上一篇文章中我们对java中的 I/O 流进行了一个详细的讲解,但是只是带大家讲了几个常用的流,今天再对其他几个流作个补充介绍。
PrintWriter 、PrintStream
InputStreamWriter 、OutputStreamWriter
PipedInputStream 、 PipedOutputStream
SequenceInputStream
DataInputStream 、DataOutputStream
ObjectInputStream 、ObjectOutputStream
一、PrintWriter 和 PrintStream(打印流)
PrintStream
是一个字节打印流,System.out对应的类型就是PrintStream。
它的构造函数函数有5个:
PrintStream(File file)
创建具有指定文件的新打印流。
PrintStream(File file, String csn)
创建具有指定文件名称和字符集的新打印流。
PrintStream(OutputStream out)
创建新的打印流。
PrintStream(OutputStream out, boolean autoFlush)
创建新的打印流。 autoFlush为是否自动刷新。
PrintStream(OutputStream out, boolean autoFlush, String encoding)
创建新的打印流。
PrintStream(String fileName)
创建具有指定文件名称的新打印流。
PrintStream(String fileName, String csn)
创建具有指定文件名称和字符集的新打印流。
需要注意的就是autoFlush这个boolean值,autoFlush这个boolean值只在有包装流的时候才起作用,用一般的流的时候不起作用,都会刷新。如何理解呢?
例子:PrintStream(FileOutputStream(“a.txt”),true/false) 这个时候不管autoFlush为 true 或者 false,它都会刷新。
PrintStream(new BufferedOutputStream(FileOutputStream(“a.txt”)),true/false) ,如果为 true就会自动刷新,如果为 false 就要手动刷新,调用 flush 方法或者 close() 方法,我们知道在调用 close() 方法之前会调用 flush() 方法。
PrintWriter
是一个字符打印流。构造函数可以接收四种类型的值。
1,字符串路径。
2,File对象。
对于1,2类型的数据,还可以指定编码表。也就是字符集。
3,OutputStream
4,Writer
对于3,4类型的数据,可以指定自动刷新。
注意:该自动刷新值为true时,只有三个方法可以用:println,printf,format.默认为 false ,需要手动刷新,对一般流和包装流都起作用。
二、InputStreamWriter 和 OutputStreamReader(转换流)
InputStreamReader
InputStreamReader 将字节流转换为字符流。是字节流通向字符流的桥梁。如果不指定字符集编码,该解码过程将使用平台默认的字符编码,如:GBK。
构造方法:
InputStreamReader(InputStream in)
创建一个使用默认字符集的 InputStreamReader。
InputStreamReader(InputStream in, Charset cs)
创建使用给定字符集的 InputStreamReader。
InputStreamReader(InputStream in, CharsetDecoder dec)
创建使用给定字符集解码器的 InputStreamReader。
InputStreamReader(InputStream in, String charsetName)
创建使用指定字符集的 InputStreamReader。
主要方法:
int read();//读取单个字符。
int read(char []cbuf);//将读取到的字符存到数组中。返回读取的字符数。
每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节。
为了达到最高效率,可以考虑在 BufferedReader 内包装 InputStreamReader。例如:
BufferedReader in
= new BufferedReader(new InputStreamReader(System.in));
OutputStreamWriter
OutputStreamWriter 将字节流转换为字符流。是字节流通向字符流的桥梁。如果不指定字符集编码,该解码过程将使用平台默认的字符编码,如:GBK。
构造方法:
OutputStreamWriter(OutputStream out)
创建使用默认字符编码的 OutputStreamWriter。
OutputStreamWriter(OutputStream out, Charset cs)
创建使用给定字符集的 OutputStreamWriter。
OutputStreamWriter(OutputStream out, CharsetEncoder enc)
创建使用给定字符集编码器的 OutputStreamWriter。
OutputStreamWriter(OutputStream out, String charsetName)
创建使用指定字符集的 OutputStreamWriter。
主要方法:
void write(int c);//将单个字符写入。
viod write(String str,int off,int len);//将字符串某部分写入。
void flush();//将该流中的缓冲数据刷到目的地中去。
每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。
在写入底层输出流之前,得到的这些字节将在缓冲区中累积。
可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。
注意,传递给 write() 方法的字符没有缓冲。
为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。例如:
Writer out
= new BufferedWriter(new OutputStreamWriter(System.out));
在转换流中是可以指定编码表的。
默认情况下,都是本机默认的码表GBK. 这个编码表怎么来的?
