LinkedHashMap:重要的成员变量以及构造方法
public class LinkedHashMap<K, V> extends HashMap<K, V> {
/**
* 头节点,这是一个很重要的节点,用来维护一个双向循环链表
*/
transient LinkedEntry<K, V> header;
/**
* True if access ordered, false if insertion ordered.
* 关系到LinkedHashMap的排序方式,也决定了那个元素会是最近最少使用的元素。
* 稍后我会详细的说一下true和false对于排序方式的区别。
*/
private final boolean accessOrder;
/**
* 无参构造,注意accessOrder 默认是false
*/
public LinkedHashMap() {
init();
accessOrder = false;
}
/**
*最终调用了3个参数的构造方法
*/
public LinkedHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
*最终调用了3个参数的构造方法
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, false);
}
/**
*调用了super也就是父类HashMap的2参构造,同时跟无参构造一样调用了init方法和对于accessOrder的赋值方法
*/
public LinkedHashMap(
int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
}
//初始化了个LinkedEntry实例header
@Override void init() {
header = new LinkedEntry<K, V>();
}
}LinkedEntry 和 HashMapEntry :
/**
* LinkedEntry
*/
static class LinkedEntry<K, V> extends HashMapEntry<K, V> {
LinkedEntry<K, V> nxt;
LinkedEntry<K, V> prv;
/** Create the header entry */
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
/** Create a normal entry */
LinkedEntry(K key, V value, int hash, HashMapEntry<K, V> next,
LinkedEntry<K, V> nxt, LinkedEntry<K, V> prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}
/**
* HashMapEntry
*/
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
