并发问题
一个状态修改引起的问题
就是我们本地做了同步和异步两种操作,每个操作都会牵扯到对某个状态的修改,判断,展示。除此之外,在别的快递员也可以在别的机器上对某个订单的同个状态进行修改,这么多的不确定因素导致的结果很多,可能会有意想不到的问题,即便测试也很难把所有的情况都测出来,会导致线上很多问题。
那这个问题该怎么解决?
本地和服务器因为同一个状态撕咬后的解决方案
并发问题一直都是程序员头疼的问题,一般来说市面上大多数的安卓端app是不存在并发情况的,在我目前负责的项目中有线程池不停的轮询数据库操作,这样就会导致并发。
- 每个单号的提交进行状态的修改
- 提交的时候对状态修改
- 单号与任务号的绑定设置在提交的时候
问题现状:
1、同一库区多个未提交的任务;
2、多个未提交的任务是同一个理货员在同一个PDA建立的;
3、多个未提交的任务是同一个理货员在不同的PDA建立的;
4、多个未提交的任务是同一个部门不同的理货员建立的;
5、多个未提交的任务共同点为未提交且每个任务有部分运单已扫描;
中转业务处理现状:
1、同一库区任务未提交前,任务下拉扫描明细会获取该库区所有的运单号信息,包含已扫、未扫的运单号;
2、运单号详情包含“运单号、重量、体积、状态”
3、同一库区不同任务已扫描的运单CE端需要重传已扫描信息给中转(中转业务要求)
解决方案分析
方案一、不同任务下拉扫描详情时状态为已扫描的运单号理货员不重扫。
有利端:
1、不同任务理货员不需要手动重扫运单状态为已扫描的运单
2、节省了人力:快递体积小、数量多,假如新建任务后需要重扫已扫描的运单,会带来人力的大量消耗
不利端:
1、同一个理货员创建的不同任务,由新建任务时CE端自动同步扫描的运单号信息,会导致扫描时间不一致;
2、不同的理货员创建的不同任务,新建任务时CE端自动同步扫描的运单号信息中理货员工号不一致,会导致理货员工作量无法统计的问题;
3、导致PDA页面显示的已扫描的运单号错乱,理货员不清楚此种运单是其他任务已扫描过的还是此任务刚刚扫描的
方案二、不同任务下拉扫描详情时库区已扫描的运单号剔除
1、中转后端不给CE端库区已扫描的运单号信息;
2、中转后端给CE端库区所有已扫、未扫的运单号信息,CE端接收时剔除已扫状态的运单
有利端:
1、不同任务CE端不需要自动同步已扫描的运单号,CE端系统业务逻辑处理简单些。
不利端:1、中转后端生成交接单可能会出错,不同任务扫描的运单CE端未重新同步;
2、任务未提交前假如PDA出错,新建的任务没有了已扫运单信息,任务提交后生成的交接单可能出差错。
方案三、不同任务下拉扫描详情时状态为已扫描的运单号理货员重扫
有利端:1、可以保持此业务跟以前其他装车业务逻辑一致
不利端:1、不同任务已扫运单还需要理货员手工重扫,增加的大量的人力,系统体验差;
2、已扫描状态的还需要重扫,会导致PDA页面显示的已扫运单错乱,理货员不清楚此种运单是其他任务已扫描过的还是此任务刚刚扫描过的;
3、不同的任务中转得到的此运单扫描详情时间不一致。
最后我们解决是在任务最后提交的时候才绑定运单与任务的关系,同一库区可以下拉所有未提交的运单。避免了任务创建却pda出现问题导致了“死”运单等情况。
安卓能支持Sqlite多线程操作吗
一个状态修改引起的问题
现在有个情况,就是我本地提交一个订单成功以后修改本地数据库的一个状态让其在下拉列表中消失,现在可能接口请求成功后修改本地数据库出现异常(一般来说不会出现,但是在数据库表结构意外修改,以及多线程的话可能会导致数据库的访问异常,概率很小,但是小概率事件我们也得做处理。),如果异常的话我们本地可能还会存在这个订单,那么客户下次可能还会再次提交,这时候就会导致重复提交的问题,即便后台配合你做处理,对重复提交的订单本地做相应的逻辑处理(本地删除操作),但是你还得等到下次提交才能知道这个订单已经提交,然后在做逻辑操作,这种延迟性的体验效果不是我们想要的那种。
那这个问题就衍生为本地数据库修改失败以后我们该如果处理?
有人说用事务,是的,我也是这么想的,事务回滚本身就是应对异常的一个处理方案,我们可以通过在事务外try….catch,捕获异常然后再次请求,这里可以跟后台商量重复请求给个字断或者抛异常,我们本地做出删除,有人说,那如果一直都出现问题你本地还是没有解决啊,是这样,本来这种数据库操作异常就是小概率事件,对1%存在小概率事件我们有个处理方案1%*1%=1/1000,几次事务提交如果还不能解决,基本上就是项目本身框架可能出现问题,得重新规划,这个另说。
下面就针对这个小概率引发的问题思考!
