为保证作者原意,不做翻译
Get off the deep learning bandwagon and get some perspective
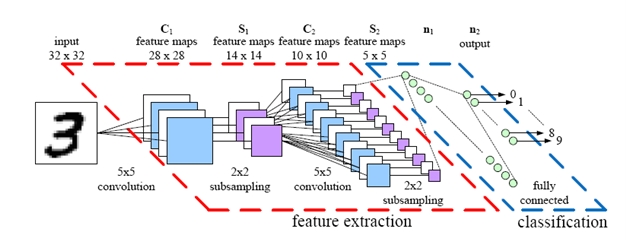
Disclaimer: This post is a bit cynical in tone. In all honesty, I support deep learning research, I support the findings, and I believe that by researching deep learning we can only further improve our classification approaches and develop better methods. We all know that research is iterative. And sometimes we even explore methods decades old, applying only a slightly different twist, yielding significantly different results — and thus a new research area is born. That’s the way machine learning research works, as it should.
The following rant is actually more of an indictment of how we treat current “hot” machine learning algorithms — like “silver bullets” and the magic pill to cure our classification ailments. But these algorithms are not silver bullets, they are not magic pills, and they are not tools in a toolbox — they are methodologies backed by rational thought processes with assumptions regarding the datasets they are applied to. By spending a little bit more time thinking about the actual problem rather than blindly throwing a bunch of algorithms at the wall and seeing what sticks, I believe that we can only further the research.
I feel like every time I get on /r/machinelearning, HN, or DataTau, there’s something being said about deep learning — and more times than not, it just feels like hype.
And I’m not being negative because I think the research is a dead end. Far from it. It’s a fantastic research area and there is still far more left to explore.
I’m just sick of the hype.
Really, stop treating deep learning like Restricted Boltzmann Machines and Convolutional Neural Networks will solve all of your image classification woes.
Yes. They are powerful.
And yes, they are capable of tremendous classification accuracy…provided that they are applied to the right type of problem.
But also realize that deep learning is a hot topic in machine learning right now. And to a certain extent, there is a “bandwagon” trend that happens in the machine learning community — and it didn’t start with deep nets either.
Don’t believe me? Read on.
Why am I talking about deep learning on a computer vision blog?
Because let’s face it. Unless you are doing some very strict forms of image processing, you can’t have computer vision without some sort of machine learning.
From clustering, to forming a bag-of-words model, to soft codeword assignment, to learning distance metrics, to dimensionality reduction, to classification, regression (i.e. pose estimation using regression forests, thus making the Xbox 360 Kinect possible), computer vision utilizes machine learning in an incredible amount of tasks.
That all said, if you are working with computer vision, you’ll also likely be utilizing some sort of machine learning.
In terms of deep nets, computer vision and machine learning become even more entwined — look no farther than convolutional neural networks where we try to learn a set of kernels.
With the rise and fall of machine learning, the tide will thus affect computer vision as well.
And with the tides, also come the trends…
Perpetual Perceptron Troubles
Let me draw your attention to Rosenblatt’s Perceptron algorithm (1958). Following his publication, Percepton based techniques were all the rage.
But then, Minsky and Papert’s 1969 publication effectively stagnated research in neural nets for almost a decade, demonstrating that the Perceptron could not solve the exclusive-or (XOR) problem. Furthermore, the authors argued that we did not have the computational resources required to build and maintain large neural nets.
This single paper alone almost killed neural network research.
Bummer.
Luckily, the backpropagation algorithm and the research by Rumelhart (1986) and Werbos (1974) were able to bring back the neural net from what could have been an untimely demise.
Arguably, without the contribution of these researchers, deep learning may have very well never existed.
Support Vector Machines
Next up on the bandwagon: SVMs.
In the mid-90’s Cortes and Vapnik published their seminal Support-vector networks paper.
And you might as well thought machine learning was solved, even prompting Dr. Lipo Wang to say:
SVMs have been developed in the reverse order to the development of neural networks (NNs). SVMs evolved from the sound theory to the implementation and experiments, while the NNs followed more heuristic path, from applications and extensive experimentation to the theory.
That’s a pretty strong statement, especially in today’s context of deep learning.
And while I’m taking this quote (slightly) out of context, the real reason I am using this quote is to demonstrate that there was a time where machine learning researchers thought that SVMs had effectively “solved” classification for what it was.
SVMs were the future. Nothing could beat them…including neural networks.
Ironic, isn’t it? Because now all we can talk about is stacking Restricted Boltzmann Machines and training massive Convolutional Neural Nets.
But let’s keep this bandwagon going.
Trees. Trees. Trees.
