author: 张俊林
Batch Normalization的基本思路和价值在之前一篇文章“Batch Normalization导读”介绍了,此处不赘述,背景知识请参考上面文章。
看到BN后,很明显能够看到这等于往传统的神经网络中增加了一个BN层,而且位置处于神经元非线性变换前,基本大多数网络结构都能很自然地融合进去,于是很自然的想法就是:如果用在CNN或者RNN效果会如何?是否也会增加收敛速度以及模型分类性能?CNN的使用方式在原始的Batch Normalization论文就说了,RNN则有相关后续研究跟进,目前看还没有特别明确的结论。
|CNN的BatchNorm
CNN和DNN不一样,某个卷积层包含多个FilterMap,而每个Filter Map其实是参数共享的,侦测同一类特征,是通过在输入图像上的局部扫描的方式遍历覆盖整个输入图像的,但是单个Filter Map本身可能是二维甚至多维的,如果是二维的,那么包含p*q个神经元。那么此时要应用BN其实有两种选择:
一种是把一个FilterMap看成一个整体,可以想象成是一个Filter Map对应DNN隐层中的一个神经元,所以一个Filter Map的所有神经元共享一个Scale和Shift参数,Mini-Batch里m个实例的统计量均值和方差是在p*q个神经元里共享,就是说从m*p*q个激活里面算Filter Map全局的均值和方差,这体现了Filter Map的共享参数特性,当然在实际计算的时候每个神经元还是各算各的BN转换值,只不过采用的统计量和Scale,shift参数用的都是共享的同一套值而已。
另外一种是FilterMap的每个神经元都看成独立的,各自保存自己的Scale和Shift参数,这样一个Filter Map就有m*q*2个参数而不是大家共享这两个参数,同样地,均值和方差也是各算各的,意即每个神经元在m个实例的激活中计算统计量。
很明显,第一种方法能够体现卷积层FilterMap的思想本质,所以在CNN中用BN是采用第一种方式。在推理时,也是类似的改动,因为推理时均值和方差是在所有训练实例中算出的统计量,所以所有的神经元用的都一样,区别主要在于Scale参数和Shift参数同一个Filter Map的神经元一样共享同样的参数来计算而已,而DNN中是每个神经元各自算各自的,仅此而已。
图像处理等广泛使用CNN的工作中很多都使用了BN了,实践证明很好用。
|RNN的BatchNorm

图1 RNN的BN方向
对于RNN来说,希望引入BN的一个很自然的想法是在时间序列方向展开的方向,即水平方向(图1)在隐层神经元节点引入BN,因为很明显RNN在时间序列上展开是个很深的深层网络,既然BN在深层DNN和CNN都有效,很容易猜想这个方向很可能也有效。
另外一个角度看RNN,因为在垂直方向上可以叠加RNN形成很深的Stacked RNN,这也是一种深层结构,所以理论上在垂直方向也可以引入BN,也可能会有效。但是一般的直觉是垂直方向深度和水平方向比一般深度不会太深,所以容易觉得水平方向增加BN会比垂直方向效果好。
那么事实如何呢?这些猜想是否正确呢?
目前在RNN中引入BN的有几项工作,目前有些矛盾的结论,所以后面还需要更深入的实验来下确定的结论。我们归纳下目前能下的一些结论。
“Batch normalized recurrent neural networks”这个工作是最早尝试将BN引入RNN的,它构建了5层的RNN和LSTM,它的结论是:水平方向的BN对效果有损害作用,垂直方向BN能够加快参数收敛速度,但是相对基准无BN对照组实验看可能存在过拟合问题。但是这个过拟合是由于训练数据规模不够还是模型造成的并无结论。
“Deep speech 2: End-to-end speech recognition in english and mandarin.”这个工作也尝试将BN引入RNN,也得出了水平方向的BN不可行,垂直方向的BN对加快收敛速度和提升分类效果有帮助,这点和第一个工作结论一致。另外,新的结论是:在训练数据足够大的情况下,如果垂直方向网络深度不深的话,垂直方向的BN效果也会有损害作用,这个其实和工作一的结论基本一致,也说明了这个过拟合不是训练数据不够导致的,而是浅层模型加入BN效果不好。但是如果垂直方向深度足够深,那么加入BN无论是训练速度还是分类效果都获得了提高。
“Recurrent Batch Normalization”是最新的工作,16年4月份的论文。它的实验结果推翻了上面两个工作的结论。证明了水平方向BN是能够加快训练收敛速度以及同时提升模型泛化能力的。论文作者认为前面两个工作之所以BN在水平方向上不行,很可能主要是BN的Scale参数设置不太合理导致的,他们的结论是:Scale参数要足够小才能获得好的实验效果,如果太大会阻碍信息传播。
所以总结一下,目前能下的结论是:
RNN垂直方向引入BN的话:如果层数不够深(这个深度我感觉5层是个分界点,5层的时候效果不稳定,时好时坏,高于5层效果就是正面的了),那么BN效果不稳定或者是损害效果,深度如果够多的话,能够加快训练收敛速度和泛化性能。
2.在隐层节点做BN的话:
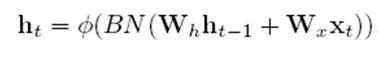
这么做肯定是不行的,就是说不能在垂直方向输入和水平方向输入激活加完后进行BN,这等于同时对水平和垂直方向做BN,垂直和水平方向必须分别做BN,就是说要这样:

3.在水平方向做BN时,类似于CNN参数共享的做法是很容易产生的,因为RNN也是在不同时间点水平展开后参数共享的,所以很容易产生的想法是BN的统计量也在不同时间序列间共享,实验证明这是不行的,必须每个时间点神经元各自维护自己的统计量和参数。
4.在水平方向做BN时,Scale参数要足够小,一般设置为0.1是OK的。
