作
par(mfrow=c(1,2))#设置画布
hist(总销量,main="",col="dark green",xlab="销量")#第一个图是关于总销量的直方图
hist(log(总销量),main="",col="dark green",xlab="对数总销量")#第二个图是总销量的对数直方图 解释一下为什么要画两个图,因为描述性统计分析的意义在于用图清晰的表达,而直接画的总销量直方图,因为销量最小和最大值的差距过大,而自动划分的组间距画出的图很不协调,所以做了一个小小的调整,虽然变成了对数值,但是趋势还是对的,下面的运行结果图片一目了然。
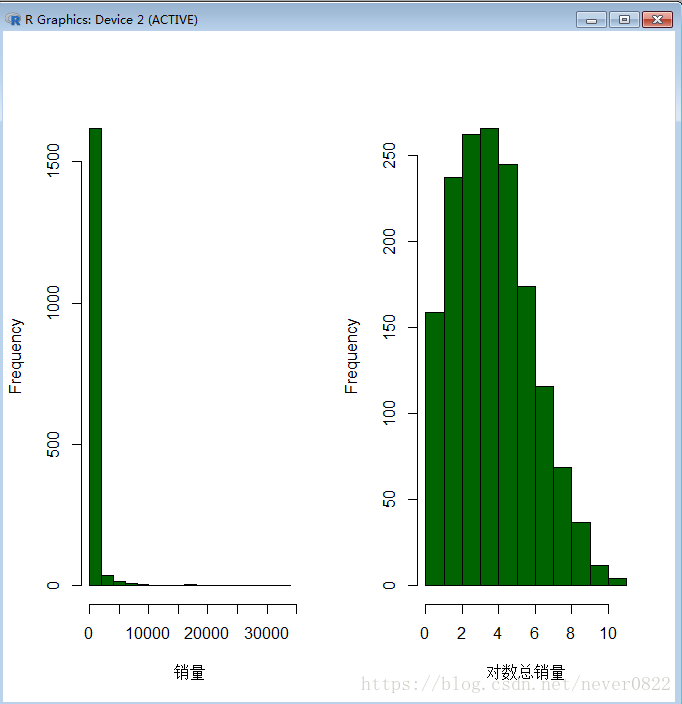
如图所示,这1692支来自不同店铺不同规格信息的口红,大部分的销量都是在1000支以内,而销量过万的口红并不多,这应该就是真正的爆款吧。接下来我想验证的是,是否国内的口红真的没有吸引力吗?买口红的人的第一选择会是国外大牌吗?所以,下一步让我们来看一看进口口红的号召力吧。
是否进口=factor(是否进口,order=T,levels=c("否","是","未知"))#把是否进口换成factor因子