System.out.println(System.getProperty(“file.encoding”));
常见码表:
ascii:美国标准信息交换码。使用的是1个字节的7位来表示该表中的字符。
ISO8859-1:拉丁码表。使用1个字节来表示。
GB2312:简体中文码表。
GBK:简体中文码表,比GB2312融入更多的中文文件和符号。
unicode:国际标准码表。都用两个字节表示一个字符。
UTF-8:对unicode进行优化,每一个字节都加入了标识头。
编码转换:
字符串 –>字节数组 :编码。通过getBytes(charset);
字节数组–>字符串: 解码。通过String类的构造函数完成。String(byte[],charset);
三、PipedInputStream 和 PipedOutputStream(管道流)
管道流,用于在应用程序中创建管道通信。一个线程的PipedInputStream对象从另外一个线程的PipedOutputStream对象读取输入。要使管道流有用,必须同时构造管道输入流和管道输出流。
连接:
1,通过两个流对象的构造函数。
2,通过两个对象的connect方法。
例子:
public class Producer extends Thread{
private PipedOutputStream pos;
public Producer(PipedOutputStream pos) {
this.pos = pos;
}
@Override
public void run() {
try {
pos.write("世界你好".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
}public class Consumer extends Thread{
private PipedInputStream pis;
public Consumer(PipedInputStream pis) {
this.pis = pis;
}
@Override
public void run() {
byte[] b = new byte[100]; //将读取的数据保存在这个字节数组中
try {
int len = pis.read(b);//返回数组的实际长度
System.out.println(new String(b, 0, len));
} catch (IOException e) {
e.printStackTrace();
}
}
}public class PipedStreamTest {
public static void main(String[] args) throws IOException {
PipedInputStream pis = new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream();
pis.connect(pos);//连接管道
new Producer(pos).start();
new Consumer(pis).start();
}
}结果:
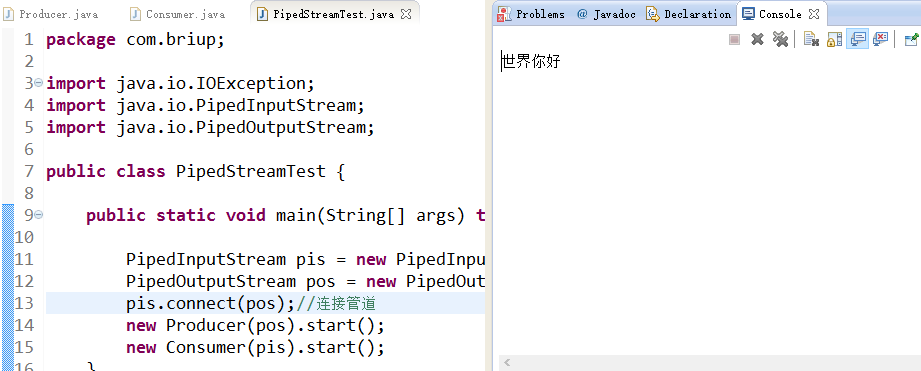
可以看到两线程之间进行了通信。
通常两个流在使用时,需要加入多线程技术,也就是让读写同时运行。
注意:对于read方法。该方法是阻塞式的,也就是没有数据的情况,该方法会等待。
四、SequenceInputStream(合并流)
有没有发现这个流只有一个,其他的流都是成对的。有些情况下,当我们需要从多个输入流中向程序读入数据。此时,可以使用合并流,将多个输入流合并成一个SequenceInputStream流对象。
其可接收枚举类所封闭的多个字节流对象。
特点:可以将多个读取流合并成一个流。这样操作起来很方便。
原理:其实就是将每一个读取流对象存储到一个集合中。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
构造方法:
SequenceInputStream(Enumeration
public class SequenceInputStreamTest {
public static void main(String[] args) {
doSequence();
}
private static void doSequence() {
//创建一个合并的流对象
SequenceInputStream sis = null;
//创建输出流
BufferedOutputStream bos = null;
try {
//构建流集合
Vector<InputStream> vector = new Vector<>();
vector.addElement(new FileInputStream("a.txt"));
vector.addElement(new FileInputStream("a1.txt"));
vector.addElement(new FileInputStream("a2.txt"));
Enumeration<InputStream> e = vector.elements();
sis = new SequenceInputStream(e);
bos = new BufferedOutputStream(new FileOutputStream("aa.txt"));
//读写数据
byte[] b = new byte[1024];
int len;
while ((len = sis.read(b)) != -1) {
bos.write(b, 0, len);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
