- 本文承接《 Lucene 实战前 核心理论简述》,介绍完 Lucene 理论之后,现在开始真正的进行编码开发。
Lucene 下载
- 开发前第一步先获取 Lucene 的开发包
-
Apache Lucene 官网地址:http://lucene.apache.org/
-
Lucene 官网全部版本下载地址:http://archive.apache.org/dist/lucene/java/



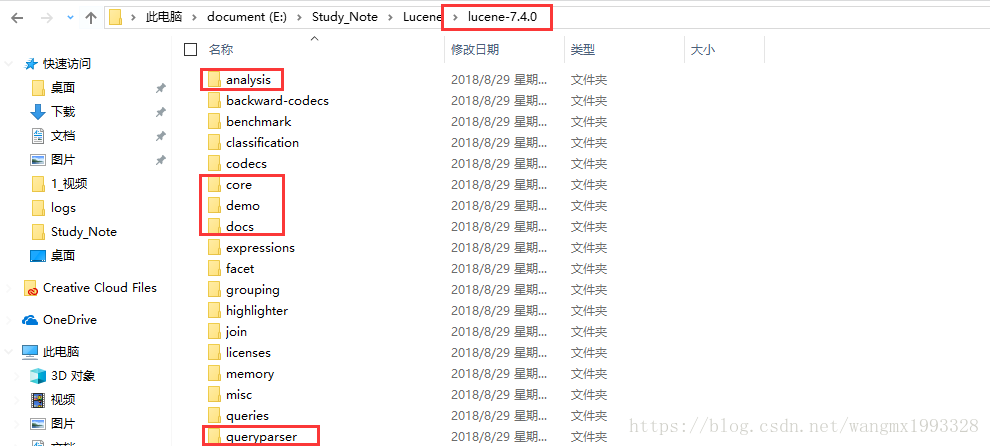
- 如下所示为下载后的解压的结构,Lucene 不同的功能包放在不同目录,开发中需要使用什么功能就导入什么包即可
- analysis:分词包,使用 Lucene 都通常会用到分词,因为无论是存储还是搜索,都需要进行分词
- core :其中为核心包,Lucene 开发必导
- demo:其中是官方示例,可以用来学习
- docs :其中是 API 文档
- queryparser:其中是查询所需的包,检索功能必导
- ...............
环境准备
- 为了思路清晰,本文将新建项目
- 不使用 Maven管理,也不用 Spring Boot 开发,直接使用 Java SE 项目进行学习 Lucene 的 API
- 本文例子使用 Lucene 7.4、Java JDK 1.8
新建项目
导入开发包
- commons-io-2.4.jar:本身 Lucene 不依赖它,是为了操作文件方便而导入的 Apache 的一个 Jar 包,使用可以参考《org.apache.commons.io.FileUtils 详解》
- lucene-7.4.0\analysis\common\lucene-analyzers-common-7.4.0.jar:标准分词包
- lucene-7.4.0\core\lucene-core-7.4.0.jar:lucene 核心包
- lucene-7.4.0\queryparser\lucene-queryparser-7.4.0.jar:查询解析包

待检索文件
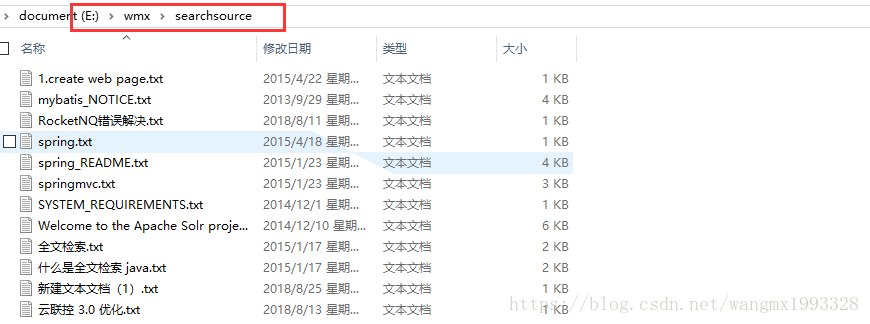
- 本文示例以下面的 "E:/wmx/searchsource" 目录下的文件进行操作,简要操作流程如下:
- 第一步:提取文件需要的部分,比如:文件名,文件内容,文件大小 等等
- 第二步:将提取的文件内容添加到 Lucene 索引库中,索引库相当于 Lucene 的数据库
- 第三步:从 Lucene 索引库中检索信息
- Lucene 索引库中存放索引与 Lucene 文档(Document),每一个 Lucene Document 对象对应提取的文件内容,具体含义请查看之后代码中的注释,只有多写才能更好的理解。
Lucene 操作
Lucene 创建索引
package com.lct.wmx.utils;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.File;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
/**
* Created by Administrator on 2018/8/29 0029.
