- Server节点能否在配置文件里配置自身的Server地址?
- Server是否配置registerWithEureka和fetchRegistry有什么区别?
- Server和Client节点配置全部的Server地址和部分Server地址有什么区别?
- Server回收服务信息的自我保护机制是什么?需要注意什么?
- Server节点间的服务信息同步的流程是怎么样的?
我们就以下图为例来解释上述问题:
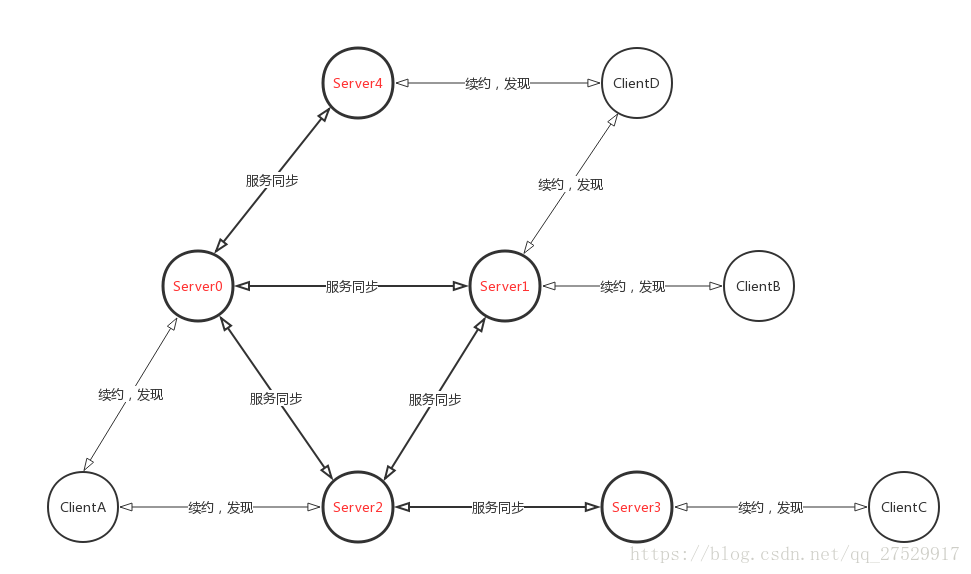
上图已经很直接的展示了Server和Server之间,Server和Client之间可能的连接情况,他们之间的连线情况就代表着配置文件中的服务配置。
第一个问题:Server节点能否在配置文件里配置自身的服务发现地址?
可以的!当一个Server解析配置的集群地址时,会过滤掉自身的地址,这样服务同步时就不需要同步自身了。我们配置多个Server时,不需要手动的排除Server自身的发现地址。
就像上图的Server 0,1,2的配置,每个节点可以都加上他们3个的服务发现地址,但他们在实际初始化时,每个Server里只会生成2个用于数据同步的内置Node,比如 Server 0 初始化时生成1和2的数据同步Node,类名叫 PeerEurekaNode。
第二个问题:Server是否配置registerWithEureka和fetchRegistry有什么区别?
其实每一个Eureka Server Node都内置了一个Eureka Client,也就是说一个Server Node节点可以接受其他Client的注册,也可以作为一个Client注册到其他Server上,被其他Client发现和调用。Server Node上的Server和Client可以理解为两个容器,他们仅仅在初始化时打交道,之后就没有什么关联了。
registerWithEureka和fetchRegistry的默认值都是true,他们都是客户端配置,也就是eureka.client开头的配置信息。
通过上述说明就很好理解这两个参数设置与否的区别了:
- registerWithEureka:是否要注册到其他Server上。如果我的Server上其实开放了一些Http接口供调用,那么就需要注册,这样其他的Client才能发现我的服务,才能通过RPC调用我提供的Http接口。如果我的Server没有提供对外Http接口,那么这个参数可以设置为false。
- fetchRegistry:是否需要拉取服务信息。和是否注册一样,如果我的Server需要调用其他的Client的Http接口,那么就需要获取相应的服务发现信息,这样才能正常的调用。同时这个参数还有一个重要的作用,就是决定Server在初始化时是否立即全量同步其他节点的服务信息!!!Server初始化时会先初始化其内置的Client。若配置了fetchRegistry=true,那么Client在初始化时会从其他Server全量拉取服务信息,放进Client容器中。Server在初始化时会尝试同步Client容器里的服务信息,如果fetchRegistry=false,服务信息不存在,只能被动的等其他Server节点以增量的形式同步过来(Client在执行注册和心跳时对应的注册Server节点会广播此事件,同步给其他的Server节点。当其他Server节点还没有此服务信息时,改为注册此服务信息)。当然正常的通过心跳来同步,最多也仅需要30S而已,是否需要设置此参数就看各自的需求了。
第三个问题:Server和Client节点配置全部的Server地址和部分Server地址有什么区别?
