参考 Python从零开始系列连载,by 王大伟 Python爱好者社区
参考 Hellobi Live | 1小时破冰入门Python
参考 《简明python教程》
Note: 更多连载请查看【python】
目录
文件操作
1 什么是文件
文件是存储在外部介质的数据集合,通常可以长久保存(前提是这个介质不易损坏)
通俗点说,文件就是存放数据的地方
2 绝对路径与相对路径
打开文件操作需要3个步骤:
1.找出文件存放的路径,打开文件
2.对文件修改操作
3.关闭文件
说到找出文件的存放路径,我们就必须弄清楚绝对路径和相对路径的概念
2.1 绝对路径
绝对路径指的是从最初的硬盘开始一直进入到文件位置
eg:
E:\编程学习资料\爬取高清大图.py
E:/编程学习资料/爬取高清大图.py
下面以在ubuntu系统下一张图片的路径为例
open('/root/userfolder/0.jpg')结果为
<_io.TextIOWrapper name='/root/userfolder/0.jpg' mode='r' encoding='ANSI_X3.4-1968'>2.2 相对路径
相对路径指的是当前所在位置继续向文件所在位置进发
open('0.jpg')结果为
<_io.TextIOWrapper name='0.jpg' mode='r' encoding='ANSI_X3.4-1968'>可调用opencv的库(前提是配置好了)可视化一下图片,没有安装opencv库的可以用PIL中的Image库,下面以Opencv库为例子,显示出图片
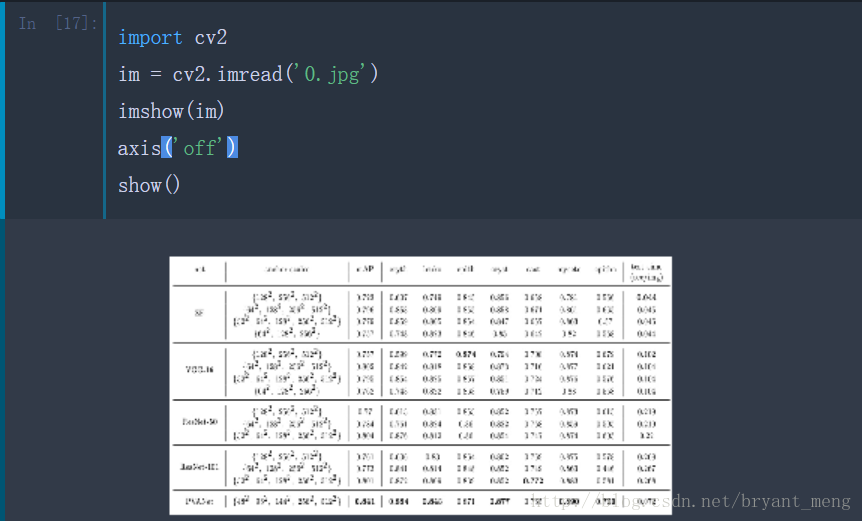
import cv2
im = cv2.imread('0.jpg')#相对路径
imshow(im)
axis('off')
show()图片就显示出来了
3 文件的编码
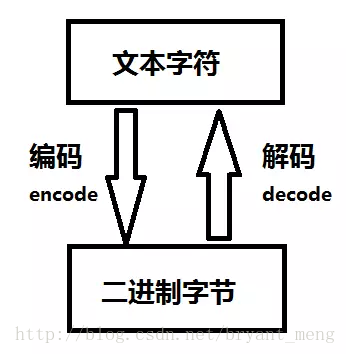
根据编码的不同,可以将文件分为文本字符和二进制字节
文本字符,如汉字、英文字母、数字、标点等,字符是为了显示
二进制字节是计算机存储的形式,在计算机中,任何数据都是01串构成的二进制字节
当我们打开文本,看到的是字符,最终保存时候存储的是二进制字节,文本字符的编码可以在windows自带的记事本保存时选择各种编码。
Unicode 是「字符集」
UTF-8 是「编码规则」
其中:
字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
做个简单的比喻, unicode相当于中文, UTF-8, UTF-16等相当于 行书, 楷书, 草书等各种书写方式.讲到细节, 最重要的一点是. 为什么有了UTF-16, 还会有UTF-8呢? 干嘛搞这么多复杂的编码呢? 一种编码不很好么? 答案是为了节省带宽, 因为早期互联网带宽非常昂贵.(节选自知乎)
字符串等所有的文本字符使用的是unicode编码
使用encode()进行编码为utf-8
使用decode()可以将utf-8文件解码为文本字符
s1 = '莫莫,你好'
