1. 3D CNN
1.1. C3D16
直接将vgg扩展为3d形式,参数较多。

1.2. 3D Resnet v117
将resnet直接扩展为3d,未预训练的模型在小训练集(activitynet)上效果不好,大训练集(kinetics)上效果好。

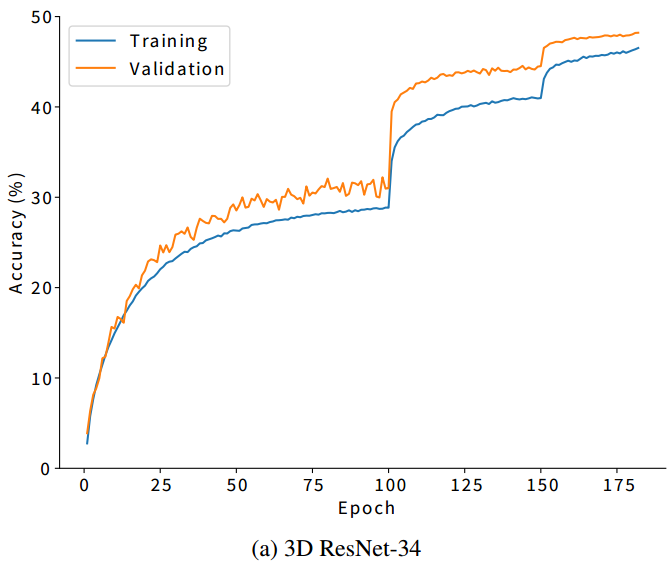
Resnet3d与2d结构主要区别在于时间维度上的缩减要慢一些

细节:采用16帧,均值采样后在附近随机采样进行augmented,空间上在四个角和中间采crop,并使用multiscale技术18,将原图多尺寸crop后scale到最终需求。
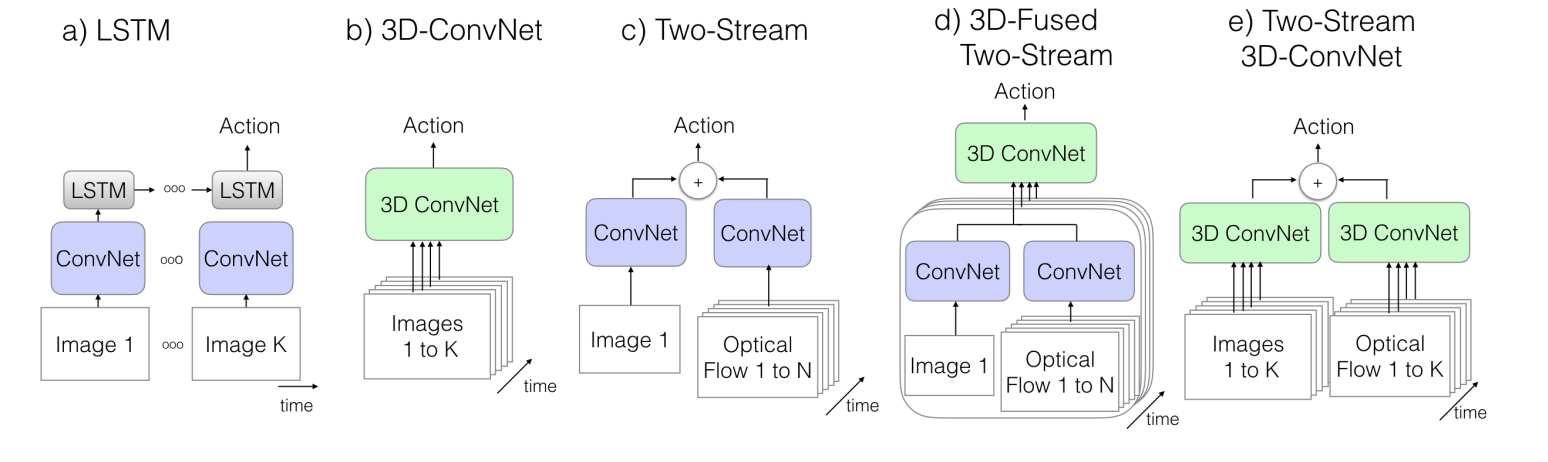
在文章19中有一个对这些技术的对比,同时,这篇文章提出clip length对结果影响很大。
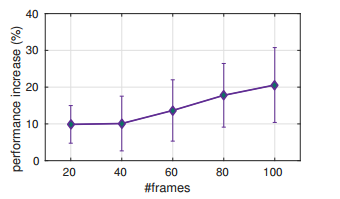
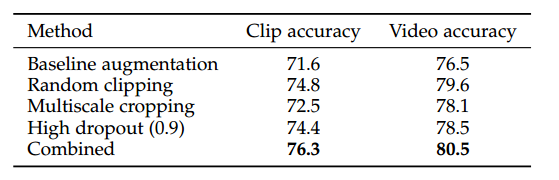
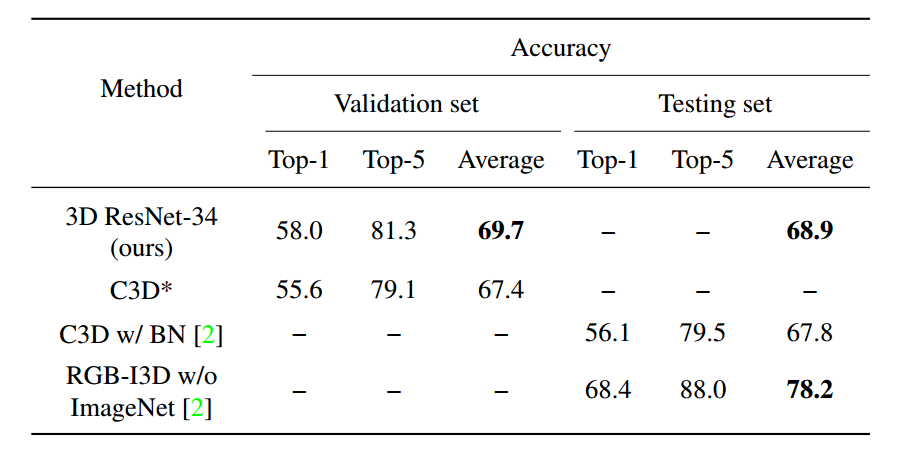
另外,本文提供了pretrained模型,基于torch的resnet18和resnet34,转换为pytorch的方法在我的github上有(https://github.com/lshiwjx)。而且作者最近在写pytorch版本的。
1.3. 3D Resnet v220
本文主要对3d resnet的基础设置进行了寻找。结构上去掉了5.2中的max pool。
结果为:resnet18优于34,一个clip最好在0.25-0.75s之间,以8frame为一个clip,resize与crop为128à112,采样率为每隔2到4帧采一次(30fps)。
模型大小上:Res3Dis about 2 times smaller and also 2 times faster than C3D. Res3D has 33.2 millionparameters and 19.3 billion FLOPs while C3D has 72.9 million parameters and38.5 billion FLOPs.