这个问题主要的牵扯到了Server节点间的同步机制。
Client在与Server交互时,只会与其中的一个Server进行交互。
Server之间的数据同步和Server与Client间的数据交互使用的是同一个Http接口,比如注册,心跳,状态更新,关闭服务等等。只是Server与Server之间同步时,会有一个Header参数,x-netflix-discovery-replication = true ,Server通过这个标识来判断当前请求是来自Server还是来自Client。如果 x-netflix-discovery-replication不存在,则指明请求来自Client,Server在处理此请求时还会将请求广播给配置上的其他Server节点,在广播请求时,Header带上x-netflix-discovery-replication=true。当其他Server节点接受到此请求时,通过此Header参数判断是一个Server同步请求,因此只处理此请求,而不再广播。Server之间的数据同步只传播一次!!!
如上图所示,根据以上原则:
- ClientD如果选择和Server4交互,那么Server4将服务信息同步给Server0,ClientA能发现ClientD;
- ClientD如果选择和Server1交互,那么Server4将服务信息同步给Server0,2,ClientA,B都能发现ClientD;
- ClientC无论如何也不能发现ClientD
- ClientC因为只和Server3交互,当Server3宕机时,其就失去了与Server集群的联系,但因为其还保存有ClientA的服务信息,所以不影响其与ClientA的调用 ( 前提是ClientA正常与Server2交互,如果其一直与Server0交互,那么Server2不会传播ClientA的服务信息 )。但ClientA发生的变化其得不到通知,而且后续新增的其他服务也发现不了。
- 在Server3宕机时,Server2当时还保存着ClientC的服务信息,在那个时间,其他服务还是能通过Server2发现ClientC的,但是因为ClientC的不能续约,在90S后Server2将删除ClientC的服务信息。ClientC与服务集群基本隔离。
第四个问题:Server回收服务信息的自我保护机制是什么?需要注意什么?
Server每隔60S执行一次服务信息回收,移除那些心跳时间超时的。能够回收有3个前提:
- 心跳信息超时,也就是回收时间距离上次心跳时间超过90S。
- 开启了租约过期功能,默认是开启的。
- 未触发自我保护机制。所谓的自我保护机制,指的是上一分钟内,服务实际发送心跳的总数超过预计总数的85%,可能近似理解为正常存活的Client超过85%。
我在上一篇关于Server端的定时任务里对自我保护机制有较详细的说明,这里就不再复述了。
那需要注意些什么?如果你的Client个数较少,比如就5个,或者说同一个Server对应的Client就5个,那么当其中的一个宕机了,1/5=20%,直接就触发了自我保护机制,宕机的服务信息会一直存在,不会被回收。对于这种情况,可以设置Server触发自我保护机制的临界值,renewalPercentThreshold = 0.85,默认是85%,可以修改成适当的值,比如0.5。
第五个问题:Server节点间的服务信息同步的流程是怎么样的?
Server在初始化时,会根据配置信息生成与其他的Server同步的客户端。每当Server接收到Client的服务请求时,会先处理请求,然后将自身作为一个Client的角色,用相同的请求信息去请求配置里的那些Server节点。会将同步请求封装成一个Task,然后存入一个Queue中,Server定时的提取Queue里的任务,批量的处理它们。
也就是说Server之间的服务同步是异步执行的,而不像Zookeeper一样,每个操作都需要过半数的节点执行成功后才返回给Client。同时Server之间的同步只会传播一次,它们通过Header里的一个参数来表名是来自Client的请求还是Server的请求。如果是Server的请求,那么接收到此请求后不会再进行传播。就好像上图中的Server 0接收到Client A的服务请求,然后将此请求传播给Server 1,2,4。这3个Server接收到请求后,通过Header参数判断是Server间的数据同步,就不会再讲此请求传播给他们各自配置上的节点,比如Server 2不会传播给Server 3,也就时Client A的服务新不可能传播到Server 3上,Client C不可能发现Client A。