boxplot(总销量~是否进口,xlab="是否进口",ylab="总销量")#画箱线图 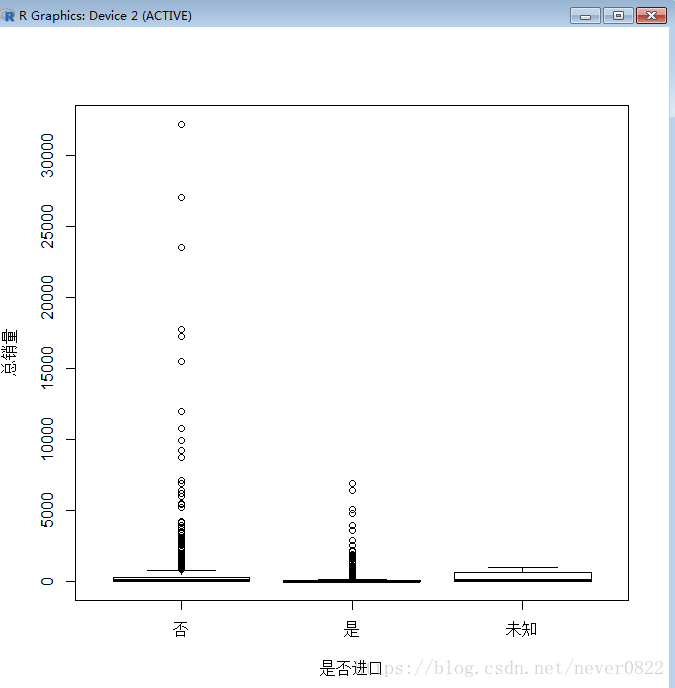
boxplot(总销量~国家,xlab="国家",ylab="总销量")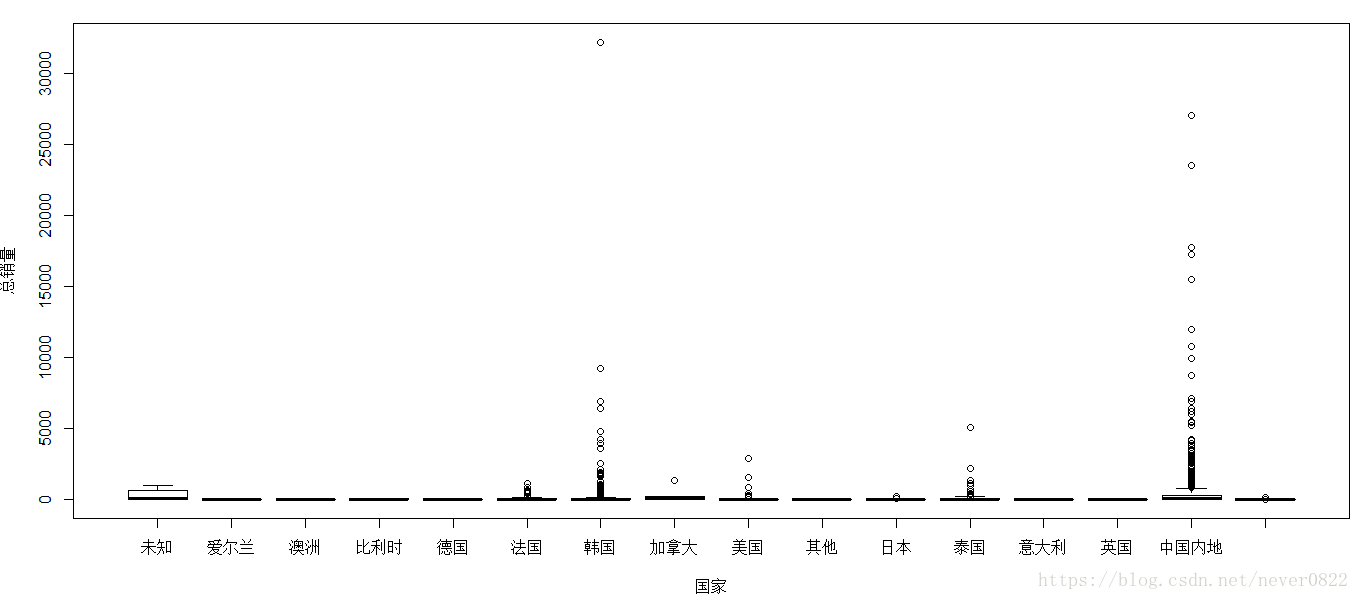
>themean=tapply(总销量,国家,mean)#计算不同国家的销量均值
。themean=sort(themean,decreasing=T) #排序
>themean
中国内地 未知 加拿大 韩国 泰国 美国
716.5625000 292.2857143 288.3333333 237.1372549 219.7260274 139.4259259
法国 比利时 中国台湾 德国 日本 意大利
109.8351648 41.0000000 35.8000000 19.5000000 16.9268293 14.3333333
英国 其他 爱尔兰 澳洲
9.0000000 8.5000000 3.5000000 0.3333333
