静态查找、动态查找
顺序查找
又叫线性查找。就是按顺序一个一个找。
/*a为数组,n为数组个数,key为要查找的关键字*/
int Sequential_Search(int *a,int n, int key)
{
int i;
for(i=1;i<=n;i++)
{
if(a[i]=key)
return i;
}
return 0;
}
/*优化,设置一个哨兵,不用每次都比较i与n,在查找最后设置一个哨兵*/
int Sequential_Search(int *a,int n,int key)
{
int i;
a[0]=key;
i=n;
while(a[i]!=key)
{
i--;
}
return i;
}有序表查找
折半查找
int Binary_Search(int a*,int n,int key)
{
int low,int high,int i;
low=1;
high=n;
while(n)
{
n=int(n/2);
if(a[n]=key)
return n;
else if(a[n]<key)
}
}斐波那契查找:
斐波那契数列:从第三个数开始,f(n)=f(n-1)+f(n-2)。
指针实现:
/*
推演到一般情况,假设有待查找数组array[n]和斐波那契数组F[k],并且n满足n>=F[k]-1&&n < F[k+1]-1,则它的第一个拆分点middle=F[k]-1
*/
#include <iostream>
#include <cassert>
//斐波那契额数组
long long Fib(long long n)
{
assert (n>0); //n必须大于0
if(n==0||n==1)
{
return n;
}
return Fib(n-1)+Fib(n-2);
}
int Fibonacci_Search(int *a, int key,int n)
{
int i,low=0,high=n-1;
int mid=0;
int k=0;
int F[MAX];
Fib(F);
while(n>F[k]-1)
++k;
for(i=n;i<F[k]-1;++i)
a[i]=a[high];
while(low<=high)
{
mid=low+F[k-1]-1;
if(a[mid]>key)
{
high=mid-1;
k=k-1;
}
else is(a[mid]<key)
{
low=mid+1;
k=k-2;
}
else
{
if(mid<=high)
return mid;
else
return -1;
}
}
return 0;
}
int main()
{
int a[MAXN] = {5,15,19,20,25,31,38,41,45,49,52,55,57};
int k, res = 0;
printf("请输入要查找的数字:\n");
scanf("%d", &k);
res = Fibonacci_Search(a,k,13);
if(res != -1)
printf("在数组的第%d个位置找到元素:%d\n", res + 1, k);
else
printf("未在数组中找到元素:%d\n",k);
return 0;
}8.5线性索引查找
就是将索引集合组织为线性集合,即索引表。包括三种:稠密索引、分块索引和倒排索引。
稠密:每个数据u索引对应一个索引项,按照关键码有序排列,相当于一个有序的字典。
分块:把数据集记录分成若干块,快内无需,快间有序。
分块索引:每块对应一个索引。存储三个数据项:1.最大关键字2.个数3.首数据元素的指针。 查找时,块间有序,查到对应的
块,快内无序,在顺序查找。最佳的是分的块数和块内元素的个数相同。
倒排索引:包括次关键码(字段或属性)和记录号表。不是由记录确定属性,而是由属性确定位置。
8.6二叉树排序
为了便于插入和删除。动态查找表。左子树比根节点小,右子树比根节点大。
/*定义一个二叉链表节点*/
typedef struct BiTNode
{
int data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;查找:
/*递归查找二叉排序树T中是否存在key*/
/*指针f指向T的双亲,其初始调用值为NULL*/
/*若查找成功,则指针P指向该数据元素结点,并返回TRUE*/
/*否则返回false*/
Status SearchBST(BiTNode T,int key,BiTree f,BiTree *P)
/*(T,93,NULL,p)T是二叉链表,f指向T的双亲,当T指向根节点时,f就是NULL,p查找成功后得到的结点的位置*/
{
if(!T)
{
*p=f;
return FALSE;
}
else if(key==T->data)
{
*p=T;
return TRUE;
}
else if(key<T->data)
return SearchBST(T->lchild,key,T,*p)
else
return SearchBST(T->rchild,key,T,*p)
}这里有个c语言结构体指针http://blog.51cto.com/zoufuxing/985799
插入操作:没有的话,插入key并返回true
Status InsertBST(BiTree *T,int key)
{
BiTree p,s;
if(!SearchBST(*T,key,NULL,&p)) //P会留在查找痕迹的最后一个位置
{
s=(BiTree)malloc(BiTNode);
s->data=key;
s->lchild=s->rchild=NULL;
if(!p)
*T=s;
else if(key<p->data)
p->lchild=s;
else
p->rchild=s;
return TRUE;
}
else
return FALSE;
}所以构造二叉排序树则是
int i;
int a[10]={62,88,45,66,29,44,78,68,77,82,56}
BiTree T=NULL;
for(i=0;i<10;i++)
{
InsertBST(&T,a[i])
}删除:
删除的三种结点:1.叶子结点2.仅有左或右子树的节点3.左右子树都有的节点。
status DeleteBST(BiTree *T,int key)
{
if(!*T)
return FALSE;
else
{
if (key==(*T)->data)
return Delete(T);
else if (key<(*T)->data)
return DeleteBST(&(*T)->lchild,key)
else
return DeleteBST(&(*T)->rchild,key)
}
}
status Delete(BiTree p)
{
BiTree q,s;
if((*p)->rchild==NULL)
{
q=*p;*p=(*p)->lchild;free(q);
}
else if((*p)->lchild==NULL)
{
q=*p;*p=(*p)->rchild;free(q);
}
else
{
q=*p;s=(*p)->lchild;
while(s->rchild)
{
q=s;s=s->rchild;
}
(*p)->data=s->data;
if(q!=*p)
q->rchild=s->lchild;
else
q->lchild=s->lchild;
free(s);
}
return TRUE;
}8.7平衡二叉树AVL树
左子树和右子树深度之差不超过1.