我们可以在这个异常的代码快进行事务,遇到异常的话数据回滚,然后在catch里在做删除或者重新请求网络的逻辑处理。
try{
trans = cn.BeginTransaction
数据库操作
trans.Commit()
}catch(Exception e){
}安卓能支持Sqlite多线程操作吗
Sqlite对于多线程的读是允许的,但对于多线程的写是不允许的,当一个线程在写,其他线程来读读写就回出现问题,sqlite3返回信息就是”Database is locked”,错误码SQLITE_BUSY,sqlite3对高并发访问支持不好,多线程访问数据库会出现数据库锁定现象。
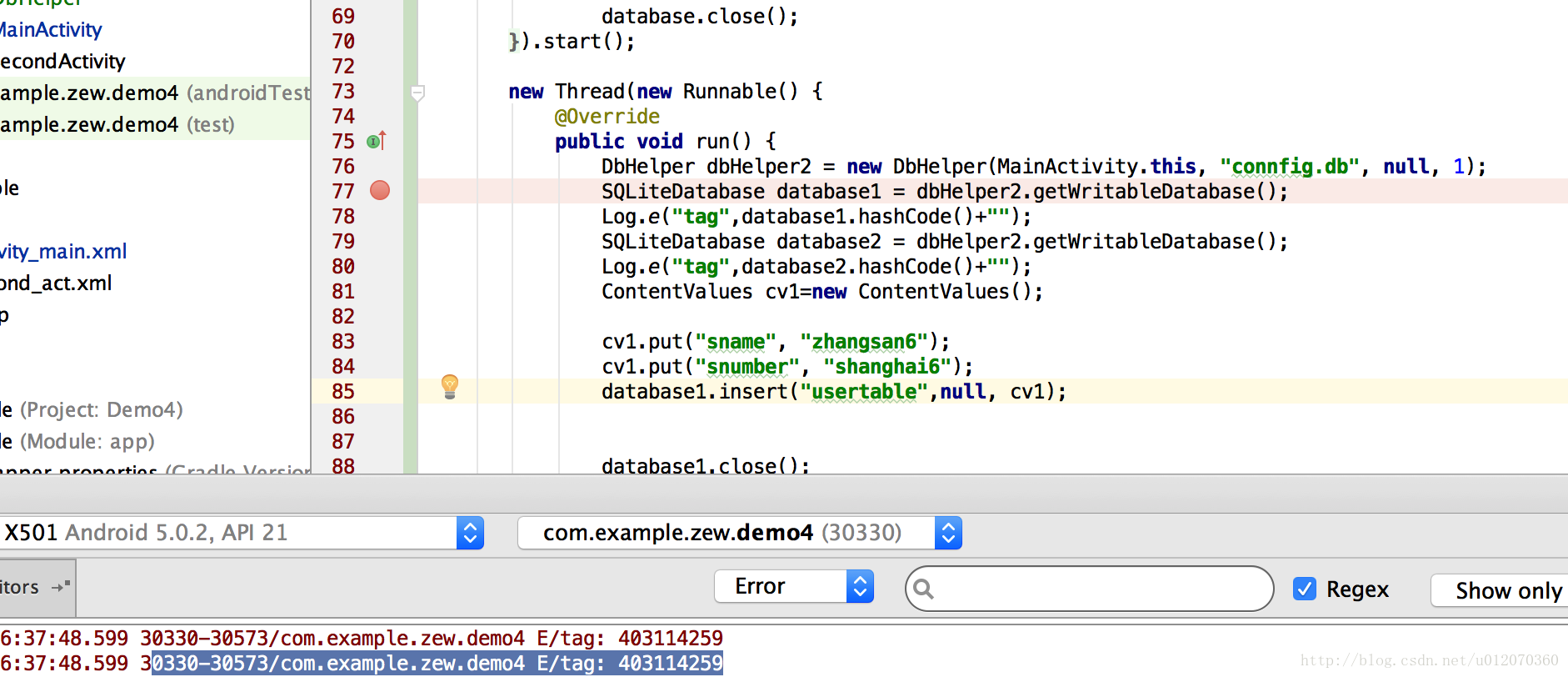
可以查看一个Dbhelper创建两个dbHelper2.getWritableDatabase();看出同一个dbhelper创建的database对象是一个。
所以即便我们把SqliteOpenHelper链接数据库的对象做成一个单例。当我们线程二去写的时候这时候线程一已经把它关闭了,这时候就会得到奔溃的异常。
Thread1和Thread2的都是由getDatabase()方法返回的相同连接。发生的什么事呢,在Thread2还在使用数据库连接时,Thread1可能已经把它给关闭了,那就是为什么你会得到崩溃异常。
我们需要确保在没有任何一个人在使用数据库时,才去关闭它。在StackOverflow上推荐的做法是永远不要关闭数据库。Android会尊重你这种做法,但会给你如下的提示。所以我一点也不推荐这种做法。、
Leak found
Caused by: java.lang.IllegalStateException: SQLiteDatabase created and never closed
正确的做法我觉得是:就是通过一个引用计数器的方式进行,当引用计数器为1的时候就创建,当关闭的时候当引用计数器为0的时候才关闭。
public class DatabaseManager{
private AtomicInteger mOpenCounter = new AtomicInteger();
private static DatabaseManager instance;
private static SQLiteOpenHelper mDatabaseHelper;
private SQLiteDatabase mDatabase;
public static synchronized void initializeInstance(SQLiteOpenHelper helper) {
if (instance == null) {
instance = new DatabaseManager();
mDatabaseHelper = helper;
}
}
public static synchronized DatabaseManager getInstance() {
if (instance == null) {
throw new IllegalStateException(DatabaseManager.class.getSimpleName() +
" is not initialized, call initializeInstance(..) method first.");
}
return instance;
}
public synchronized SQLiteDatabase openDatabase() {
if(mOpenCounter.incrementAndGet() == 1) {
// Opening new database