>themean[themean>10]#选取销售均值大于10的口红作图
barplot(themean[themean>10],col="dark green",ylab="总销量",xlab="国家")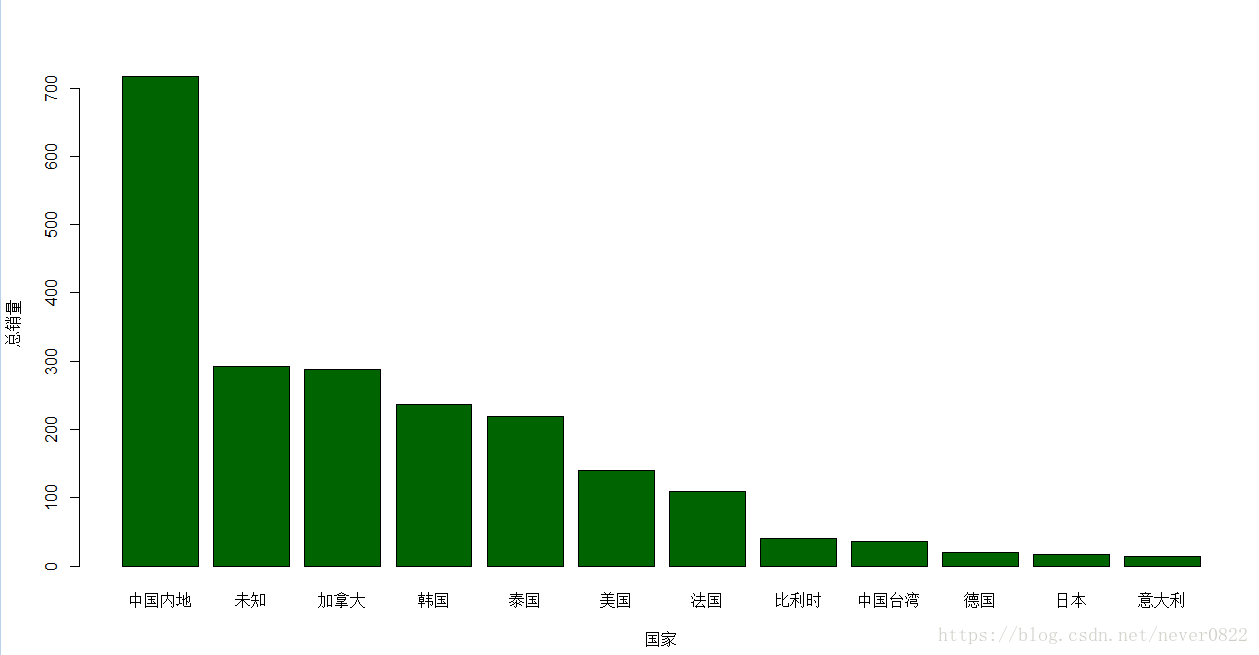
根据图片会发现一个特殊的存在---加拿大, 让我们再来看一下箱线图和条形图的对比
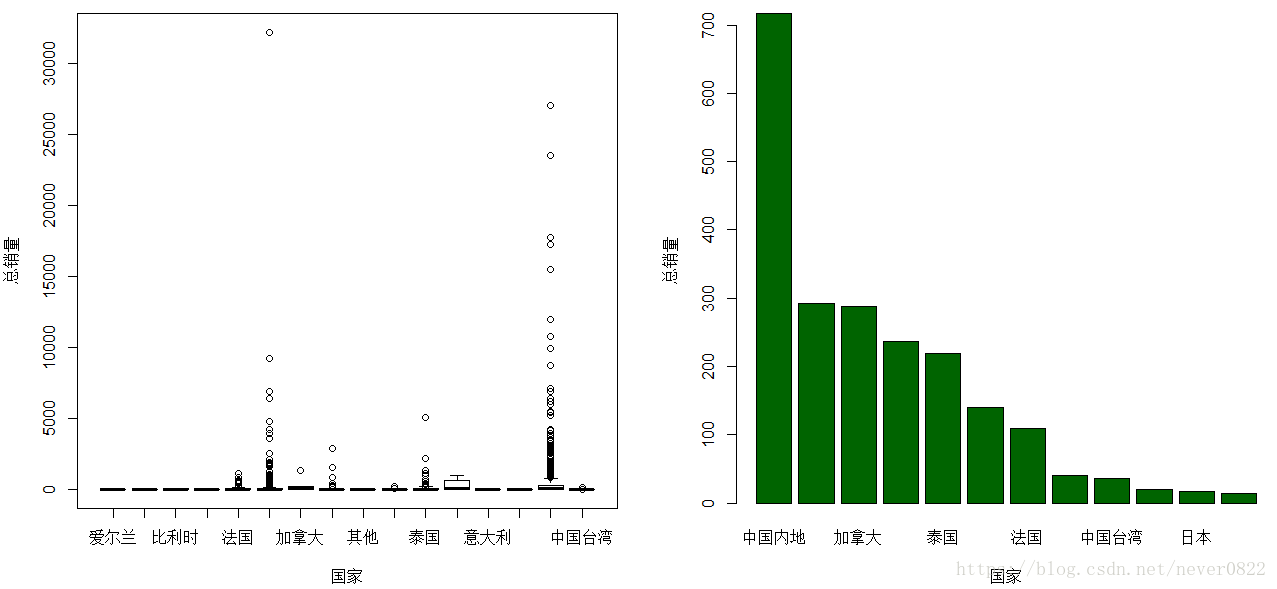
在加拿大上方有一个脱离群体的小圆圈,是否是因为这个点而影响了整体的均值呢?我们回到数据本身,查看一下。

在1695支口红中,只有6个的生产国是加拿大,所以基数是很小的,而上图显示的第一款口红销量为1327大大提高了整体的平均销量,除了说明平均销量的不靠谱,还说明电视剧中无形的植入广告是多么重要。这几款魅可口红只要标题中带了“想你同款”,评论和销量都遥遥领先。(科普:《想你》是尹恩惠主演的韩剧,号称收视率和口红色号双丰收的电视剧)附上剧照一张。
