文章目录
本篇博客的内容分为两部分:1、在windows10下编译GPU版本的tensorflow,并获得tensorflow.lib和tensorflow.dll文件;2、利用这两个文件,创建一个C++工程,编写inference示例程序
一、windows10下编译GPU版本的tensorflow
1、首先需要准备的环境
- x墙工具
- vs2015
- swig,官网是这里,注意下载windows版本的(含有.exe文件),解压即可
- python,建议3.6或以上版本
- CMake,官网下载安装,安装完成后添加到环境变量里(../CMake/bin)
- Git,官网下载安装,安装完成后添加到环境变量里(../Git/bin)
- cuda及cudnn,本文编译的是最新的1.6版本tf,所以cuda要求9.0,cudnn要求7,限于篇幅,配置方法自行网上搜索
- 矩阵运算库,例如BLAS、MKL、eigen这些,这里我选择的是eigen,下载最新的版本,解压后添加到环境变量里(../eigen3.3.4)
2、下载tensorflow源码,配置CMakeLists.txt
打开命令提示符,cd到专门的路径下,输入
git clone --recursive https://github.com/tensorflow/tensorflow.git下载好tensorflow源码后,找到tensorflow/contrib/cmake/CMakeLists.txt,搜索“tensorflow_OPTIMIZE_FOR_NATIVE_ARCH”,找到后做出如下修改
if (tensorflow_OPTIMIZE_FOR_NATIVE_ARCH)
include(CheckCXXCompilerFlag)
CHECK_CXX_COMPILER_FLAG("-march=native" COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
if (COMPILER_OPT_ARCH_NATIVE_SUPPORTED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=native")
else()
CHECK_CXX_COMPILER_FLAG("/arch:AVX" COMPILER_OPT_ARCH_AVX_SUPPORTED)
if(COMPILER_OPT_ARCH_AVX_SUPPORTED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /arch:AVX")
endif()
endif()
endif()3、开始编译lib和dll
首先进入tensorflow/contrib/cmake目录下,新建一个build文件夹。然后打开命令提示符,输入cmake-gui,配置相关的路径,再configure(选择vs2015的那个vc14 64位编译器),即可得到下图
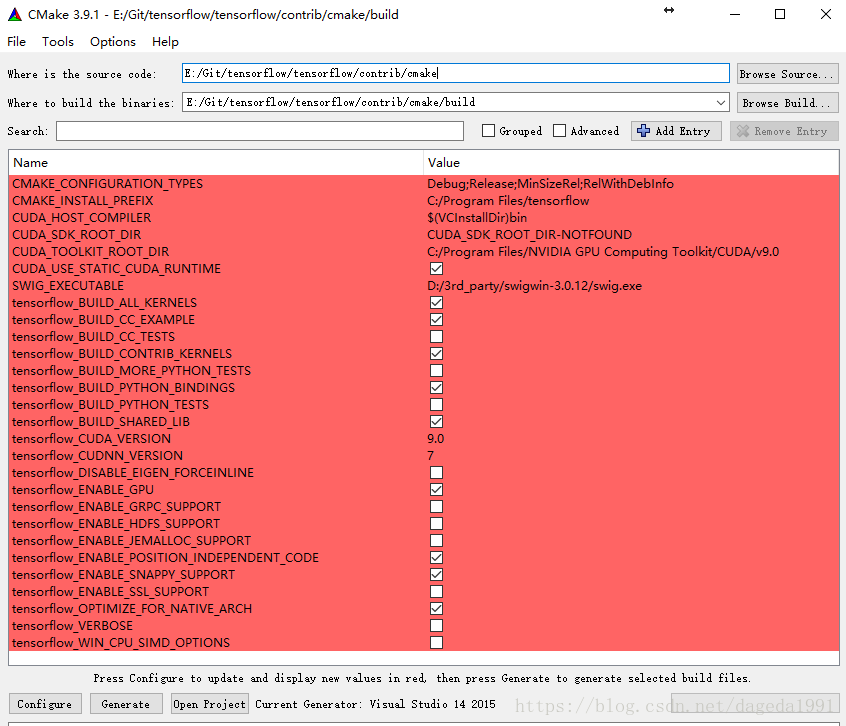
原本根据需要自行勾选编译选项,再configure+generate,即可打开vs2015完成编译,我最开始就是这么做的,但始终没有成功,报的错误也看不懂(后来我在知乎上看到有一篇文章,作者说tensorflow各工程之间依赖十分复杂,直接用ALL_BUILD要改一些配置)。所以这里我采用的是vs2015自带的编译工具,如下图
右键-更多-以管理员身份运行,先cd到tensorflow/contrib/cmake/build目录下,再输入以下内容进行configure
cmake .. -A x64 -DCMAKE_BUILD_TYPE=Release -DSWIG_EXECUTABLE=D:/3rd_party/swigwin-3.0.12/swig.exe -DPYTHON_EXECUTABLE=D:/python.exe -DPYTHON_LIBRARIES=D:/libs/python36.lib -Dtensorflow_ENABLE_GPU=ON -Dtensorflow_ENABLE_GRPC_SUPPORT=OFF -Dtensorflow_BUILD_SHARED_LIB=ON说明一下需要自行修改的参数,SWIG_EXECUTABLE是swig.exe所在路径,PYTHON_EXECUTABLE和PYTHON_LIBRARIES分别是python的exe和lib所在路径,这些都需要自己配,而且路径不能含有空格或者中文字符。后面tensorflow_ENABLE_GRPC_SUPPORT涉及到tensorflow线上部署,默认是ON的状态,如果要编译,则需要下载一堆文件,这里我不需要,就关闭了。另外要想指定编译其它内容,可以参考前面cmake-gui的那张图,配置的格式就是”-D+xxx=ON/OFF”。修改完这段话后,即可执行,等待configure done。
configure完成之后,就要开始正式编译动态库了。此时需要打开你的x墙工具,因为编译的过程中,会从网上下载几个文件,虽然都不大,但它们是存储在含有google的网址内的。接下来,在刚才的命令行窗口继续输入
