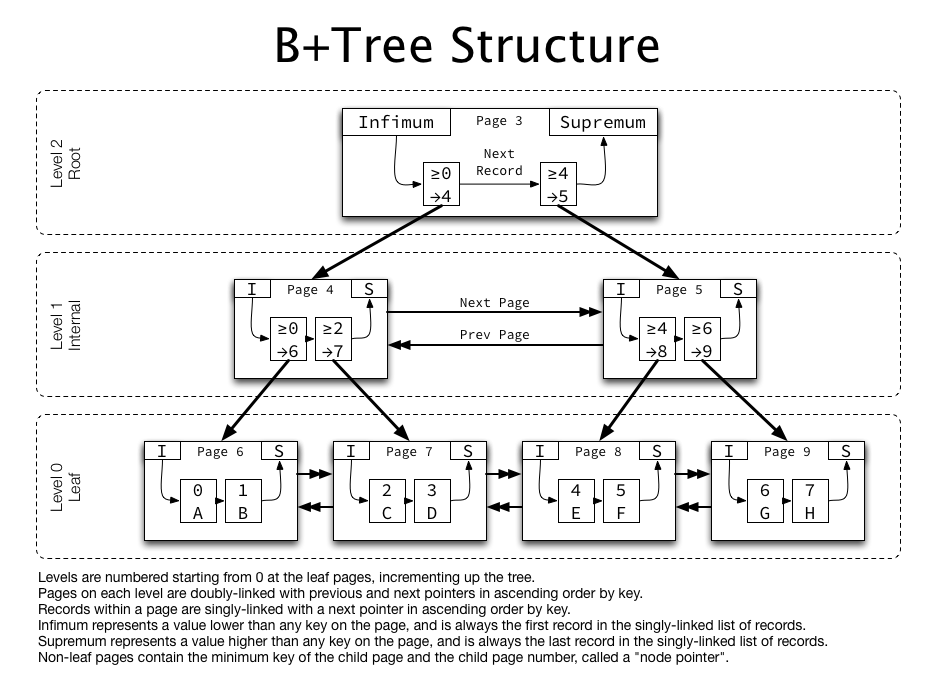
1 Mysql 索引结构B+Tree
- B+Tree数据结构适合读取外存数据,不适合内存数据
- B+Tree分为叶子节点和非叶子节点,非叶子节点仅仅包含key以及左右指针,通过与key比较判断查找方向,与B-tree不同,B-tree除了key还保存有其它信息,减少存储节点空间,降低树的高度,减少IO读取次数
- 叶子节点包括全部数据,并且升序排序,便于进行范围查找
- 平衡树,具有相同的深度
- 为什么所有数据在叶子节点
通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
根据特性,从应用上面来说:
- 主键不建议用uuid,存储空间太大,因为主键也是索引,每个page存储的key减少,影响B+tree的效率
- 尽量选择区分度高的列作为索引
- 索引列不能参与计算,保持列“干净”
- 尽量的扩展索引,不要新建索引
- 最左匹配原则
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性
参考连接:https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/