爬取今日头条图集 进入今日头条首页:https://www.toutiao.com/
步骤:1、查看网页,查找我们需要的URL,分析URL
2、获取网页内容,分析内容
3、定位我们需要的内容
4、将数据存储
在搜素框 输入要搜索的内容(例如:街拍),然后选择图集,F12检查,查看Ajax请求:

第一次Ajax请求:

再往下拉,触发第二次、第三次Ajax请求:(下图第二次Ajax请求)

分析URL后发现发现规律只有offset不同(第一次offset=0,第二次offset=20,第三次offset=40、、),其他内容都相同,此时我们得到了当前页面的所有图片文章的URL(每条只可以看到四张,但是里面本应该有8张,如下图一),但是我们得不到具体一个里面的所有图片。故我们需要再进去此URL,再去分析具体一篇图片文章的所有图片URL(下图二)。


然后我们再分析get请求的Response,我们去分析返回值,查找出每张图片的URL,如下图我们找出了图片对应的URL路径:
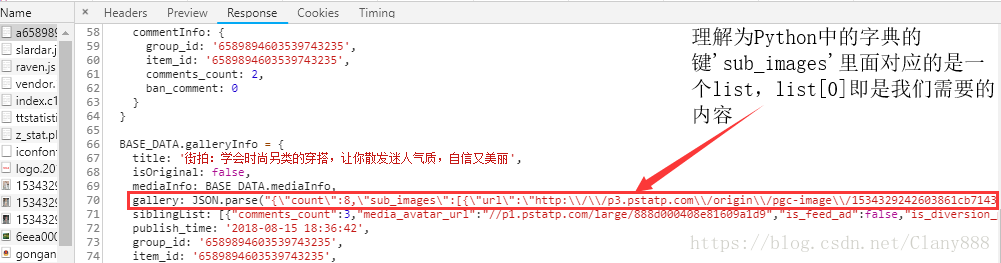
所有的分析到这里就结束了,接下来就是代码实现。
完整代码如下:
-
import re -
import requests -
import json -
import os -
from urllib import request -
filename = 'Download' -
if not os.path.exists(filename): -
os.mkdir(filename) # 新建文件夹用于存放图片 -
i = 0 -
strdes = 0 -
offset = 20 -
while i < 10: -
headers = { -
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', -
} -
# 第一层 url -
url = 'https://www.toutiao.com/search_content/?offset={}&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery'.format(str(offset*i)) -
response = requests.get(url, headers=headers) -
res_dict = response.json() -
# print(res_dict) -
# address_url = -
res_dict_data = res_dict['data'] -
# print(res_dict_data) -
# print(type(res_dict_data)) -
for url_dict in res_dict_data: -
# 获取到的第二层url -
url = url_dict['article_url'] -
print(url) -
response = requests.get(url, headers=headers) -
info = response.text -
re_m = r'gallery: JSON\.parse\((.*)\),' -
msg = re.search(re_m, info) -
if msg == None: -
break -
msg_info = msg.group(1) -
msg_str = json.loads(msg_info) -
msg_dict = json.loads(msg_str) -
# print(msg_dict) -
info_msg = msg_dict['sub_images'] -
for j in info_msg: -
images_url = j['url'] -
# print(images_url) -
# img_name = filename + '/' + images_url.split('/')[-1] + '.jpg' -
img_name = filename + '/' + str(strdes) + '.jpg' -
strdes += 1 -
print(img_name) -
request.urlretrieve(images_url, img_name) -
i = i + 1