MSBuild /p:Configuration=Release ALL_BUILD.vcxproj注意如果想编debug版本的动态库,就把Release改成Debug。接下来就是漫长的等待了,在我的i7电脑下,编了大概三小时才完成,期间电脑会特别卡(vs默认是多线程编译的)。注意最后不能有错误,否则无法顺利生成tensorflow.lib和tensorflow.dll。最终得到的lib和dll是在tensorflow/contrib/cmake/build/Release目录下,这里提供我编译的一个release版本,还包含整理好的头文件。
二、基于tensorflow C++ api的inference示例程序
前面编译的方法其实很多网址都能搜到,这里写出来是为了做个记录。接下来写的才是本文的重点:如何利用已训练好的tensorflow模型,在windows下编写inference程序,打包生成exe文件,供线下部署。
1、在vs2015中新建项目,配置环境
头文件的配置如下
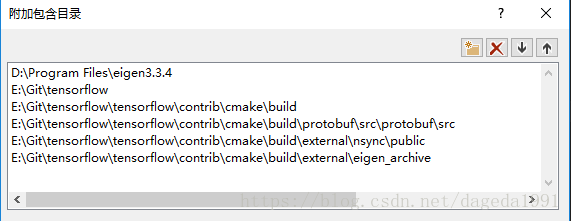
说明:第一个eigen是前面所说的矩阵运算库,因为c++没有类似numpy的东西(不过c++14有个xtensor),所以矩阵运算可以利用eigen的api。E:\Git\tensorflow是我的tensorflow源码根目录,此外还需要包含一些build里面的头文件,因为部分.h和.cc文件是编译的时候生成的。
lib文件配置即配置tensorflow.lib所在目录,此外注意配置tensorflow.dll
2、新建main.cpp。
本程序的主要功能是输入一张图片,读取tensorflow模型,给出运算结果。下面一步步介绍其实现
2.1 宏定义和头文件
先上代码
#define COMPILER_MSVC
#define NOMINMAX
#define PLATFORM_WINDOWS // 指定使用tensorflow/core/platform/windows/cpu_info.h
#include<iostream>
#include<opencv2/opencv.hpp>
#include"tensorflow/core/public/session.h"
#include "tensorflow/core/platform/env.h"
using namespace tensorflow;
using std::cout;
using std::endl;这里需要将宏定义放在最前面,因为涉及到平台、编译器这些,否则就会报一些未定义的错误。另外这里使用了tensorflow的命名空间,是为了使后面的代码更简洁一些。
2.2 读取图片
有两种方式:一是用tensorflow自带的api,参考这里的讨论;二是利用opencv读取,再转化为tensorflow可识别的数据格式,这种方法的好处就是,可以很方便地利用opencv库做一些预处理。下面介绍第二种方法
// 设置输入图像
cv::Mat img = cv::imread(image_path);
cv::cvtColor(img, img, cv::COLOR_BGR2GRAY);
int height = img.rows;
int width = img.cols;
int depth = img.channels();
// 图像预处理
img = (img - 128) / 128.0;
img.convertTo(img, CV_32F);
// 取图像数据,赋给tensorflow支持的Tensor变量中
const float* source_data = (float*)img.data;
tensorflow::Tensor input_tensor(DT_FLOAT, TensorShape({1, height, width, depth })); //这里只输入一张图片,参考tensorflow的数据格式NHWC
auto input_tensor_mapped = input_tensor.tensor<float, 4>(); // input_tensor_mapped相当于input_tensor的数据接口,“4”表示数据是4维的。后面取出最终结果时也能看到这种用法
// 把数据复制到input_tensor_mapped中,实际上就是遍历opencv的Mat数据
for (int i = 0; i < height; i++) {
const float* source_row = source_data + (i * width * depth);
for (int j = 0; j < width; j++) {
const float* source_pixel = source_row + (j * depth);
for (int c = 0; c < depth; c++) {
const float* source_value = source_pixel + c;
input_tensor_mapped(0, i, j, c) = *source_value;
}
}
}需要说明的都放在了代码注释当中,这里用到了auto,包括后面的代码也用到了不少,主要原因是我也还未弄清部分数据的格式(后来看到了tf官方的示例,他们也建议用auto,这样代码更简洁一些)。
