1.HTTP协议
- HTTP协议(HyperText Transfer Protocol,超文本传输协议)使用于从www服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本,还确定传输文档中的哪一部分,以及那部分内容首先显示(如文本先于图形)等
- HTTP是基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
- HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。
- HTTP是一个无状态的协议。永远都是客户端发起请求,服务器回送响应。
2.HTTP协议的请求过程和响应过程
步骤1:浏览器首先向服务器发送HTTP请求,请求包括:
方法:GET还是POST,GET仅请求资源,POST会附带用户数据;
路径:/full/url/path;
域名:由Host头指定:Host: www.sina.com
以及其他相关的Header;
如果是POST,那么请求还包括一个Body,包含用户数据步骤2:服务器向浏览器返回HTTP响应,响应包括:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中。步骤3:如果浏览器还需要继续向服务器请求其他资源,比如图片,就再次发出HTTP请求,重复步骤1、2。
Web采用的HTTP协议采用了非常简单的请求-响应模式,从而大大简化了开发。当我们编写一个页面时,我们只需要在HTTP请求中把HTML发送出去,不需要考虑如何附带图片、视频等,浏览器如果需要请求图片和视频,它会发送另一个HTTP请求,因此,一个HTTP请求只处理一个资源(此时就可以理解为TCP协议中的短连接,每个链接只获取一个资源,如需要多个就需要建立多个链接)
3.HTTP格式


每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。
- HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
#每个Header一行一个,换行符是\r\n。- HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
#当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。- HTTP响应的格式:
200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
#HTTP响应如果包含body,也是通过\r\n\r\n来分隔的注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
4.web静态服务器
1.显示固定的页面
import socket
from multiprocessing import Process
def handleClient(clientSocket):
'用一个新的进程,为一个客户端进行服务'
recvData = clientSocket.recv(2014)
requestHeaderLines = recvData.splitlines()
# splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表
for line in requestHeaderLines:
print(line.decode('utf-8'))
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "Server:laowang\r\n"
responseHeaderLines += "\r\n"
responseBody = "hello world"
response = responseHeaderLines + responseBody
clientSocket.send(bytes(response, 'gbk'))
clientSocket.close()
def main():
'作为程序的主控制入口'
serverSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serverSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serverSocket.bind(("", 5673))
serverSocket.listen(10)
while True:
clientSocket, clientAddr = serverSocket.accept()
clientP = Process(target=handleClient, args=(clientSocket,))
clientP.start()
clientSocket.close()
if __name__ == '__main__':
main()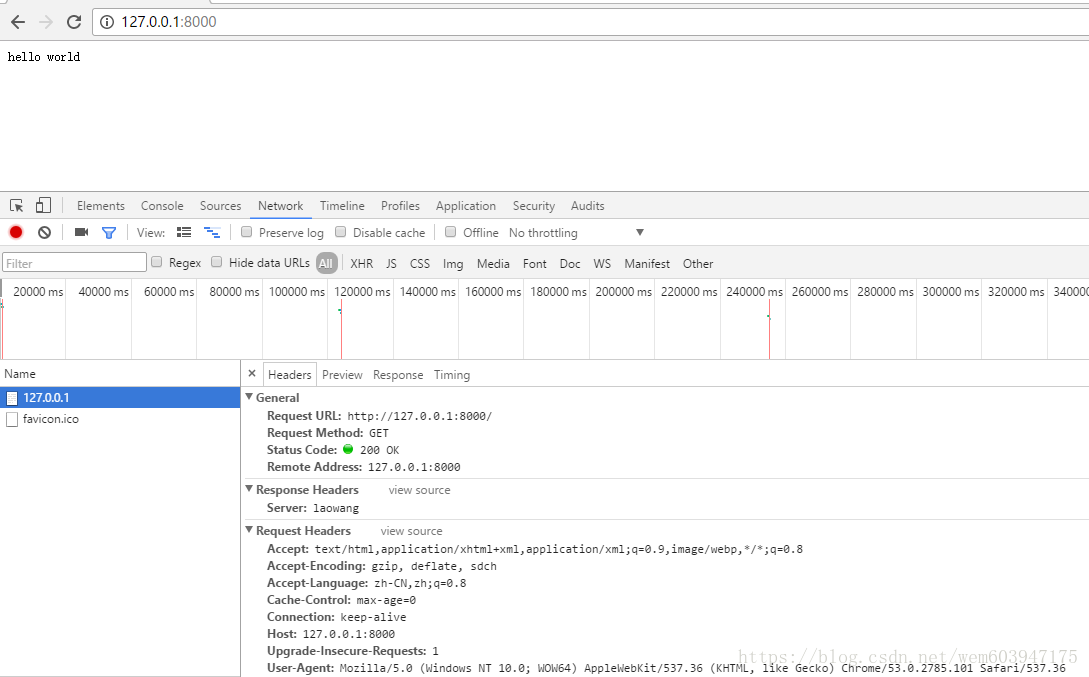
2.显示需要的页面
import socket
import re
from multiprocessing import Process
# 设置静态文件根目录
HTML_ROOT_DIR = "./html"
def handle_client(client_socket):
"""处理客户端请求"""
# 获取客户端请求数据
request_data = client_socket.recv(1024)
print("request data:", request_data)
request_lines = request_data.splitlines()
for line in request_lines:
print(line)
# 解析请求报文
# 'GET / HTTP/1.1'
request_start_line = request_lines[0].decode('utf-8')
# 提取用户请求的文件名
file_name = re.match(r"\w+ +(/[^ ]*) ", request_start_line).group(1)
if "/" == file_name:
file_name = "/index.html"
# 打开文件,读取内容
try:
file = None
file = open(HTML_ROOT_DIR + file_name, "rb")
file_data = file.read()
# 构造响应数据
response_start_line = "HTTP/1.1 200 OK\r\n"
response_headers = "Server: My server\r\n"
response_body = file_data.decode("utf-8")
except FileNotFoundError:
response_start_line = "HTTP/1.1 404 Not Found\r\n"
response_headers = "Server: My server\r\n"
response_body = "The file is not found!"