* Lucene 索引管理工具类
*/
public class IndexManagerUtils {
/**
* 为指定目录下的文件创建索引,包括其下的所有子孙目录下的文件
*
* @param targetFileDir :需要创建索引的文件目录
* @param indexSaveDir :创建好的索引保存目录
* @throws IOException
*/
public static void indexCreate(File targetFileDir, File indexSaveDir) throws IOException {
/** 如果传入的路径不是目录或者目录不存在,则放弃*/
if (!targetFileDir.isDirectory() || !targetFileDir.exists()) {
return;
}
/** 创建 Lucene 文档列表,用于保存多个 Docuemnt*/
List<Document> docList = new ArrayList<Document>();
/**循环目标文件夹,取出文件
* 然后获取文件的需求内容,添加到 Lucene 文档(Document)中
* 此例会获取 文件名称、文件内容、文件大小
* */
for (File file : targetFileDir.listFiles()) {
if (file.isDirectory()) {
/**如果当前是目录,则进行方法回调*/
indexCreate(file, indexSaveDir);
} else {
/**如果当前是文件,则进行创建索引*/
/** 文件名称:如 abc.txt*/
String fileName = file.getName();
/**文件内容:org.apache.commons.io.FileUtils 操作文件更加方便
* readFileToString:直接读取整个文本文件内容*/
String fileContext = FileUtils.readFileToString(file);
/**文件大小:sizeOf,单位为字节*/
Long fileSize = FileUtils.sizeOf(file);
/**Lucene 文档对象(Document),文件系统中的一个文件就是一个 Docuemnt对象
* 一个 Lucene Docuemnt 对象可以存放多个 Field(域)
* Lucene Docuemnt 相当于 Mysql 数据库表的一行记录
* Docuemnt 中 Field 相当于 Mysql 数据库表的字段*/
Document luceneDocument = new Document();
/**
* TextField 继承于 org.apache.lucene.document.Field
* TextField(String name, String value, Store store)--文本域
* name:域名,相当于 Mysql 数据库表的字段名
* value:域值,相当于 Mysql 数据库表的字段值
* store:是否存储,yes 表存储,no 为不存储
*
* TextField:表示文本域、默认会分词、会创建索引、第三个参数 Store.YES 表示会存储
* 同理还有 StoredField、StringField、FeatureField、BinaryDocValuesField 等等
* 都来自于超级接口:org.apache.lucene.index.IndexableField
*/
TextField nameFiled = new TextField("fileName", fileName, Store.YES);
TextField contextFiled = new TextField("fileContext", fileContext, Store.YES);
/**如果是 Srore.NO,则不会存储,就意味着后期获取 fileSize 值的时候,值会为null
* 虽然 Srore.NO 不会存在域的值,但是 TextField本身会分词、会创建索引
* 所以后期仍然可以根据 fileSize 域进行检索:queryParser.parse("fileContext:" + queryWord);
* 只是获取 fileSize 存储的值为 null:document.get("fileSize"));
* 索引是索引,存储的 fileSize 内容是另一回事
* */
TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);
/**将所有的域都存入 Lucene 文档中*/
luceneDocument.add(nameFiled);
luceneDocument.add(contextFiled);
luceneDocument.add(sizeFiled);
/**将文档存入文档集合中,之后再同统一进行存储*/
docList.add(luceneDocument);
}
}
/** 创建分词器
* StandardAnalyzer:标准分词器,对英文分词效果很好,对中文是单字分词,即一个汉字作为一个词,所以对中文支持不足
* 市面上有很多好用的中文分词器,如 IKAnalyzer 就是其中一个
*/
Analyzer analyzer = new StandardAnalyzer();
/** 指定之后 创建好的 索引和 Lucene 文档存储的目录
* 如果目录不存在,则会自动创建*/
Path path = Paths.get(indexSaveDir.toURI());
/** FSDirectory:表示文件系统目录,即会存储在计算机本地磁盘,继承于
* org.apache.lucene.store.BaseDirectory
* 同理还有:org.apache.lucene.store.RAMDirectory:存储在内存中
*/
Directory directory = FSDirectory.open(path);
/** 创建 索引写配置对象,传入分词器*/
IndexWriterConfig config = new IndexWriterConfig(analyzer);
/**创建 索引写对象,用于正式写入索引和文档数据*/
IndexWriter indexWriter = new IndexWriter(directory, config);
/**将 Lucene 文档加入到 写索引 对象中*/
for (int i = 0; i < docList.size(); i++) {
indexWriter.addDocument(docList.get(i));
/**如果目标文档数量较多,可以分批次刷新一下*/
if ((i + 1) % 50 == 0) {
indexWriter.flush();
}
}
/**最后再 刷新流,然后提交、关闭流*/
indexWriter.flush();
indexWriter.commit();
indexWriter.close();
}
public static void main(String[] args) throws IOException {
File file1 = new File("E:\\wmx\\searchsource");
File file2 = new File("E:\\wmx\\luceneIndex");
indexCreate(file1, file2);
}
}- 程序运行之后,在 Lucene 索引库中就生成好了索引和文档,接着便可以来检索这些内容了,而不需要再从实际文件中进行查询。

Lucene 检索索引
package com.lct.wmx.utils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.File;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* Created by Administrator on 2018/8/29 0029.
