参考文章:
https://blog.csdn.net/u014374284/article/details/49205885 MapReduce shuffle过程详解
https://iclouding.github.io/2017/06/14/MapReduce%20%E5%85%A8%E6%8E%92%E5%BA%8F/ MapReduce 全排序
https://www.zhihu.com/question/27593027 MapReduce 处理数据倾斜
MapReduce 的Shuffle 过程
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。
Map是映射,负责数据的过滤分发,将原始数据转化为键值对(K,V);
Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
Shuffle 是为了让Reduce可以并行处理Map的结果,对Map输出进行进一步整理(排序与分割)再交给Reduce的过程。
Shuffle过程包含在Map和Reduce两端,即 Map shuffle 和 Reduce shuffle
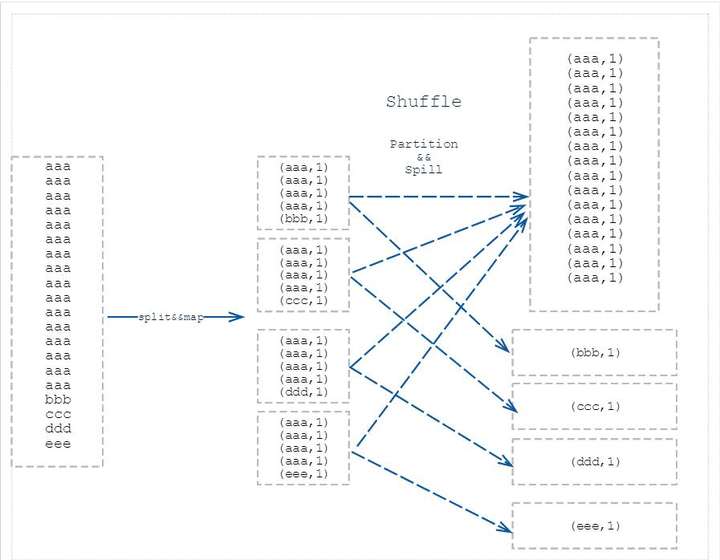
在Map端的shuffle过程是对Map的结果进行:
Partition 分区
对于map输出的每一个键值对,系统都会给定一个partition,partition值默认是通过计算key的hash值后对Reduce task的数量取模获得。如果一个键值对的partition值为1,意味着这个键值对会交给第一个Reducer处理。Sort & Spill 排序和溢写 [Combiner]
Map的输出结果是由collector处理的,每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中(Kvbuffer,包括kv 数据及其索引)。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
Kvbuffer的容量都是有限的,键值对和索引不断地增加,加着加着,Kvbuffer总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill。Spill的门限可以通过io.sort.spill.percent,默认是0.8 即当 Kvbuffer 占用80%以上的时候就触发 Spill 线程。在执行Spill之前还有个Sort。
Sort是先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill线程根据排过序的Kvmeta挨个partition的把数据吐到磁盘文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。在这个过程中如果用户配置了 combiner 类,那么在写之前会先调用combineAndSpill(),对结果进行进一步合并后再写出。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?从参考作者Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。
扫描二维码关注公众号,回复: 2872520 查看本文章
- Merge 合并
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。merge就是把这些文件进行合并的过程。
Merge 是通过扫描索引,对每个partition对应的所有的segment进行合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并。
在Reduce端,shuffle主要分为复制Map输出、排序合并两个阶段。
Copy 拷贝
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。Merge&Sort 归并和排序
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
MapReduce 全排序问题(全局有序)
每一个Reduce的输出都是有序的,但是将所有Reduce的输出合并到一起却并非是全局有序的,如何做到全局有序呢?
- 只使用一个 Reduce task ,但这样做就 Reduce 不再是并行,因此发挥不会集群的作用。
- 自定义分区函数,实现全局有序(要有经验) 自己根据处理数据key的分布,合理将key按照范围发送到对应的reduce:如key<100的发送给reduce0,1000 <= key < 200的发送给reduce1, key >=2000的发送给reduce3…
- 使用TotalOrderPartition进行全排序: 使用一个reduce,在数据量大的时候,容易造成OOM
自定义分区函数实现全排序,出现数据倾斜的概率大 使用TotalOrderPartitioner全排序
MapReduce默认使用HashPartitioner来实现
MapReduce 数据倾斜的处理
什么是数据倾斜
数据倾斜就是数据的 key 的分化严重不均,造成一部分 Reduce 数据很多,一部分数据 Reduce 很少的负载不均衡的问题。
比如:(盗图)
产生数据倾斜的原因
- 分组:group by 维度过小,某值的数量过多
- 去重 distinct count(distinct xx)情形:某特殊值过多
- 连接 join
- 其中一个表较小,但是key集中
- 大表与大表,但是分桶的判断字段0值或空值过多
如何处理数据倾斜问题
- 两层 MapReduce
第一层 MapReduce 阶段先将倾斜的 key 随机分发到不同的 Reduce 实现负载均衡,紧接着第二层再将相同的 key 的 value 合并,这里的第一层可以对倾斜的 key 进行简单处理,比如加个后缀,然后第二层再将后缀去掉。 - 在Map阶段定义 Combiner (针对部分任务,导致数据倾斜的 key 大量分布在不同的Map task 中)
Map 中定义combiner相当于提前进行reduce,就会把一个mapper中的相同key进行了聚合,减少shuffle过程中数据量以及reduce端的计算量。 - 配置参数 (应该是针对 Hive 查询)
hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存。
hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob
中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy
Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy
Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。- 两层 MapReduce