知识点梳理:
小麦种类预测:
打乱分离集和结果集,源码办法
年收入预测:
样本字符串转数字
癌症预测:
打乱分离集和结果集自带函数,样本数据归一化
一、小麦种类预测
1)处理数据
1、导入数据
samples = pd.read_table('./data/wheats.tsv',header=None)
samples
samples.shape
(210, 8) #共210个样本数据2、打乱分离训练集和结果集
samples = np.random.permutation(210) #打乱210个样本的顺序,样本的值不变
samples.iloc[:,0:7]
data = samples.iloc[:,:-1] # 从 最开始 到 最后的 最后的取不到
target = samples[7] # df直接传入索引 是对列的索引
target3、提取训练集和测试集
训练集为190个之前的
测试集为190个之后的
X_train = data[:190]
y_train = target[:190]
# 测试数据
X_test = data[190:]
y_test = target[190:]2)创建训练模型并训练
knn = KNeighborsClassifier(n_neighbors=13) #测试得到n_neighbors = 13的测试准确率较大
knn.fit(X_train,y_train)3)使用模型预测结果
y_ = knn.predict(X_test)4)查看模型准确率
knn.score(X_test,y_test)
0.9二、预测年收入是否大于50K美元
1)处理数据
1、导入数据
df = pd.read_csv('./data/adults.csv')
df
df.shape
(32561, 15) #共32561个样本数据2、获取特征与目标值
data = df.loc[:,['age','education','occupation','hours_per_week']] #特征
target = df['salary'] #目标值3、数据处理
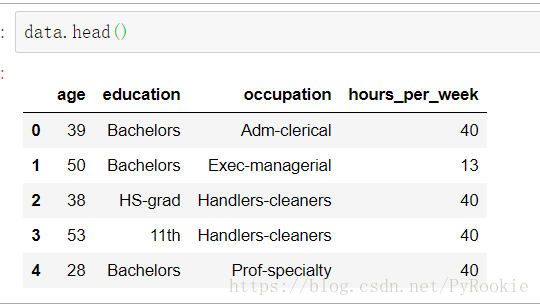
data
这里的数据类型为字符串,机器不能处理这些数据,我们应将这些数据转换为数字
将所有字符串的列,转换成相应的值让机器去学习
levels = data['education'].unique()
levels #输出所有的不重复的种类
array(['Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'], dtype=object)levels=='Bachelors'
array([ True, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False])np.argwhere()
通过np.argwhere找到这一项 在levels中的索引号 这个索引号就是编号 把找到的编号返回即可
np.argwhere(levels=='Bachelors')
array([[0]], dtype=int64)定义一个函数,将这些类转换为相应的索引值,这样就把字符串的各个类转换为数字,供机器学习。
def str2int(item):
return np.argwhere(levels==item)[0,0]在通过map()函数将我们定义好的函数去处理每一个值,将其转换为数字。
data.education = data.education.map(str2int) #将data里education这一列中的所有元素经过str2int函数处理data.dtypes
age int64
education int64 #这样,字符串就会转换成数字类型。
occupation object
hours_per_week int64
dtype: object4、将处理数据封装为函数
函数功能:传入DataFrame和要转换的列的名字 就把这个列的字符串变成数值
def transform_dtype(df,column_name):
# 看看传入的df中指定的这一列 有哪些独特的值
u = df[column_name].unique()
def str2int(item):
return np.argwhere(u==item)[0,0]
# 传入的df的指定列 使用map做映射
df[column_name] = df[column_name].map(str2int)
4、使用我们定义好的函数处理其他未处理的数据
transform_dtype(data,'occupation')data.dtypes
age int64
education int64
occupation int64
hours_per_week int64
dtype: object这样我们就将所有的字符串类型转换成了数字类型
5、提取训练数据和预测数据
X_train = data[:30000] #前三万条数据进行训练
y_train = target[:30000]
X_test = data[30000:] #后三万条数据进行测试
y_test = target[30000:]6、
7、
8、
2)创建训练模型并训练
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)3)使用模型预测结果
y_ =knn.predict(X_test)
y_4)查看模型准确率
knn.score(X_test,y_test)
0.7645450995704803三、癌症预测
1)处理数据
1、导入数据
cancer = pd.read_table('./data/cancer.tsv')
cancer.head()
df.shape