finally:
if file and (not file.closed):
file.close()
response = response_start_line + response_headers + "\r\n" + response_body
print("response data:", response)
# 向客户端返回响应数据
client_socket.send(bytes(response, "utf-8"))
# 关闭客户端连接
client_socket.close()
def main():
'作为程序的主控制入口'
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_socket.bind(("", 8000))
server_socket.listen(128)
while True:
client_socket, client_address = server_socket.accept()
# print("[%s, %s]用户连接上了" % (client_address[0],client_address[1]))
print("[%s, %s]用户连接上了" % client_address)
handle_client_process = Process(target=handle_client, args=(client_socket,))
handle_client_process.start()
client_socket.close()
if __name__ == "__main__":
main()3.使用类
import socket
import re
from multiprocessing import Process
# 设置静态文件根目录
HTML_ROOT_DIR = "./html"
class HTTPServer(object):
""""""
def __init__(self):
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
def start(self):
self.server_socket.listen(128)
while True:
client_socket, client_address = self.server_socket.accept()
# print("[%s, %s]用户连接上了" % (client_address[0],client_address[1]))
print("[%s, %s]用户连接上了" % client_address)
handle_client_process = Process(target=self.handle_client, args=(client_socket,))
handle_client_process.start()
def handle_client(self, client_socket):
"""处理客户端请求"""
# 获取客户端请求数据
request_data = client_socket.recv(1024)
print("request data:", request_data)
request_lines = request_data.splitlines()
for line in request_lines:
print(line)
# 解析请求报文
# 'GET / HTTP/1.1'
request_start_line = request_lines[0]
# 提取用户请求的文件名
print("*" * 10)
print(request_start_line.decode("utf-8"))
file_name = re.match(r"\w+ +(/[^ ]*) ", request_start_line.decode("utf-8")).group(1)
if "/" == file_name:
file_name = "/index.html"
# 打开文件,读取内容
try:
file = None
file = open(HTML_ROOT_DIR + file_name, "rb")
file_data = file.read()
# 构造响应数据
response_start_line = "HTTP/1.1 200 OK\r\n"
response_headers = "Server: My server\r\n"
response_body = file_data.decode("utf-8")
except FileNotFoundError:
response_start_line = "HTTP/1.1 404 Not Found\r\n"
response_headers = "Server: My server\r\n"
response_body = "The file is not found!"
finally:
if file and (not file.closed):
file.close()
response = response_start_line + response_headers + "\r\n" + response_body
print("response data:", response)
# 向客户端返回响应数据
client_socket.send(bytes(response, "utf-8"))
# 关闭客户端连接
client_socket.close()
def bind(self, port):
self.server_socket.bind(("", port))
def main():
http_server = HTTPServer()
# http_server.set_port
http_server.bind(8000)
http_server.start()
if __name__ == "__main__":
main()4.WSGI(Web Server Gateway Interface。)
WSGI不是服务器,不是API,不是Python模块,更不是什么框架,而是一种服务器和客户端交互的接口规范!
在WSGI规范下,web组件被分成三类:client, server, and middleware.
WSGI apps(服从该规范的应用)能够被连接起来处理一个request,这也就引发了中间件这个概念,中间件同时实现c端和s端的接口,c看它是上游s,s看它是下游的c。
WSGI的s端所做的工作仅仅是接收请求,传给application(做处理),然后将结果response给middleware或client.除此以外的工作都交给中间件或者application来做。