s2 = s1.encode()
print (s2)
type(s2)这里将文本字符中的字符串编码为默认的utf-8文件
结果为
b'\xe8\x8e\xab\xe8\x8e\xab,\xe4\xbd\xa0\xe5\xa5\xbd'
bytes编码前的字符串显示为str字符串类型
编码后的字符串显示为bytes字节类型
当然,除了utf-8编码,还有很多其他编码,比如gbk编码
s3 = s1.encode('gbk')
print (s3)
type(s3)结果为
b'\xc4\xaa\xc4\xaa,\xc4\xe3\xba\xc3'
bytes我们将utf-8解码回来,解码为unicode编码。
s2.decode()结果为
'莫莫,你好'但是,如果我们将编码出的utf-8使用gbk解码,则会报错
s2.decode('gbk')结果为
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-29-8f3ab4505d84> in <module>()
----> 1 s2.decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xab in position 2: illegal multibyte sequence从错误原因看出,某位置的内容不能被解码出来
想想原因,可以这样理解
一句中文,可以翻译为英文,也可以翻译为韩文
而只懂中文和英文的翻译A可以将中文翻译(编码)为英文,也可以将英文翻译(解码)为中文
如果想要让翻译A去将韩文翻译(解码)为中文,他不懂韩文,做不到啊!
我们将gbk编码后的内容解码
s3.decode()结果为
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-30-c1fbb3df3ed5> in <module>()
----> 1 s3.decode()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 5: invalid continuation byte报错了!因为我们解码没加参数,默认的是用utf-8解码
所以,我们得用gbk解码:
s3.decode('gbk')结果为
'莫莫,你好'总结一下,utf-8编码出的内容只能用utf-8解码,gbk编码的内容只能用gbk解码!encode()和decode()默认是utf-8模式。
4 文件的打开、写入和关闭
通常,我们Python对文件的操作有文件打开、文件内容读取、文件修改、文件关闭等
4.1 文件打开
使用open()来打开文件
文件对象 = open(文件名, ‘模式’ )
模式是可选参数,通常有以下几种:
w 以写方式打开,如果这个文件不存在,则创建这个文件
r 以只读方式打开
a 以写方式打开,写的内容追加在文章末尾(像列表的append())
b 表示二进制文件
+ 以修改方式打开,支持读/写
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )怎么记住呢?