本文的结果我认为需要longterm modeling的支持,clip太短了。
1.4. 3D Inception21
本文对inception v1进行了3d扩展,并使用了光流提取的特征。
有一些结果图比较好:

1.5. 3D Inception-resnet22
对inception-resnet进行了扩展用于人表情识别,细节缺失
Reference:
16. DuTran, Bourdev, L., Fergus, R., Torresani, L. & Paluri, M. Learningspatiotemporal features with 3d convolutional networks. inProceedings ofthe IEEE International Conference on Computer Vision 4489–4497 (2015).
17. Hara,K., Kataoka, H. & Satoh, Y. Learning Spatio-Temporal Features with 3DResidual Networks for Action Recognition.ArXiv170807632 Cs (2017).
18. Wang,L., Xiong, Y., Wang, Z. & Qiao, Y. Towards good practices for very deeptwo-stream convnets.ArXiv Prepr. ArXiv150702159 (2015).
19. Donahue,J. et al. Long-term recurrent convolutional networks for visualrecognition and description. inProceedings of the IEEE conference oncomputer vision and pattern recognition 2625–2634 (2015).
20. Tran,D., Ray, J., Shou, Z., Chang, S.-F. & Paluri, M. ConvNet ArchitectureSearch for Spatiotemporal Feature Learning.ArXiv170805038 Cs (2017).
21. Carreira,J. & Zisserman, A. Quo Vadis, Action Recognition? A New Model and theKinetics Dataset.ArXiv Prepr. ArXiv170507750 (2017).
22. Hasani,B. & Mahoor, M. H. Facial Expression Recognition Using Enhanced Deep 3DConvolutional Neural Networks.ArXiv Prepr. ArXiv170507871 (2017).