可以避免二叉排序树其中一孩子的深度过大,两边不平衡。
/*重新定义二叉树的节点,多存储一个平衡因子*/
/*左子树大于右子树深度值为正,右子树大为负,一样大为0*/
typedef struct _BitNode
{
int data;
int bf;
}太多了。不想看这个了,需要的时候再看。
红黑树:
根结点是黑色。
每个叶子节点是黑色(NULL)。
如果一个节点是红色,则他的子节点都是黑色。所以不能有两个连续的红。
从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。O(lgn)
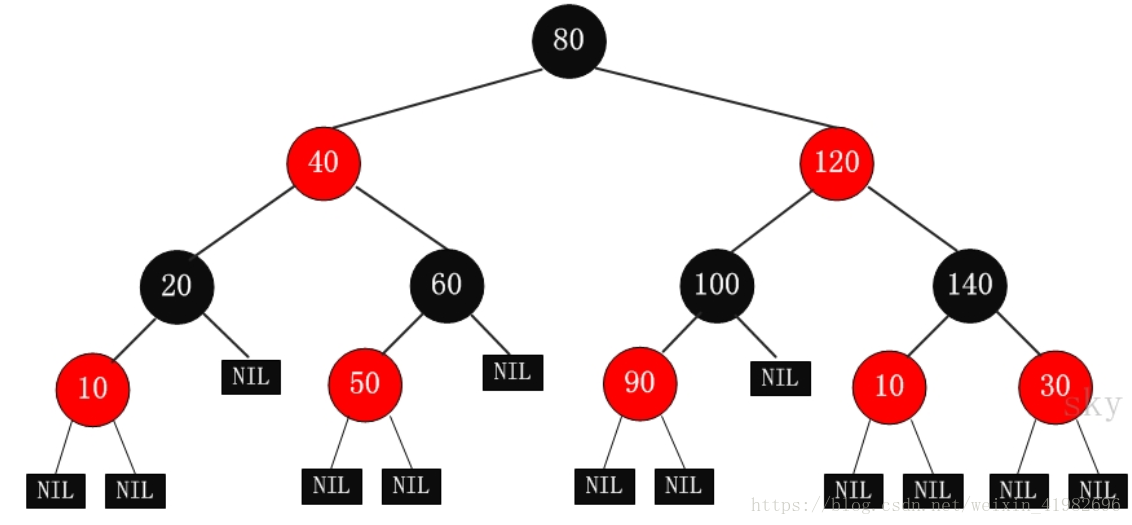
左旋转:
父节点被右孩子取代,自己成为左孩子,原来右孩子的左孩子成为原来父节点的右孩子。
右旋转:
父节点被左孩子取代,自己成为右孩子,原来左孩子的右孩子成为原来父节点的左孩子。
8.8 B-树:多路查找树
每一个节点有多个孩子,每个节点存储多个元素。包括2-3,2-3-4,B和B+树
8.9散列表(哈希表)
1.在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
2.当查找记录时,我们通过同样的散列函数计算记录的散列地址访问该记录。
最适合求解问题与给定值相等的记录,不适用与范围查找。关键是散列函数的的设计。
构造散列函数:
1.计算简单2.散列地址分布均匀
直接地址法:线性函数。f(key)=a key+b
数字分析法:抽取一部分
平方取中法:
折叠法:
除留余数法:f(key)=key mop p (p<=m)
mod是取模、求余数的意思。
随机数法:f(key)=random(key)
处理散列冲突:
开放定址法:一旦发生冲突,就去寻找下一个空的散列地址,只要散列表足够大,总能找到空的散列。
存放记录的数组叫做散列表。
哈希表:把key通过一个哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当做数组的下标。