}通过对比我们发现LinkedEntry的构造方法中调用了super(key, value, hash, next); 同时还增加了两个新的特有属性 nxt 和 prv。如果来记得我之前关于LinkedList的源码解析的那篇文章的话,就大致可以猜到这两个属性是干什么的,没错就是引用元素前后其他元素的,也就是指针。

还记得上一篇中我使用★来包裹的函数吗,这里我也贴出来作比较,来看一看LinkedHashMap和HashMap的区别
/**
* HashMap
*/
void preModify(HashMapEntry<K, V> e) { }
/**
* LinkedHashMap
*/
@Override
void preModify(HashMapEntry<K, V> e) {
if (accessOrder) {
makeTail((LinkedEntry<K, V>) e);
}
}这个方法是出现在put方法中的,LinedkHashMap并没有自己实现put方法,而是依然使用的父类HashMap的put方法,我们可以发现影响两者实现不同的关键在于accessOrder的值上面,如果是false那么两者的实现可以说是完全一样的,但是如果是true的话LinkedHashMap就会执makeTail函数。而我们知道使用无参构造创建LinkedHashMap的时候accessOrder默认值就是false,所以我们先暂时搁置不去看这个函数
/**
* HashMap
*/
void postRemove(HashMapEntry<K, V> e) { }
/**
* LinkedHashMap
*/
@Override
void postRemove(HashMapEntry<K, V> e) {
LinkedEntry<K, V> le = (LinkedEntry<K, V>) e;
le.prv.nxt = le.nxt;
le.nxt.prv = le.prv;
le.nxt = le.prv = null; // Help the GC (for performance)
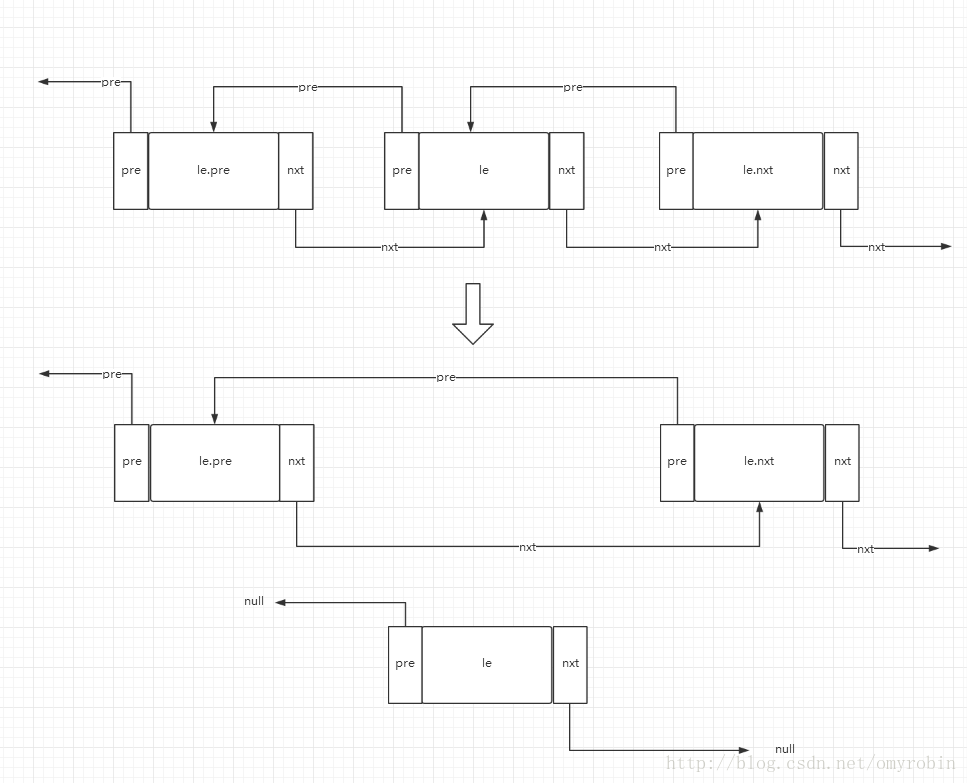
}这个方法是出现在remove方法中的,LinedkHashMap也没有自己实现remove方法,而是依然使用的父类HashMap的remove方法,这是只是操纵了LinedEntry特有的两个属性nxt和prv的指针引用,学过链表结构的想必都知道这个几行代码就是将元素e的前后元素的指针重新进行了赋值,同时将自身的引用断开置空。基本过程就如下图
/**
* HashMap
*/
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
/**
* LinkedHashMap
*/
@Override
void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header;
// Remove eldest entry if instructed to do so.
LinkedEntry<K, V> eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