可惜的是,我和尹恩惠的差距不仅仅是一支口红,应该是2支、3支、4支.....O(∩_∩)O哈哈~ 话不多说,接下来又对于规格类型和保质期做了简单的箱线图,估计这并不是大家买口红的重点,并没有出人意料的结果。
par(mfrow=c(1,2))
boxplot(总销量~规格类型,col="dark green",xlab="规格类型",ylab="总销量")
boxplot(总销量~保质期,col="dark green",xlab="保质期",ylab="总销量")
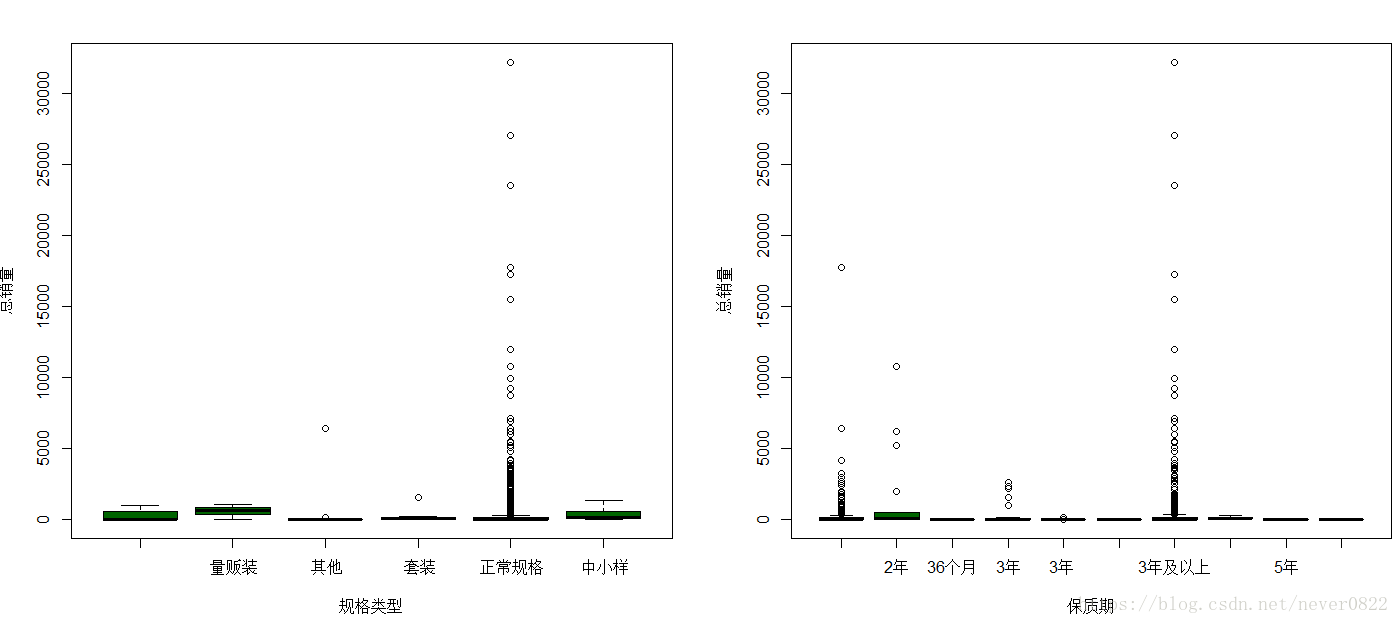
三年及以上是大部分口红的保质期,而正常规则是绝大数人的选择,同样限量版和中小样的口红依然具有一定的号召力。要说一个事实,很少有人可以用完一支口红,如果是为了尝鲜和试色,中小样是一个很好的选择。对于我这样善于精打细算的贫民窟女孩,口红的价格绝对是一个重要的参考信息,所以首先用直方图来看一下口红的价格区间。
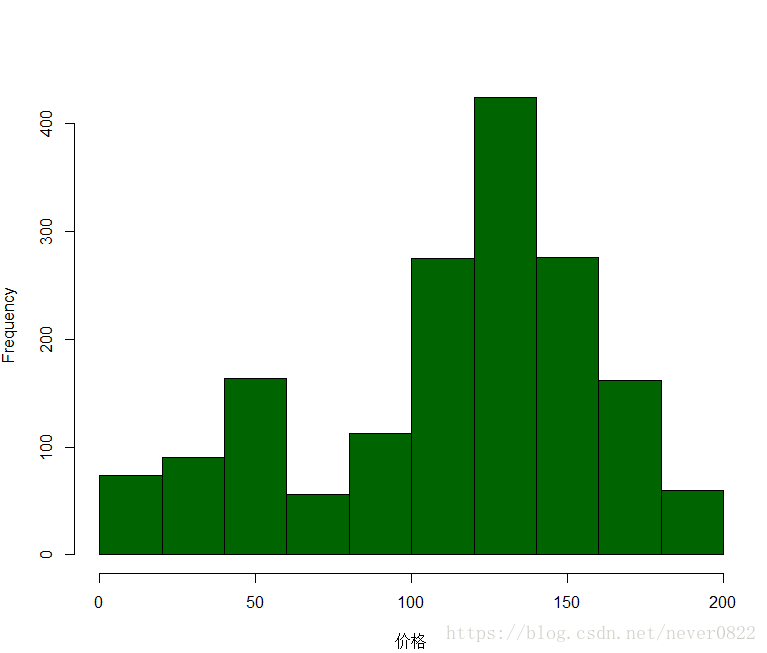
根据收集的数据,我们能够在上图看出,口红的定价绝大多数都在0-200元之间,所以买口红并不是一个败家的行为!
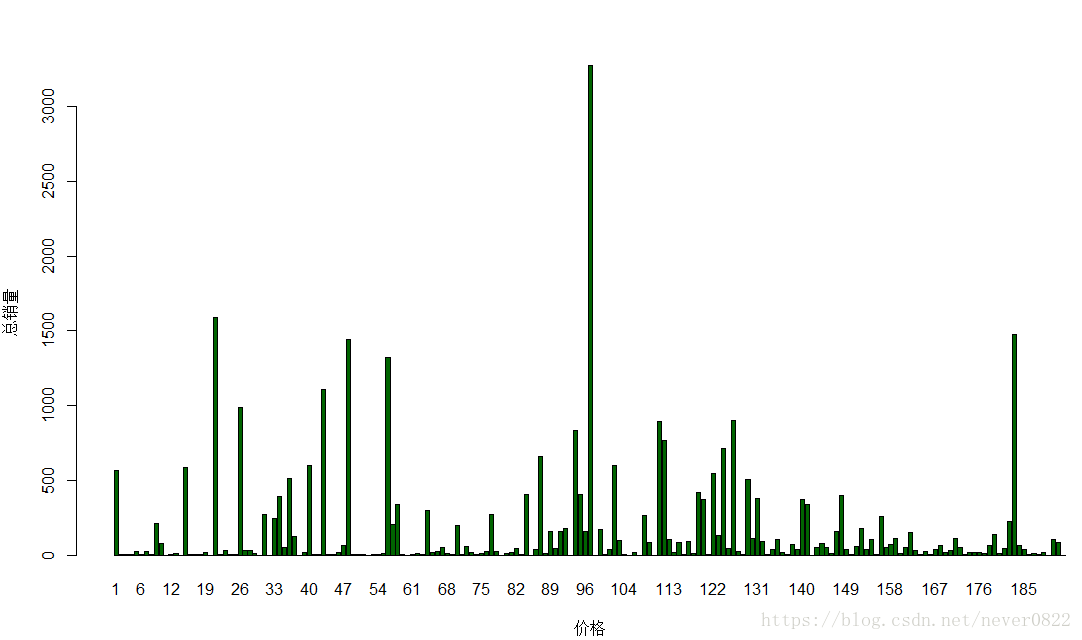
