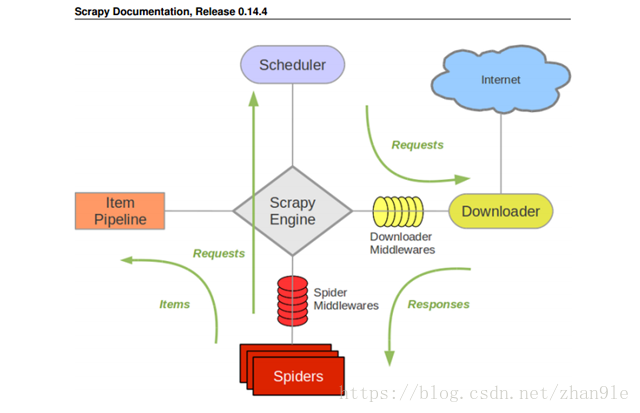
Scrapy architecture(体系结构)
组件:
Scrapy Engine:
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
调度器(Scheduler)
调度器从引擎接受 request 并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给Spider。
Spiders
Spiders 是 Scrpy 用户填写用于分析 response 并提取 item(即获取到item)或额外跟进的url 类。每个 Spider 负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline 负责处理被 Spider 提取出来的 Item。典型的处理有清理、验证及持久化(例如存储到数据库中)
下载器中间件(Downloader middlewares)
下载器中间件是引擎及下载器之间的特定钩子(Specific hook),处理Downloader 传递给引擎的 response。其提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy 功能。
Spider中间件(Spider middlewares)
Spider 中间件是引擎及 Spider 之间的特定钩子(Specific hook),处理Spider的输入(response)和输出(item及requests)。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
一、数据流程
-
Scrapy 初始的内容时添加在 Spiders 内部的,它初始的 url 的获取通过两种方式: ① start_urls ② 函数 start_request( )
- Spiders 会将 url 传递到 Scheduler 中,Scheduler 是一个存储 url(Request)的队列。
- Scheduler 中的 url,会获取这些 url 放到 Downloader 中去下载页面。settings中的“CONCURRENT_REQUESTS”就是设置从 Downloader 中同时下载页面的最大值。
- Downloader 在下载之前会经过 Downloader Middlewares,可以在这里添加( headers,代理)。
- Downloader 在下载结束后,会将下载后的 response 返回给 Spiders。
- Spiders 在获取到 response 之后,会解析这个response,获取需要的信息并生成 Items,yield item。
- 在 Spiders 获取到 response 之后,还有可能生成新的 url ,就再次执行“第2步”。
- Item 会被传递到 Item Pipeline 中, Item Pipeline 会执行后续的操作(可存储、展示、其他)
二、各部分的作用及输入输出
1.Spiders:
作用:
① url生成的地方
② 返回值解析的地方
③ item生成的地方
输入:
① start_urls, start_request
② response -> Downloader传递过来的
输出:
① request
② item
2.Scheduler:
作用:
① 存储Request的地方
输入:
① url (request) 传递给Scheduler的输入模块:Spiders,Pipeline,Downloader
输出:
① url (request) Scheduler传递输出的模块:Downloader
3.Downloader:
作用:
① 接收 Request 并下载这个Request
② 将 response 返回传递给Spiders
输入:
① Request -> 来自Scheduler
输出:
① response -> 接收方为:Spiders
② request -> 接收方为:Scheduler
4.Item Pipeline:
作用:
① 获取Items 并将Items(存储,展示,其他)
输入:
① Item -> 由Spider生成
输出:
① image 的 Request 传给 Scheduler
② 数据库,文件接收
5.Downloader Middlewares:
① 当Scheduler 的 request经过时,此时还未下载页面,我们可以对 Request 进行修改,Process_request
② 当 Downloser 下载页面结束时,也经过,可根据response内容做处理Process_request。
③ 当下载的过程中出现了异常,也会经过Downloader Middlewares,process_exception。
6.Spiders Middlewares:
①当 Request 从 Spiders 传递给 Scheduler的时候,会经过 Spiders Middlewares,可以做的操作是过滤Request,去重等。
② 当 Downloader 返回 response时,也能经过 Spiders Middlewares,可以做的操作时返回值的过滤。