* Lucene 索引搜索工具类
*/
public class IndexSearchUtils {
/**
* 索引查询
*
* @param indexDir :Lucene 索引文件所在目录
* @param queryWord :检索的内容,默认从文章内容进行查询
* @throws Exception
*/
public static void indexSearch(File indexDir, String queryWord) throws Exception {
if (indexDir == null || queryWord == null || "".equals(queryWord)) {
return;
}
/** 创建分词器
* 1)创建索引 与 查询索引 所用的分词器必须一致
*/
Analyzer analyzer = new StandardAnalyzer();
/**创建查询对象(QueryParser):QueryParser(String f, Analyzer a)
* 第一个参数:默认搜索域,与创建索引时的域名称必须相同
* 第二个参数:分词器
* 默认搜索域作用:
* 如果搜索语法parse(String query)中指定了域名,则从指定域中搜索
* 如果搜索语法parse(String query)中只指定了查询关键字,则从默认搜索域中进行搜索
*/
QueryParser queryParser = new QueryParser("fileName", analyzer);
/** parse 表示解析查询语法,查询语法为:"域名:搜索的关键字"
* parse("fileName:web"):则从fileName域中进行检索 web 字符串
* 如果为 parse("web"):则从默认搜索域 fileContext 中进行检索
* 1)查询不区分大小写
* 2)因为使用的是 StandardAnalyzer(标准分词器),所以对英文效果很好,如果此时检索中文,基本是行不通的
*/
Query query = queryParser.parse("fileContext:" + queryWord);
/** 与创建 索引 和 Lucene 文档 时一样,指定 索引和文档 的目录
* 即指定查询的索引库
*/
Path path = Paths.get(indexDir.toURI());
Directory dir = FSDirectory.open(path);
/*** 创建 索引库读 对象
* DirectoryReader 继承于org.apache.lucene.index.IndexReader
* */
DirectoryReader directoryReader = DirectoryReader.open(dir);
/** 根据 索引对象创建 索引搜索对象
**/
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
/**search(Query query, int n) 搜索
* 第一个参数:查询语句对象
* 第二个参数:指定查询最多返回多少条数据,此处则表示返回个数最多5条
*/
TopDocs topdocs = indexSearcher.search(query, 5);
System.out.println("查询结果总数:::=====" + topdocs.totalHits);
/**从搜索结果对象中获取结果集
* 如果没有查询到值,则 ScoreDoc[] 数组大小为 0
* */
ScoreDoc[] scoreDocs = topdocs.scoreDocs;
ScoreDoc loopScoreDoc = null;
for (int i = 0; i < scoreDocs.length; i++) {
System.out.println("=======================" + (i + 1) + "=====================================");
loopScoreDoc = scoreDocs[i];
/**获取 文档 id 值
* 这是 Lucene 存储时自动为每个文档分配的值,相当于 Mysql 的主键 id
* */
int docID = loopScoreDoc.doc;
/**通过文档ID从硬盘中读取出对应的文档*/
Document document = directoryReader.document(docID);
/**get方法 获取对应域名的值
* 如域名 key 值不存在,返回 null*/
System.out.println("doc id:" + docID);
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
/**防止内容太多影响阅读,只取前20个字*/
System.out.println("fileContext:" + document.get("fileContext").substring(0, 20) + "......");
}
}
public static void main(String[] args) throws Exception {
File indexDir = new File("E:\\wmx\\luceneIndex");
indexSearch(indexDir, "spring");
}
}- 控制台输出如下:
查询结果总数:::=====4
=======================1=====================================
doc id:2
fileName:spring_README.txt
fileSize:3255
fileContext:## Spring Framework
......
=======================2=====================================
doc id:1
fileName:springmvc.txt
fileSize:2126
fileContext:Spring2. Web......
=======================3=====================================
doc id:0
fileName:spring.txt
fileSize:83
fileContext:The Spring Framework......
=======================4=====================================
doc id:4
fileName:1.create web page.txt
fileSize:47
fileContext:Learn how to create ......Process finished with exit code 0
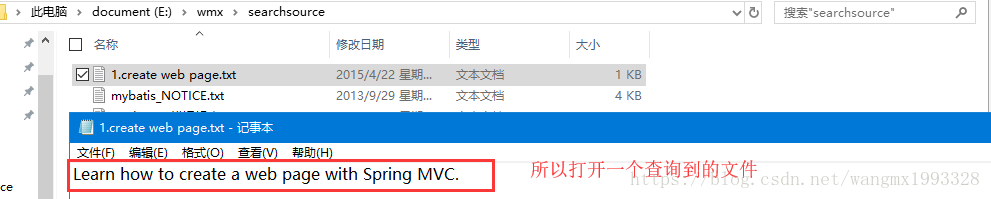
- 关于里面 Field 域类型不清楚的,可以参考《 Lucene 实战前 核心理论简述》中的“Luncene 域详解”部分。