那么什么价位的口红最适合呢?还是选择了不同价位 的平均销量,可以看到百元口红是最多的选择,也就是说按照大家的选择标准,100-150 的口红似乎是性价比最高的。
当在淘宝购物时,评价往往会影响我们的决策,通常评价数量越多我们越能发现真实的口碑,接下来是评价对销售的影响。
par(mfrow=c(1,2))
hist(总评价数,main="",xlab="总评价数",col="dark green")#评价数目的直方图
评价质量=rep("低",N)#定义评价质量这里的N是1695
评价质量[总评价数>1000]="高"
boxplot(总销量~评价质量,col="dark green",xlab="评价质量",ylab="总销量")
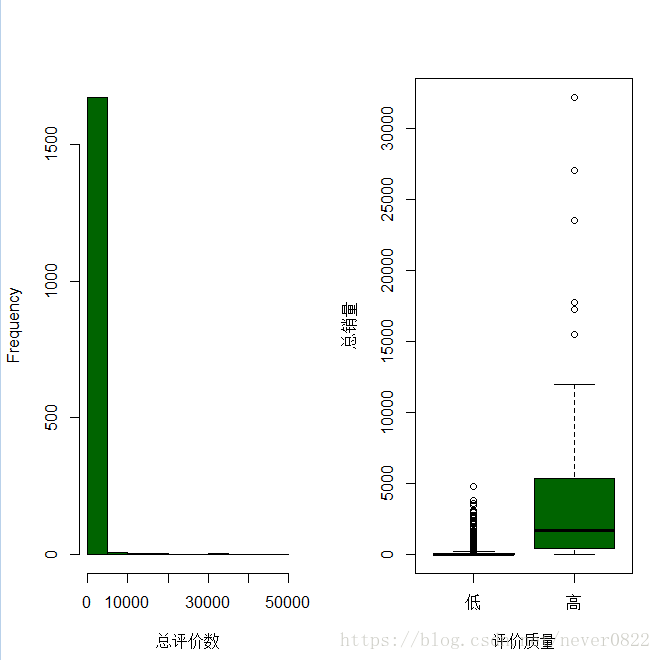
如图所示,评价数量多的口红占有压倒性的优势,是不是说商品评论区种草的威力不容小觑呢?因为数据中收集了描述、质量、服务、价格分数,所以对评价进行进一步分析。
par(mfrow=c(1,4))
hist(描述分,main="",col="dark green")