mDatabase = mDatabaseHelper.getWritableDatabase();
}
return mDatabase;
}
public synchronized void closeDatabase() {
if(mOpenCounter.decrementAndGet() == 0) {
// Closing database
mDatabase.close();
}
}}使用方式:
SQLiteDatabase database = DatabaseManager.getInstance().openDatabase();
database.insert(...);
// database.close(); Don't close it directly!
DatabaseManager.getInstance().closeDatabase(); // correct way每当你需要使用数据库时,你需要使用DatabaseManager的openDatabase()方法来取得数据库。我们会使用一个引用计数来判断是否要创建数据库对象。如果引用计数为1,则需要创建一个数据库,如果不为1,说明我们已经创建过了。
在closeDatabase()方法中我们同样通过判断引用计数的值,如果引用计数降为0,则说明我们需要close数据库。
大致的做法就是在多线程访问的情况下需要自己来封装一个DatabaseManager来管理Sqlite数据库的读写,需要同步的同步,需要异步的异步,不要直接操作数据库,这样很容易出现因为锁的问题导致加锁后的操作失败。
临时文件的产生与解决
数据库主键的选择
牵扯到数据库表的操作,难免就会要设计主键,一个表中是可以没有主键的,主键的好处在于它的主键的作用是保证数据的唯一性和查询速度,如果没有主键也是可以的,只是会影响效率,当我们需要重新设置主键的时候,我建议大家最好不要用跟实际需求业务牵扯到的字段作为主键,因为我们后期可能会对业务进行修改,如果我们以某个实际业务的字段作为主键,这样导致假如需求变了,牵一发而动全身,所以这里得注意,联合主键尽量别用,会导致维护性的问题。
项目设计的时候,往往要在 性能、复杂度、时间==方面,做取舍,”联合主键”之类的是比较增加复杂度的东西,尤其是需求有开动。
而所谓的无关,就是用自增字段或者UUID,或者类似Oracle rowid这样不包含任何业务信息,只代表这条记录在这张表里面位置的信息作为主键。无论业务如何变化,这个字段都不需要做修改(顶多因为业务量变大,修改字段长度,但不需要修改数据本身)。
为什么要加索引
一个表加不加索引不是随便加的,为什么要加?
用法:CREATE INDEX 字段名。语句用于在表中创建索引。
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
明明已经有了主键了为什么还要设置索引?
这个问题如果在非大数据情况下我们是不需要考虑的?那为什么在大数据存储的时候需要加索引呢?
其实键是一种约束,创建索引使用的是 CREATE INDEX 语句,而创建键使用的是 ALTER TABLE ADD UNIQUE / PRIMARY KEY。索引存在于 sysobjects 表中,而键不存在 sysobjects 表中。我认为光从键的作用上来解释是行不通的,得从应用上来解释:假设有一个表,其中有一个字段是身份号,身份号是一个键,此外没有其他索引和键,表中已有 500 万条记录,假设现在要添加一个身份号,为了识别是否重复,得把整个表扫一遍,似乎有点没有必要,如果键也有索引一样的功能,不是挺好么?这样每次插入数据的话就很简单的通告索引判断了而不是把整个表都扫一遍。但加索引也是会消耗性能,每次更新表的时候消耗时间比没有加索引的表的消耗更多的时间。