1. kafka的使用场景
上游模块或系统产生数据,下游模块或系统使用数据、分析数据、计算数据,这样的就可以使用消息系统。
我个人认为就是,可以异步处理,一个管生产、一个管消费,关系基本稳定不会倒置,就可以使用消息系统。
还有一种场景就是,把数据放到消息中间件里存放,不存放在数据库里。这些数据顺序存在消息中间件,反而比存在数据库随机读写效率要快。
kafka现在可以和Apache flume(日志收集系统)、Apache Storm(实时数据处理)、Spark(内存数据处理)、elasticSearch(全文检索系统)可以做到无缝对接。
2. 主流消息中间件对比
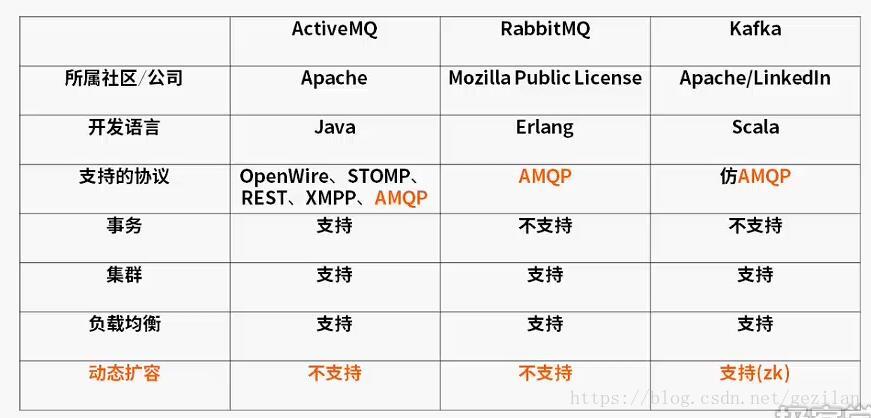
- 可以看到ActiveMQ 和 Kafka都是使用基于JVM的语言编写
- RabbitMQ使用Erlang和go语言差不多,本身就支持高并发。但严格遵守AMQP协议,所以受到约束,性能反而不如Kafka整体性能高
- Kafka主要目标是高性能,自己设计并使用了一种协议,并不主流。仿AMQP
- 事务,只有ActiveMQ支持。RabbitMQ和Kafka为追求更高的性能,牺牲了事务的特性
- 负载均衡:要把请求分发到集群,避免某台机器上压力过大,甚至宕机
- 动态扩容:如果不支持动态扩容,就需要服务停机,很多公司不可接受。Kafka可以支持在线不停机扩容
- Kafka的动态扩容是通过zookeeper来实现的。
- zookeeper是广泛应用在分布式系统中,用来管理分布式状态管理、分布式心跳管理、分布式配置管理、分布式锁服务的集群
- Kafka动态扩容时,在zookeeper的节点上触发相应的事件,Kafka会捕获这些事件,进行新一轮的负载均衡,客户端捕获这些事件进行相应的自定义处理,