// Create new entry, link it on to list, and put it into table
LinkedEntry<K, V> oldTail = header.prv;
LinkedEntry<K, V> newTail = new LinkedEntry<K,V>(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
}这个方法也是出现在put方法中,如果大家细心的话,可以发现LinedkHashMap的addNewEntry做了和HashMap的addNewEntry相同的事情。同时还做了一些HashMap没有做的事情
/**
* HashMap
*/
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
/**
* LinkedHashMap
*/
newTail = new LinkedEntry<K,V>(key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;总结:刨除header, oldTail就发现其实逻辑是一样的,那么header, oldTail额外干了什么呢,还得记得LinkedEntry的构造吗,去看看你就会想起来了,通过代码可以看出,它维护了一个以header为头节点的双向循环链表,通过上面的几个个比较,到这里想必大家现在应该有点知道了为什么LinkedEntry比HashMapEntry多出的两个属性nxt和pre到底用来干什么的。也就是说LinkedHashMap不但完全跟HashMap一样维护了一个散列链表,同时跟LinkedList一样也维护了一个双向循环链表,所以LinkedHashMap真的是名副其实啊也就是说LinkedHashMap不但像HashMap那样维护了一个Entry[]数组,同时也像LinkedList那样有一个以header为头结点的链表。
Entry[] 数组 table
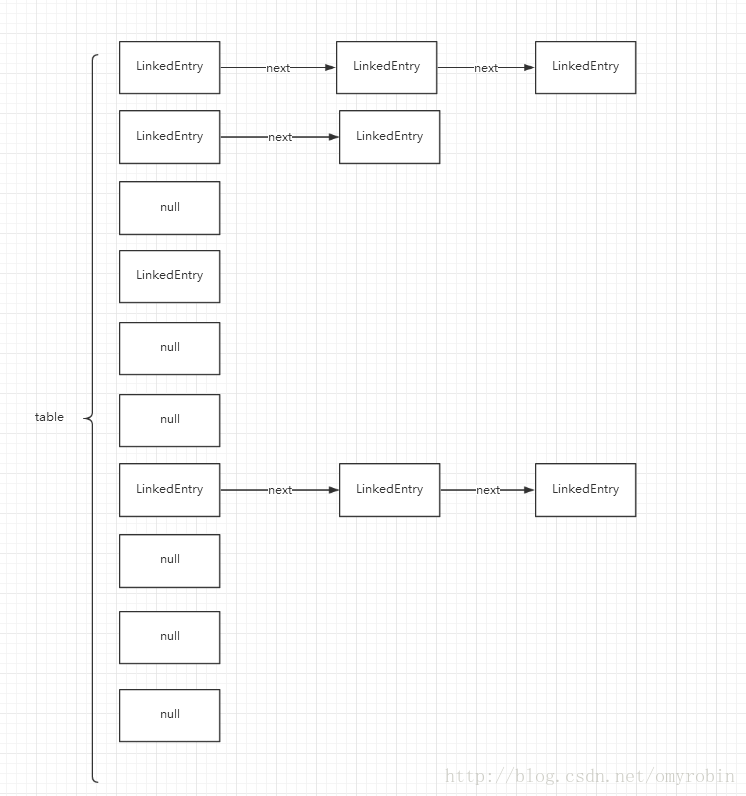
LinekedEntry header为头结点的链表
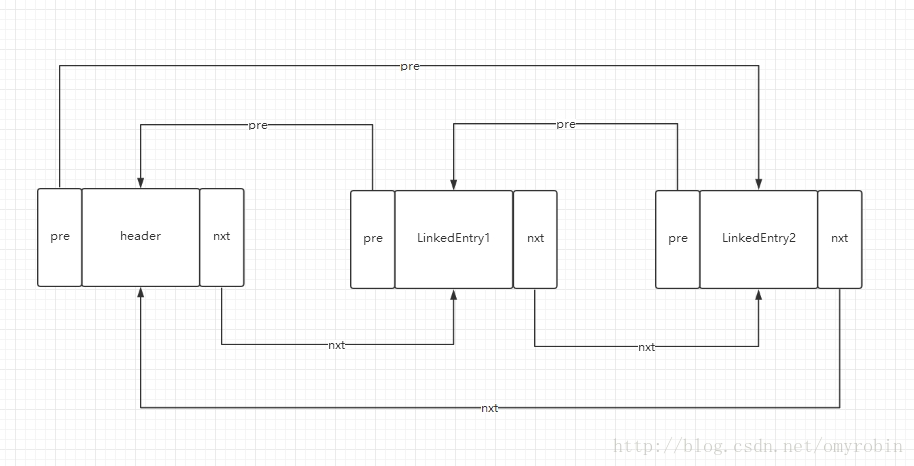
我们知道LinkedHashMap的增加和删除调用的是父类HashMap的方法,那么我们来看一下get方法有什么区别
- 查找
/**
* HashMap
*/
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
/**
* LinkedHashMap
*/
@Override
public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
}
return null;
}对比发现如果accessOrder如果是false是完全没有区别的,而且我们通过之前对比也多次见到了accessOrder这个变量的身影,可以说这个属性的值决定了很多事情,那么如accessOrder为true的话它都干了些什么呢?那么我们来看makeTail函数究竟做了些什么?