} finally {
if (sis != null) {
try {
sis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}a.txt、a1.txt、a2.txt的内容
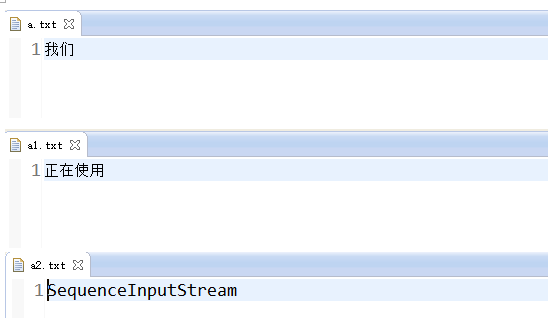
结果:

五、DataInputStream 和 DataOutputStream(数据操作流)
DataInputStream和DataOutputStream二者分别实现了DataInput/DataOutput接口
DataInputStream能以一种与机器无关(当前操作系统等)的方式,直接从地从字节输入流读取JAVA基本类型和String类型的数据,常用于网络传输等(网络传输数据要求与平台无关)
DataOutputStream则能够直接将JAVA基本类型和String类型数据写入到其他的字节输入流。
例子:
public class DataStreamTest {
public static void main(String[] args) {
FileOutputStream fos;
try {
fos = new FileOutputStream("b.data");
DataOutputStream dos=new DataOutputStream(fos);
dos.writeInt(100);
dos.writeUTF("DataOutputStream Test");
dos.close();
FileInputStream fis=new FileInputStream("b.data");
DataInputStream dis=new DataInputStream(fis);
System.out.println("int:"+dis.readInt());
System.out.println("UTF:"+dis.readUTF());
dis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}结果:
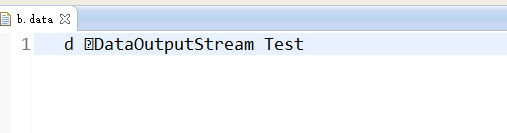
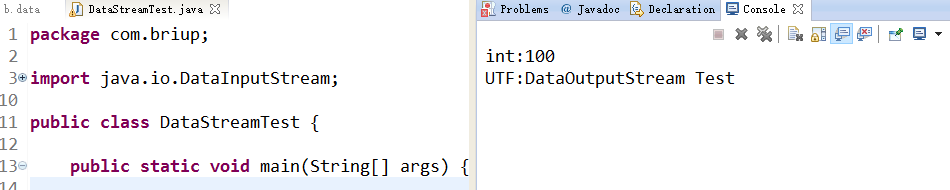
产生一个b.data文件(此时已经不是文本文件,此时编码为JAVA虚拟机通用格式,即UTF-8)
注:当要求输入输出流必须遵循平台无关时,可以使用这两个类
六、ObjectInputStream 和 ObjectOutputStream(序列化和反序列化流)
以前在文件中写入数据的主要方式是用字符流或者字节流。但是如果想保存并读取一个对象,该怎么办?可以是用ObjectOutputStream类 和 ObjectInputStream类。
1、ObjectOutputStream是将一个对象的所有相关属性、信息(不包括方法)写入到底层流中、而DataOutputStream一次写入的只是一个java基础类型的数据。
常用构造方法:ObjectOutputStream oos = new ObjectOutputStream(OutputStream out);//创建一个写入指定OutputStream的ObjectOutputStream对象.
如:ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("F:\\obj.object"));
主要方法:void writeObject(Object obj);//将指定的对象写入ObjectOutputStream.对对象进行序列化。
它虽然不是实现了FilterOutputStream装饰类,同时实现了ObjectOut,而此接口实现了DataOut接口,并且对这个接口进行了扩展,使得ObjectOut在具有DataOut中定义的各种方法,同时也具有将对象、数组、字符串写入到底层字节流中的功能,这样也就意味着ObjectOutputStream同样具有DataOutputStream功能的同时也具有将对象、数组字符串写入到底层字节输出流中的功能。
当然ObjectOuputStream同样还实现了别的接口、因为他写入一个对象的时候、不仅仅写入的是标示这个Object的所有属性、同时还有额外的一些信息、比如版本号、作者等、但是这些对我们是透明的、具体的写入方法由JDK说了算。
注意:被写入的对象必须实现Serializable接口或Externalizable接口。
2、读取的时候ObjectOutputStream一次读取一个对象、不必关心对象每个属性的写入顺序、而DataOutputStream读取时要严格按照写入时的顺序读取(当然、在使用skip方法时还要考虑字节数)
常用构造方法:
ObjectInputStream ois = new ObjectInputStream(InputStream in);//创建从指定 InputStream 读取的 ObjectInputStream。
如:ObjectInputStream ois = new ObjectInputStream(new FileInputStream("F:\\obj.object"));
主要方法:Object readObject();//从ObjectInputStream读取对象。由于其返回的是Object类型 需要对其进行强转。
与ObjectOutputStream相对应,实现了ObjectInput接口,而ObjectInput接口实现了DataInput接口,在DataInput接口定义的基础上扩展了读取对象、数组、字符串的功能。