w = write 写
r = read 读
b = bytes 二进制
a = append 追加
然后可能组合一下
如果不加模式,默认的是 r
处理完一个文件时候,要关闭文件
4.2 文件关闭
文件对象.close( )
下面看看例子
f = open('/root/userfolder/1.txt')
type(f)结果为
_io.TextIOWrapper查看文件类型,是个文本类型(text)
说明已经打开了文件
打开文件即将文件从外存(硬盘)读入内存,根据以前所学
一定有一个id号
id(f)结果为
139835160270384ok
接下来关闭文件:
f.close()如果我们打开一个不存在的文件
则系统默认的r模式会报错:
f = open('/root/userfolder/2.txt')结果为
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-38-ba3d87886db4> in <module>()
----> 1 f = open('/root/userfolder/2.txt')
FileNotFoundError: [Errno 2] No such file or directory: '/root/userfolder/2.txt'用w模式打开就行了
f = open('/root/userfolder/2.txt','w')你会发现,在目录下创建了一个2.txt文件
4.3 文件的写入
之前我们说了使用open()加上文件的绝对路径或者相对路径可以打开文件
这里我们讲一个更简单的方法
我们导入os模块,os模块是和操作系统相关的模块
os.chdir() 方法用于改变当前工作目录到指定的路径。
在/root/userfolder/目录下的1.txt文件中,写下“莫莫,你好”,并保存
4.3.1 read
我们使用read()方法可以读取文本内容
import os
os.chdir('/root/userfolder/')
f = open('1.txt',encoding='gbk')
f.read()用的ubuntu系统,编码形式变成了gbk,不加的话,read()读取中文会报错,window系统可以不加
结果为
'莫莫,你好'4.3.2 write
我们还可以使用write()方法写入内容:
f.write('莫莫,我爱你')结果为
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-57-0a3613f20217> in <module>()
----> 1 f.write('莫莫,我爱你')
UnsupportedOperation: not writable报错啦!默认的打开模式是 r (只读),所以不能写入.
先关掉文件
f.close()再来操作一遍,改下打开模式
import os
os.chdir('/root/userfolder/')
f = open('1.txt','a',encoding='gbk')
f.write('\n莫莫,我爱你')
f.close()读取一下
f = open('1.txt',encoding='gbk')
f.read()结果为
'莫莫,你好\n莫莫,我爱你'再次读取呢
f.read()结果为
''什么情况,发现读出来的内容为空!
解释一下,这里的read()方法相当于读取全部内容,如果读完内容,再次读取时候,书签已经在文章末尾,再次往后读当然没有内容啦~
如果我只想读取一行呢?
f.close()
f = open('1.txt',encoding='gbk')
f.readline()结果为
'莫莫,你好\n'读取第二行
f.readline()结果为
'莫莫,我爱你'读取第三行
f.readline()结果为
''以上的例子只有两行,如果多行的话,可以用循环进行读取
f.close()
f = open('1.txt',encoding='gbk')
if f.readline()!='':
print(f.readline())结果为
莫莫,我爱你恩哼?为什么只有第二句被读出来了
因为if中的判断已经执行了一次readline(),而在print()中的readline()执行读出的是第二句
我们换种写法
f.close()
f = open('1.txt',encoding='gbk')
for i in range(0,2):
print(f.readline())结果为
莫莫,你好
莫莫,我爱你问题又来了,我们知道有两行,那不知道有几行的情况呢?
可以用readlines()方法
f.close()
f = open('1.txt',encoding='gbk')
f.readlines()结果为
['莫莫,你好\n', '莫莫,我爱你']readlines()方法将每行内容作为列表元素,返回的是一个列表
看上去很不美观
加工一下
f.close()
f = open('1.txt',encoding='gbk')
for i in f.readlines():
print(i)结果为
莫莫,你好
莫莫,我爱你我们可以写成更有python风格的代码
f.close()
f = open('1.txt',encoding='gbk')
g = [print(i) for i in f.readlines()]结果为
莫莫,你好
莫莫,我爱你为什么要加个 g = 呢?
我们看看不加g = 的情况
f.close()
f = open('1.txt',encoding='gbk')
[print(i) for i in f.readlines()]结果为
莫莫,你好
莫莫,我爱你
[None, None]会返回列表,而这个列表的元素是None,因为print( ) 函数作为列表的元素是没返回值的
举个更简单的例子就好理解了
i = print('莫莫,我爱你')结果为
莫莫,我爱你打印一下i
print(i)结果为
None将print()赋值给 i
我们打印 i 发现是None
5 文件的遍历
import os
def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
print(root) #当前目录路径
print(dirs) #当前路径下所有子目录
print(files) #当前路径下所有非目录子文件