/**
* 是不是看起来不是那么复杂,而且十分眼熟,好像就是链表指针相关的各种操作,你链我啊 我链你的
*/
private void makeTail(LinkedEntry<K, V> e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry<K, V> header = this.header;
LinkedEntry<K, V> oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}实际上就是当我们get获取到元素的时候重新调整了该元素在链表中的位置。
相信还有一种数据结构大家不陌生吧就是队列,我们知道LinkedList也是实现Queue接口的
public class LinkedList<E> extends AbstractSequentialList<E> implements
List<E>, Deque<E>, Queue<E>, Cloneable, Serializable {所以LindedList其实就是队列的一种,而我们知道队列区别于栈结构的,队列是先进先出,队尾进入,队头出,而栈结构是先进后出的,栈顶进入,栈顶出。
看图我们就可以发现header头节点的nxt所指向的元素就是队头,而header头结点pre指向的元素就是队尾。
而当accessOrder为false的时候,是不执行makeTail函数的,LindedHashMap中的排序方式就是像队列一样先进先出,而且元素的顺序不会发生变化的(保持上图的LinedEntry1和LinedEntry2顺序),即使重新put了key值相同的元素,通过HashMap的源码可以发现他也只是执行了替换,没有执行addNewEntry,所以也就没有机会重新更改指针指向。而队列我们都知道队列满了的时候是从队头删除元素,腾出空间来使用的,所以这种形式下,最先进入队列或者链表中的就是最早的最老的元素,也就是header的nxt,
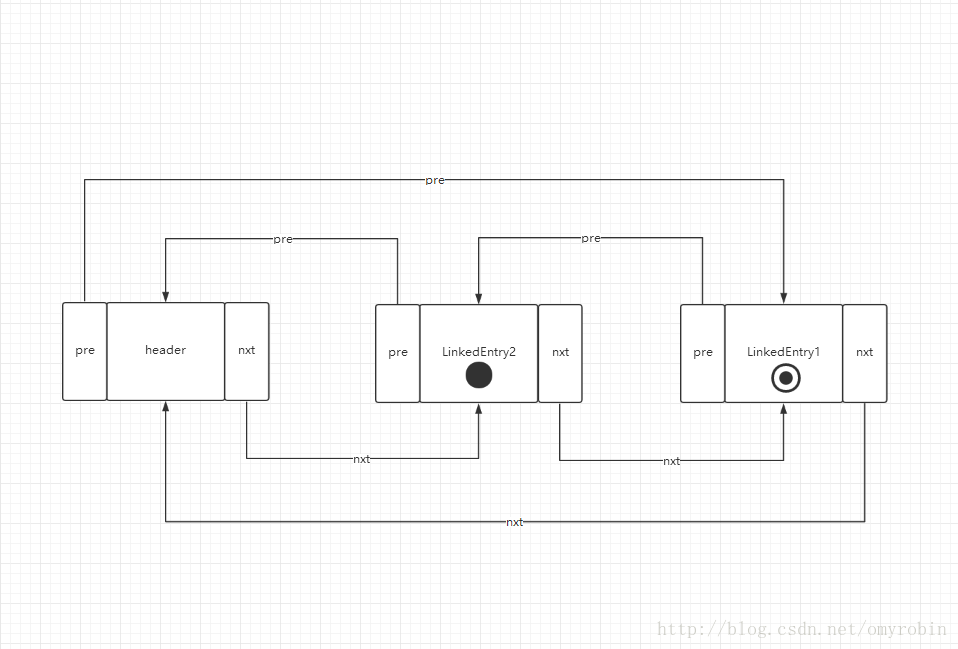
而当accessOrder为true的时候,是执行makeTail函数的,LindedHashMap中的排序方式就会随着访问和插入操作,元素的顺序就会发生变化的,重新更改指针指向(比如我们访问了LinkedEntry1,那么LinedEntry1就会放到LinkedEntry2的后面,如上图)。每次我们访问一个元素的时候都会改变元素的指针指向,将该元素放回队尾,重新调整header的pre指向,假如我们访问的正好是header.nxt指向的元素,那么header.nxt就会发生变化,那么上面提到的最老的元素就会发生了变化,而header.nxt永远指向的是最近最少使用的
想必看到这里大家对于Android缓存策略Lru到底是怎么实现的应该有了一定的了解了,那就是使用一个了accessOrder为true的LinkedHashMap。
下一篇我将简单带大家看一下LruCache的源码。