作为ObjectInput的实现类ObjectInputStream,它可以将使用ObjectOutputStream写入到底层输出流中的对象、数组、字符串读取到程序中、并还原成当初写入时的状态、这样我们就可以直接对这个对象进行操作。从而达到操作java对象、数组、字符串的目的。
序列化可以将一个java对象以二进制流的方式在网络中传输并且可以被持久化到数据库、文件系统中;
反序列化则是可以把之前持久化在数据库或文件系统中的二进制数据以流的方式读取出来重新构造成一个和之前相同内容的java对象。
序列化的实现:
1)、需要序列化的类需要实现Serializable接口,该接口没有任何方法,只是标示该类对象可被序列化。
2)、序列化过程:使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态)
3)、反序列化过程:使用一个输入流(如:FileInputStream)来构造一个ObjectInputStream(对象流)对象,接着,使用ObjectInputStream对象的readObject(Object obj)方法就可以将参数为obj的对象读出(即获取其状态)
例子:
Student.java
/**
* 继承Serializable接口用于给该标示一个ID号。该id号由虚拟机根据该类运算得出。
*
* 用于判断该类和obj对象文件是否 为同一个版本。当不为同一个版本时将会抛出无效类异常。
* @author Administrator
*
*/
public class Student implements Serializable{
/**
* 由于在定义对象时需要定义一个静态final的long字段serialVersionUID。
* 如果不定义的话系统将根据该类各个方面进行计算该值,极容易导致读取异常。
*/
private static final long serialVersionUID = -6205013588337175827L;
// static 和 transient修饰符修饰的都不会被写入到对象文件中去。
//非瞬态和非静态字段的值都将被写入
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}ObjectStreamDemo.java
public class ObjectStreamDemo {
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
write();
read();
}
/**
* 读取对象
* @throws IOException
* @throws FileNotFoundException
* @throws ClassNotFoundException
*/
private static void read() throws FileNotFoundException, IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("obj.object"));
Object object = ois.readObject();
System.out.println(object.toString());
object = ois.readObject();
System.out.println(object.toString());
object = ois.readObject();
System.out.println(object.toString());
}
/**
* 将对象写入
* @throws IOException
* @throws FileNotFoundException
*/
private static void write() throws FileNotFoundException, IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("obj.object"));
//对象序列化
oos.writeObject(new Student("周杰论", 10));
oos.writeObject(new Student("wuli韬韬", 30));
oos.writeObject(new Student("TF-BOYS", 15));
oos.close();
}
}结果:
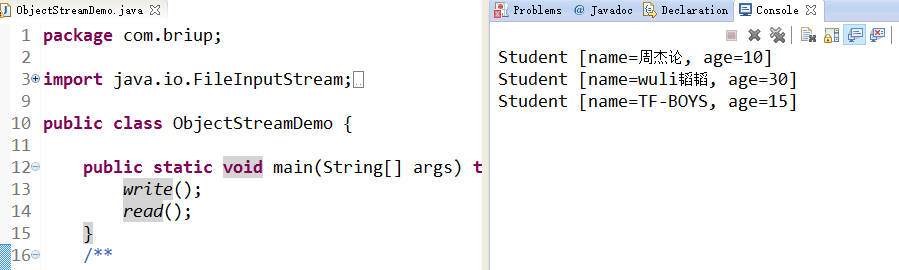

serialVersionUID作用:
如果没有设置这个值,你在序列化一个对象之后,改动了该类的字段或者方法名之类的,那如果你再反序列化想取出之前的那个对象时就可能会抛出异常,
因为你改动了类中间的信息,serialVersionUID是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段。
当修改后的类去反序列化的时候发现该类的serialVersionUID值和之前保存的serialVersionUID值不一致,所以就会抛出异常。
而显示的设置serialVersionUID值就可以保证版本的兼容性,如果你在类中写上了这个值,就算类变动了,它反序列化的时候也能和文件中的原值匹配上。
而新增的值则会设置成null,删除的值则不会显示。
总结:
1)、如果一个类可被序列化,其子类也可以,如果该类有父类,则根据父类是否实现Serializable接口,实现了则父类对象字段可以序列化,没实现,则父类对象字段不能被序列化。
2)、声明为transient类型的成员数据不能被序列化。transient代表对象的临时数据;
3)、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;