(569, 32) #共569个样本数据2、获取特征与目标值
data = cancer.iloc[:,2:] # 所有样本的特征列
target = cancer.iloc[:,1] # 所有样本的标签
# target目标值中,M恶性,B良性,没事儿3、数据打乱顺序并分为训练集和测试集
from sklearn.model_selection import train_test_split
功能:train_test_split 这个函数直接就可以把 数据集 分成 训练集和测试集 而且还会打乱顺序
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.33,random_state=42)
'''
X 特征数据集
y 结果集合
test_size:测试集占所有数据的比例(其他的就是训练集)
random_state:打乱顺续的程度
返回值:分别是X_train, X_test, y_train, y_test这样的顺序
'''
X_train, X_test, y_train, y_test = train_test_split(data,target,test_size=0.1,random_state=42)2)创建训练模型并训练
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)3)使用模型预测结果
y_ = knn.predict(X_test)4)查看模型准确率
knn.score(X_test,y_test)
0.96491228070175445)使用交叉表查看预测值与实际值的个数
y_test.head()
89 B
171 M
366 M
325 B
381 B
Name: Diagnosis, dtype: objecty_
array(['B', 'M', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B',
'M', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B',
'M', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'M',
'B', 'B', 'B', 'M', 'M'], dtype=object)pd.crosstab(y_,y_test,rownames=['predict'],colnames=['real']) #注意,rownames和colnames需要传入列表
real B M
predict
B 39 1
M 1 16
# 可以看出真正 (M为恶性 B为良性)
#预测良性,对了39个,错了1个
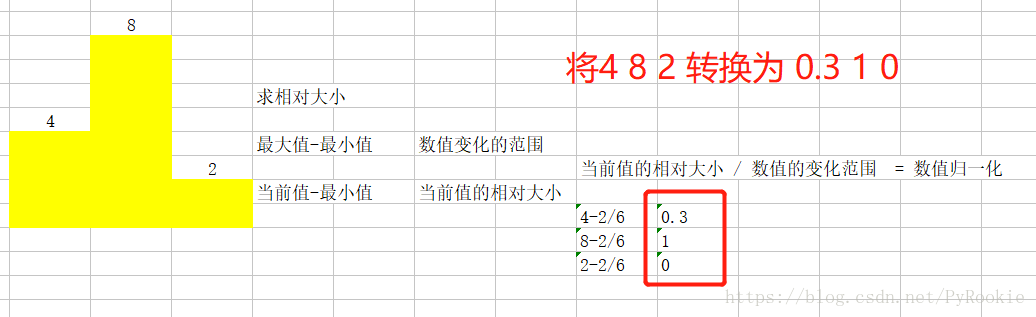
#预测恶性,对了16个,错了1个6)将各个范围的值归一化
我们可以看出在data里有的数据值太大,因此会对预测结果产生影响,因此我们将这些值统一成0-1之间的值
实现原理:
1、数据归一化处理
这里数据有很多列
data.columns #列出所有的列
Index(['radius_mean', 'texture_mean', 'perimeter_mean', 'area_mean',
'smoothness_mean', 'compactness_mean', 'concavity_mean', 'concave_mean',
'symmetry_mean', 'fractal_mean', 'radius_sd', 'texture_sd',
'perimeter_sd', 'area_sd', 'smoothness_sd', 'compactness_sd',
'concavity_sd', 'concave_sd', 'symmetry_sd', 'fractal_sd', 'radius_max',
'texture_max', 'perimeter_max', 'area_max', 'smoothness_max',
'compactness_max', 'concavity_max', 'concave_max', 'symmetry_max',
'fractal_max'],
dtype='object')我们将这些列都进行归一化处理
for cols in data.columns:
# print(cols)
# data[cols] 是 每一列数据
data_max = data[cols].max()
data_min = data[cols].min()
# data[cols]-data_min 这个Series里面的每一个值都减去data_min
# 每一个值都这样计算 然后在重新赋值给这一列
data[cols] = (data[cols]-data_min)/(data_max-data_min)2、数据打乱顺序并分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data,target,test_size=0.1)3、创建训练模型并训练
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)4、使用模型预测测试样本
y_ = knn.predict(X_test)5、查看准确率
knn.score(X_test,y_test)
0.94736842105263156、使用交叉表查看预测值与实际值的个数
pd.crosstab(y_,y_test,rownames=['predict'])
Diagnosis B M
predict
B 33 3
M 0 21
# 可以看出真正 (M为恶性 B为良性)
#预测良性,对了33个,错了3个
#预测恶性,对了21个,错了0个