版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ZENGZISUZI/article/details/81153855
编码
- ASCII:大小写英文字母、数字和一些符号
- GB2312:在ASCII的基础上,添加了中文字符
- Shift_JIS:在ASCII的基础上,添加了日文字符
- Euc-kt:在ASCII的基础上,添加了韩文字符
- Unicode:为了避免在多国语言混合的文本中显示出来乱码的问题,将所有语言都统一到一套编码里。
ASCII编码时一个字节,而Unicode是两个字节,如果使用Unicode同意的编码,编写的基本都是英文的话,
Unicode会比ASCII编码需要多一倍的存储空间,所以本着节约子资源的精神,出现了将Unicode编码转换为可变长编码“UTF-8”编码。UTF-8把一个Unicode字符根绝不同的数字大小编写成1-6个字节,根绝不同的字符分配不同的字节数。
在python源文件开头需要添加以下说明:
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。另外在编辑器保存时也应该将其保存为UTF-8的编码格式。以免产生不必要的乱码。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-python的字符串
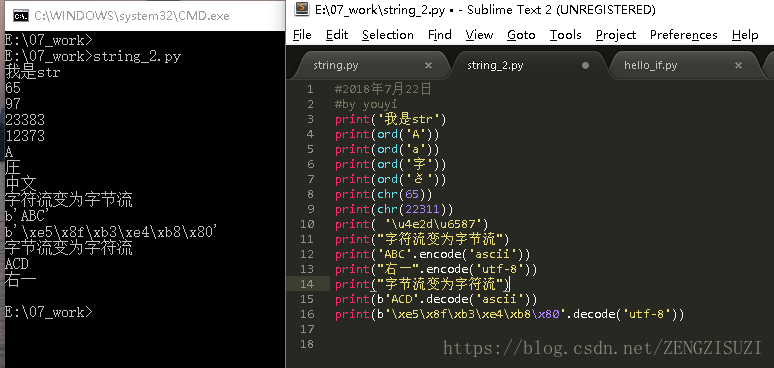
- 在python3版本中,字符串以Unicode编码,可以支持多语言。
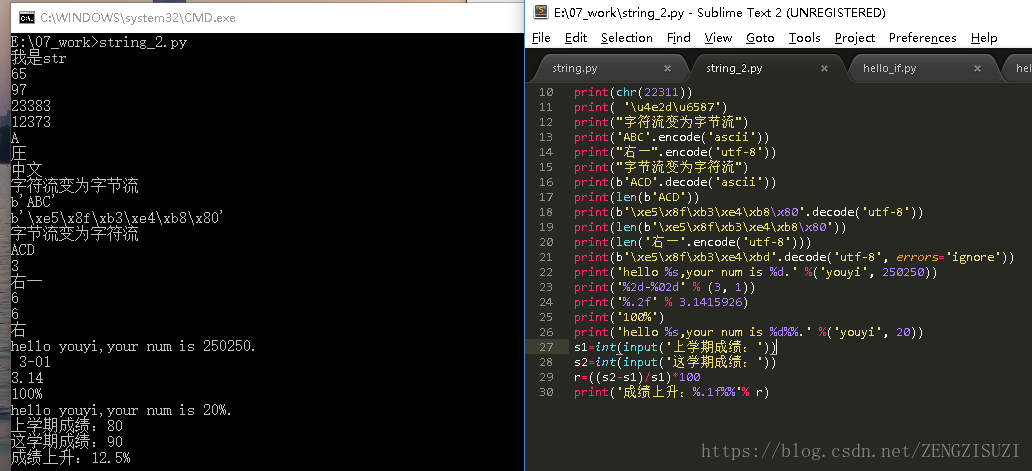
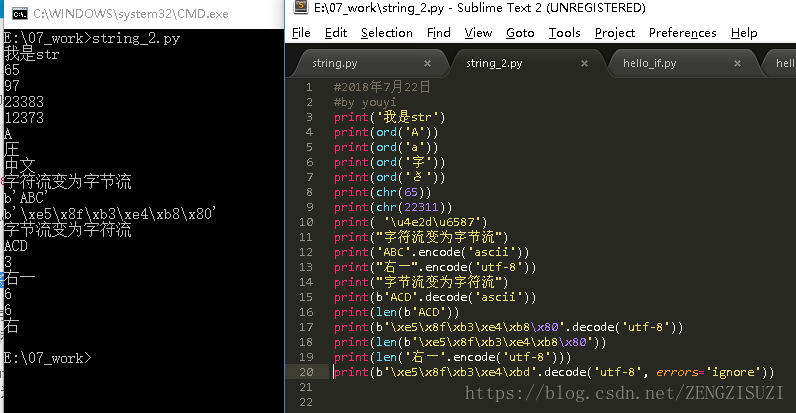
- 字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节,若是在网络上传输,以及存储在磁盘上,则需要将str变为以字节为单位的bytes
- python对bytes类型的数据以带b前缀的单引号或双引号表示。以Unicode表示的str通过encode()方法可以编码为指定的bytes。
- 可以使用errors=’ignore’标识忽略错误字节
- len()函数计算str的字符数或bytes的字节数。
- 1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节
格式化
采用格式化的方式与C语言一致,使用%运算符用来格式化字符串。%s表示用字符串替换,%d表示用整数替换。
%d:整数
%f:浮点数
%s:字符串
%x十六进制整数
转译
当 想打印“%”字符时,可以通过%进行转译表示