(一)python爬虫验证码识别(去除干扰线)
1.开发环境与工具
- python27:sklearn、pytesser、opencv等
- pycharm
- windows7
2. 数据集


用request库爬虫抓取某一网站验证码1200张,并做好标注



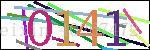


3.验证码识别大概步骤
- 转化成灰度图
- 去背景噪声
- 图片分割
(1)转化成灰度图
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)(2)去除背景噪声
验证码去除干扰线的思想可参考链接:验证码去除干扰线
本文所使用的去除背景噪声的方法:
认真观察我们的实验数据,发现根据线降噪方法来去除噪声是不可行的,因为我们的图片干扰线很粗,和数字差不多粗。那再认真观察一下,1个数字的颜色都是一个‘“色”,那么是否可以跟据颜色来分呢?
博主认真想了下,先转化成灰度图,再通过图像分割把图片分割一下,去除掉边框和部分噪声,这样就分成了4张图,然后统计每张图的灰度直方图(自己设置bins),找到第二大所对应的像素范围,即某一像素范围内像素数第二多所对应的像素范围(像素最多的应该是白色,空白处),取像素范围中位数mode,然后保留(mode+-biases)的像素。这样就可以将大部分噪声去除掉啦。
(这段描述有点复杂,需要一定的图像基础,不懂的,可以看代码del_noise()方法)
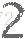
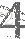
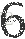
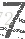
4. 实验方法
(1)使用Google的pytesser识别图片方法,准确率在50%左右
pytesser环境配置参考 https://www.cnblogs.com/lcosima/p/7138091.html
(2)使用机器学习方法KNN,准确率在99.6%
pip install sklearn5.pytesser方法
- 这里im_cut是指:分割好验证码后,传入的子图片
def del_noise(im_cut):
''' variable:bins:灰度直方图bin的数目
num_gray:像素间隔
method:1.找到灰度直方图中像素第二多所对应的像素,即second_max,因为图像空白处比较多所以第一多的应该是空白,第二多的才是我们想要的内容。
2.计算mode
3.除了在mode+-一定范围内的,全部变为空白。
'''
bins = 16
num_gray = math.ceil(256 / bins)
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
# print hist[i][0]
lists.append(hist[i][0])
second_max = sorted(lists)[-2]
bins_second_max = lists.index(second_max)
mode = (bins_second_max + 0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
if im_cut[i][j] < mode - 15 or im_cut[i][j] > mode + 15:
# print im_cut[i][j]
im_cut[i][j] = 255
return im_cut
# 替换文本
def replace_text(text):
text = text.strip()
text = text.upper()
rep = {'O': '0',
'I': '1',
'L': '1',
'Z': '7',
'A': '4',
'&': '4',
'S': '8',
'Q': '0',
'T': '7',
'Y': '7',
'}': '7',
'J': '7',
'F': '7',
'E': '6',
']': '0',
'?': '7',
'B': '8',
'@': '6',
'G': '0',
'H': '3',
'$': '3',
'C': '0',
'(': '0',
'[': '5',
'X': '7',
'`': '',
'\\': '',
' ': '',
'\n': '',
'-': '',
'+': '',
'*': '',
'.': '',
';': ''
}
#判断是否有数字,有数字直接返回第一个数字,不需要字符替换
print text
if len(text) >= 1:
pattern = re.compile(u'\d{1}')
result = pattern.findall(text)
if len(result) >= 1:
text = result[0]
else:
# 字符替换,替换之后抽取数字返回
for r in rep:
text = text.replace(r, rep[r])
pattern = re.compile(u'\d{1}')
result = pattern.findall(text)
if len(result) >= 1:
text = result[0]
return text
- 主方法
#im_cut = [im_cut_1, im_cut_2, im_cut_3, im_cut_4]
for i in range(4):
im_temp = del_noise(im_cut[i])
im_result = Image.fromarray(im_temp.astype('uint8'))
#使用pytesser识别
text = image_to_string(im_result)
#做文本替换处理
text_rep = replace_text(text)
#获得预测结果
pre_text.append(text_rep)
pre_text = ''.join(pre_text)- 结果
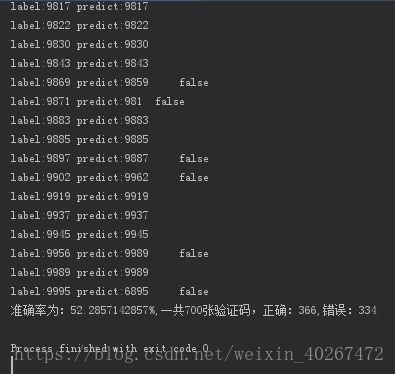
6.KNN分类(sklearn)
(1)先转成灰度图,去背景噪声,分割1200张已标注好的图片,得到4800张子图片;