Then, following the SVM craze, we had ensemble based methods.
Building on the work of Amit and Geman (1997), Ho (1998), and Dietterich (2000), the late Leo Brieman contributed his Random Forests paper to the machine learning community in 2001.
We hopped on the bandwagon again, loaded up a bunch of trees, threw in our shovels, and headed off to the closet nursery to setup camp.
And honestly, I’m no different — I drank the Random Forest Kool-Aid, so to speak. My entire dissertation involved how to utilize Random Forests and weak feature representations to outperform heavily engineered state-of-the-art approaches, fixated on single datasets.
And to this day I still find myself slightly biased towards ensemble and forest based methods.
Is this bias a bad thing?
I don’t think so. I think it’s natural, and even human to a degree, to be biased towards something you have painstakingly studied for a significant chunk of your life.
The real question is: can you do it without the hype?
Now we are in the present day. And there’s another “hot” learning model.
Deep learning, deeply flawed?
But it turns out, maybe we can do better do that ensemble based methods.
Maybe we can learn hierarchical feature representations using deep learning.
Sounds awesome, right?
But now we’re on yet another bandwagon. Let’s just stack a bunch of RBMs and see what happens!
I’ll tell you what happens. You leave your model to train, cross-validate, and grid search parameters for over a week (and maybe longer, depending on how large your net is and the computational resources at your disposal) just to have your accuracy increase by a tenth of a percent on ImageNet.
Okay, so I’m being very cynical right now. I’ll admit to that.
But here’s the problem: we need to stop treating machine learning algorithms like they are a silver bullet.
The fact is, there is no silver bullet when it comes to machine learning.
Instead, what we have is an amazing, incredible set of algorithms with both theoretical assumptions and empirical evidence, demonstrating they are capable of solving a certain subset of classification problems.
The goal here is to be able to identify the algorithms that perform well in certain domains, not claim that one method is the end-all to machine learning, marking classification as “case closed”.
That all said, I’m honestly not trying to bash deep learning. These deep nets are incredibly powerful, as the scientific community has shown. And I wholeheartedly support their research and findings.
Intriguing properties of neural networks
However, the latest article by Google, Intriguing properties of neural networks, has suggested there is a gaping hole lurking in every deep neural net.
In their paper, the authors are able to construct “adversarial images” — that is, taking an image and perturbing the pixel values in such a way that it makes it (effectively) identical to human eye, but can lead to a mis-classification by the deep net.
These adversarial images were constructed in a fairly involved manner — the authors purposely adjusted pixel values in an image to maximize the network’s prediction error, leading to an “adversarial image”, that when used as input to the net, is nearly always misclassified, even when applied to different neural nets trained on different subsets of the data.
And if these small changes in images (that are again, for all intents and purposes, completely undetectable to the human eye) can lead to performance completely falling off a cliff, what does that imply for real-world datasets?
Because let’s face it, real-word datasets are not clean like MNIST. They are messy. They often contain noise. And they are far from perfect — this is especially true when we migrate our algorithms from academia to industry.
So, in practice, what does it mean?
It means that methods learning from raw pixel based features still have a long way to go.
Deep learning is here to stay. And honestly, I think it’s a good thing.
There is some incredible researching going on right now, and I personally get excited over Convolutional Neural Nets — I think for the next five years Convolutional Neural Nets will continue to dominate in certain image classification challenges, such as ImageNet.
I also hope the deep learning field stays active (I believe it will), because no matter what, our research and insights gained from studying deep nets will only help us create an even better approach years from now.
But in the meantime, maybe we can drop the buzz down just a little?
The Takeaway:
There is no single machine learning model that is the “silver bullet” to solve all your problems.
In fact, it’s best if we don’t treat machine learning models as tools in our toolbox at all — I believe that is where most of our problems come from.
Instead, we need to spend a lot more time thinking about the actual problem we are trying to solve instead of throwing a bunch of algorithms at the problem and seeing what sticks.
Because when we sit down and think about a problem, when we take the time to not only understand what our feature space “is” and what it “implies” in the real-world — then we are acting like machine learning scientists. Otherwise, we just a bunch of machine learning engineers, blindly performing black box learning and operating a set of R, MATLAB, and Python libraries.
The takeaway is this: machine learning isn’t a tool. It’s a methodology with a rational thought process that is entirely dependent on the problem we are trying to solve. We shouldn’t blindly apply algorithms and see what sticks. We need to sit down, explore the feature space (both empirically and in terms of real-world implications), and then consider our best mode of action.
Sit down, take a deep breath. And invest the time to think it through.
And most importantly, avoid the hype.