一、概述
这种方式来自于论文Deep Sentence Embedding Using Long Short-Term Memory Networks,简单的来说应该是一种生成句向量的方法。
二、思路
论文中作者对比了很多相关工作,总而言之就LSTM-RNN这种方法相对而言有很大优势,这里就不列出来了。
1、基本方法
基本想法是将文本序列转化为向量,然后利用LSTM-RNN的结构进行抽取转换,得到的最后一层hidden输出就为句向量,再通过句向量进行距离计算操作,如下:
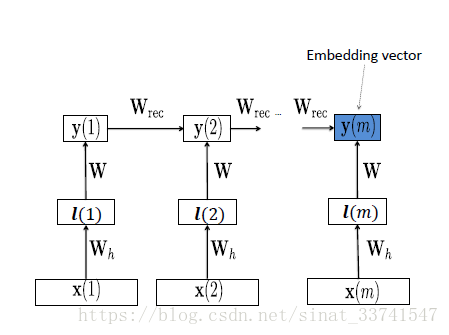
2、流程
(1)文本转化为向量
作者提出了一种tri-gram的方法,简而言之就是通过窗口对词进行截取,将每个词转化为n个3 letter大小的片,再进行向量计算,最后规整为词向量。
这种方法看上去很莫名其妙,但按作者的说法,效果还不错。
但相对的,如果我们采用预训练的w2v模型,应该也能起到相同的效果。
(2)LSTM
文中对比了使用LSTM和直接用RNN的模型,相对而言使用LSTM的效果会更好,由于LSTM有很多变种,下面贴一下论文使用的结构:
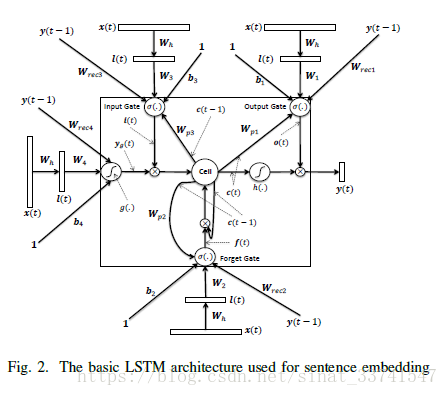
从结构上,应该就是经典的LSTM再加上peephole,相应的计算公式如下:
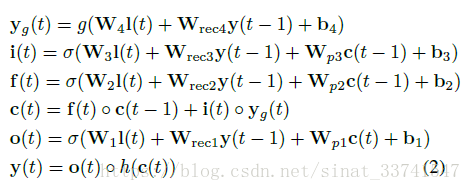
是输入信息,
是输入门,
是遗忘门,
是当前lstm状态,
是输出门,
是隐藏层输出的形式化写法,也即是最后得到的句向量。
(3)匹配
通过LSTM得到句向量之后,就是针对句向量进行的一系列对比工作了,进行距离计算,或者将句向量作为中间层,继续输入到下一个模型等等。