hist(价格分,main="",xlab="价格分",col="dark green")
hist(质量分,main="",xlab="质量分",col="dark green")
hist(服务分,main="",xlab="服务分",col="dark green")
描述=rep("低",N)
描述[描述分>4.5]="高"
价格=rep("低",N)
价格[价格分>4.5]="高"
质量=rep("低",N)
质量[质量分>4.5]="高"
服务=rep("低",N)
服务[服务分>4.5]="高"
boxplot(总销量~描述,col="dark green",xlab="描述",ylab="总销量")
boxplot(总销量~价格,col="dark green",xlab="价格",ylab="总销量")
boxplot(总销量~质量,col="dark green",xlab="质量",ylab="总销量")
boxplot(总销量~服务,col="dark green",xlab="服务",ylab="总销量")
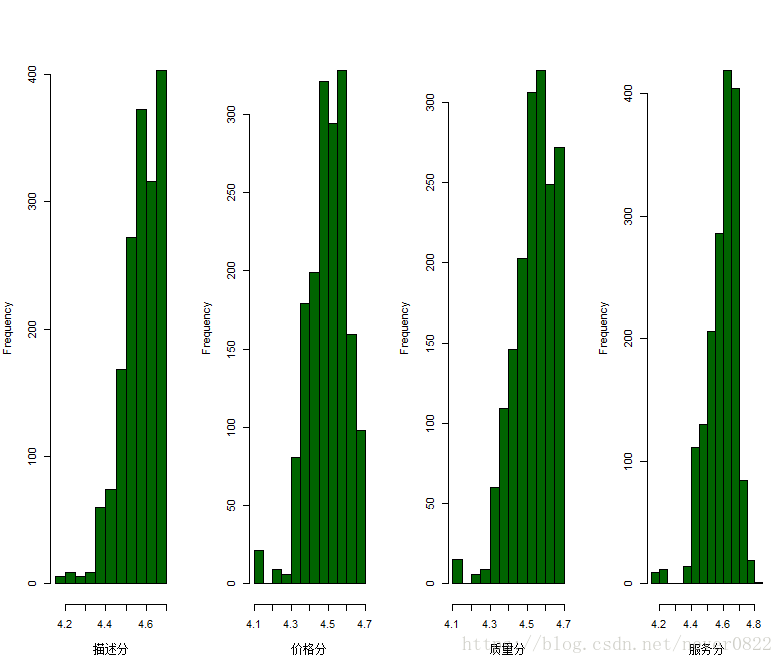
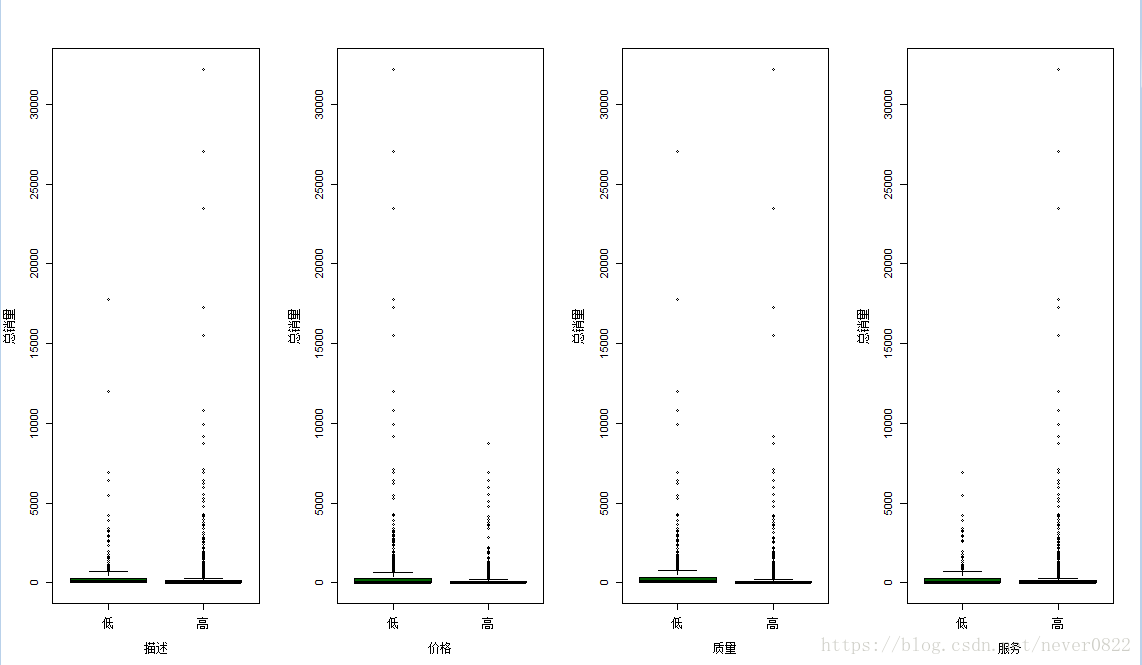
根据图一,可以看出这四个度量的评分中位数都在4.4右侧,5分为满分,所以总体讲这些商品各项指标是令人满意地。正如 代码所示,我把4.5分作为区分高低的标准。分别做图,看一下各项指标对于销量的影响,结果如图二所示。可以看到,服务分数低的商品销量远远落后于服务高的商品,所以良好的购物体验,心情占据绝对位置;同样的,描述分数的高低对应着契合程度,绝大部分人购物是通过标题搜索,实物描述一致才能更好的销售;比较有意思的是,质量高低不同的产品,销量竟然不分伯仲,这个中缘由十分值得深思,是恶意评论,还是要求太高,还是什么其他原因?另外对于价格而言,价格较低的口红销量超过了价格高的口红,说明产品的定价值得商家好好研究,并不是说几十块的口红堪比大牌,只是质量过硬、价格合理的才是销量最高的。尤其是,每一个淘宝卖家与其争相返利求好评倒不如先做产品。
为了,更好的发现销量和各项指标的关系,我打算做一个回归分析,经过各种拟合得出一个多元线性回归模型。但是,由于本人能力有限,所以这个想法,卒。