2.3 建立会话,加载模型文件
模型来自我前段时间训练的验证码识别,注意要保存为.pb格式,这样inference的时候就不用重新搭建网络结构了。
// 初始化tensorflow session
Session* session;
Status status = NewSession(SessionOptions(), &session);
if (!status.ok()){
std::cerr << status.ToString() << endl;
return -1;
}
else {
cout << "Session created successfully" << endl;
}
// 读取二进制的模型文件到graph中
GraphDef graph_def;
status = ReadBinaryProto(Env::Default(), model_path, &graph_def);
if (!status.ok()) {
std::cerr << status.ToString() << endl;
return -1;
}
else {
cout << "Load graph protobuf successfully" << endl;
}
// 将graph加载到session
status = session->Create(graph_def);
if (!status.ok()) {
std::cerr << status.ToString() << endl;
return -1;
}
else {
cout << "Add graph to session successfully" << endl;
}2.4 定义输入输出数据格式,run inference,输出数据可视化
// 输入inputs,“ x_input”是我在模型中定义的输入数据名称,此外模型用到了dropout,所以这里有个“keep_prob”
tensorflow::Tensor keep_prob(DT_FLOAT, TensorShape());
keep_prob.scalar<float>()() = 1.0;
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs = {
{ "x_input", input_tensor },
{ "keep_prob", keep_prob },
};
// 输出outputs
std::vector<tensorflow::Tensor> outputs;
// 运行会话,计算输出"x_predict",即我在模型中定义的输出数据名称,最终结果保存在outputs中
status = session->Run(inputs, { "x_predict" }, {}, &outputs);
if (!status.ok()) {
std::cerr << status.ToString() << endl;
return -1;
}
else {
cout << "Run session successfully" << endl;
}
// 下面进行输出结果的可视化
tensorflow::Tensor output = std::move(outputs.at(0)); // 模型只输出一个结果,这里首先把结果移出来(也为了更好的展示)
auto out_shape = output.shape(); // 这里的输出结果为1x4x16
auto out_val = output.tensor<float, 3>(); // 与开头的用法对应,3代表结果的维度
// cout << out_val.argmax(2) << " "; // 预测结果,与python一致,但具体数值有差异,猜测是计算精度不同造成的
// 输出这个1x4x16的矩阵(实际就是4x16)
for (int i = 0; i < out_shape.dim_size(1); i++) {
for (int j = 0; j < out_shape.dim_size(2); j++) {
cout << out_val(0, i, j) << " ";
}
cout << endl;
}输出结果如下图(懒得打码了,请无视我的显卡。。)
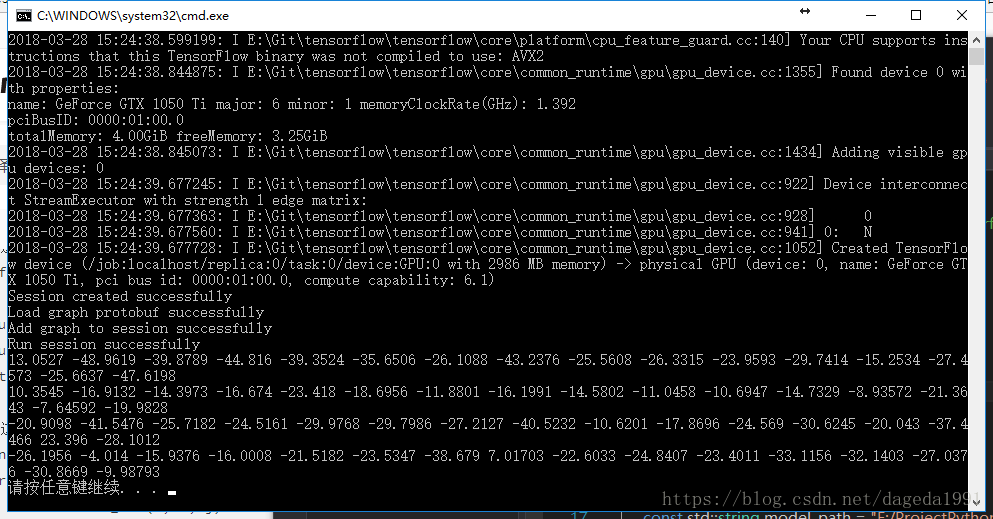
至此,模型输出数据的格式也清楚了,完整流程就是这样,想进一步研究Tensor用法的话可以参考这里,完整的代码参考我的GitHub。
PS
本次完成所有工程,在网上参考了大量资料,时间关系,这里不分先后,列举一下:tensorflow编译、TensorFlow C++ API案例一、TensorFlow C++ API案例二、TensorFlow C++ API案例三(gist貌似也要x墙?)
距离上一次更新博客已经半年了,主要原因还是自己比较懒,这次总算是做了一点综合性的工作,希望以后能继续。另外吐槽一点,百度的搜索太差劲了,我先前的博客,即使输入原标题也在百度里面搜不到,但是在谷歌里面第一条就是。
PPS
更新一个tensorflow官方的c++ api inference例子