(2)用knn训练分类器,训练集:测试集=0.8,训练结果精度达到99%以上;
(3)使用训练好的模型,进行实际验证码预测,效果不错。

# -*-coding:utf-8-*-
import numpy as np
from sklearn import neighbors
import os
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.externals import joblib
import cv2
if __name__ == '__main__':
# 读入数据
data = []
labels = []
img_dir = './img_train_cut'
img_name = os.listdir(img_dir)
# number = ['0','1', '2','3','4','5','6','7','8','9']
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
# cv2读进来的图片是RGB3维的,转成灰度图,将图片转化成1维
image = cv2.imread(path)
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = im.reshape(-1)
data.append(image)
y_temp = img_name[i][-5]
labels.append(y_temp)
# 标签规范化
y = LabelBinarizer().fit_transform(labels)
x = np.array(data)
y = np.array(y)
# 拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 训练KNN分类器
clf = neighbors.KNeighborsClassifier()
clf.fit(x_train, y_train)
# 保存分类器模型
joblib.dump(clf, './knn.pkl')
# # 测试结果打印
pre_y_train = clf.predict(x_train)
pre_y_test = clf.predict(x_test)
class_name = ['class0', 'class1', 'class2', 'class3', 'class4', 'class5', 'class6', 'class7', 'class8', 'class9']
print classification_report(y_train, pre_y_train, target_names=class_name)
print classification_report(y_test, pre_y_test, target_names=class_name)
# clf = joblib.load('knn.pkl')
# pre_y_test = clf.predict(x)
# print pre_y_test
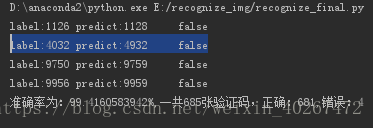
# print classification_report(y, pre_y_test, target_names=class_name)结果截图:
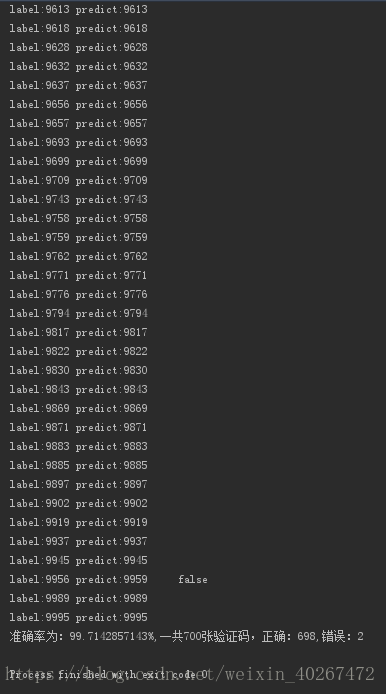
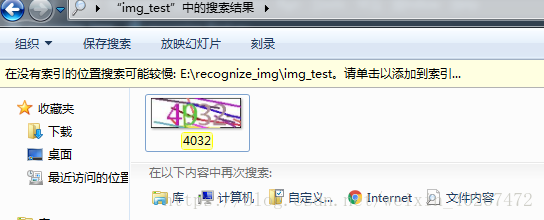
ps:在运行过程中,程序还可能会帮你检测出人工标错的哟!
喜欢就点个赞吧~~~一起在程序猿路上行走!!!加油
——肆无忌惮走天下