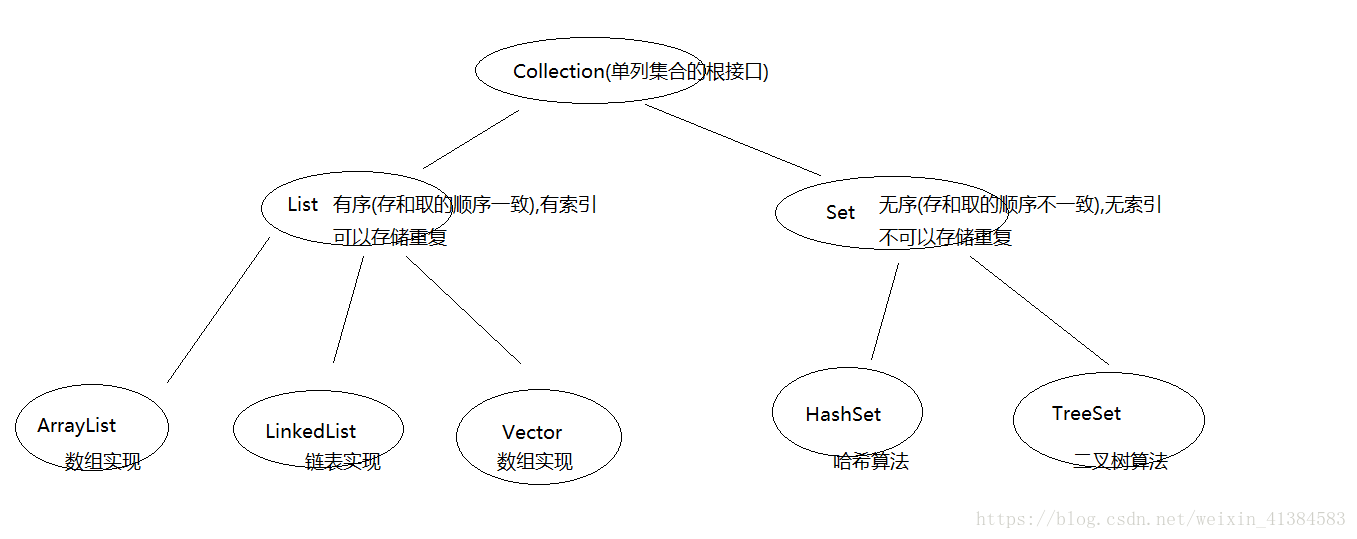
集合框架(集合的由来及集合继承体系图)
- A:集合的由来
- 数组长度是固定,当添加的元素超过了数组的长度时需要对数组重新定义,太麻烦,java内部给我们提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少
- B:数组和集合的区别
- 区别1 :
- 数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值
- 集合只能存储引用数据类型(对象)集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象
- 区别2:
- 数组长度是固定的,不能自动增长
- 集合的长度的是可变的,可以根据元素的增加而增长
- 区别1 :
- C:数组和集合什么时候用
* 1,如果元素个数是固定的推荐用数组
* 2,如果元素个数不是固定的推荐用集合
其中,对于List集合:
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
Vector和ArrayList的区别
Vector是线程安全的,效率低
ArrayList是线程不安全的,效率高
共同点:都是数组实现的
ArrayList和LinkedList的区别
ArrayList底层是数组结果,查询和修改快
LinkedList底层是链表结构的,增和删比较快,查询和修改比较慢
共同点:都是线程不安全的
其中Set集合中的hashSet集合:
Set集合,无索引,不可以重复,无序(存取不一致)
* HashSet集合去除重复,依赖的是底层的HashCode方法和equals方法,默认的HashCode方法表示的每个对象的地址值是不同的,所以在比添加元素的时候,系统会因为各个对象的默认HashCode值不同,而认为不是同一元素,所以都添加进去了.根本就没有走equals方法,没有进行内容判断,所以添加了重复元素...所以,我们需要对Hash和equals进行重写,使得,相同元素的HashCode值一定相同,但是,这样重写之后,有可能会出现不同元素的HashCode值可能相同的情况,这样,可能会被误判断是同一元素,所以,针对这种HashCode值相等的情况需要再次走equals方法进行判断, 判断内容是不是相同,相同就是同一元素,不添加.要是不相同,就不是同一种元素,就得添加
*
* 总结如下:
* 第一步:看HashCode值是否相同,
* 不同:就是不同元素,添加
* 相同:就走equals方法进行判断
* equals相等,是同一元素,不添加
* equals不相等,不是同一元素,添加
HashCode 和equals方法只应用于HashSet和LinkHashSet以及HashMap和LinkedHashMap集合,
2.将自定义类的对象存入HashSet去重复
* 类中必须重写hashCode()和equals()方法
* hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
* equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
3. LinkedHashSet的特点
* 底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象
* 因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样
其中Set集合中的TreeSet集合:
- 1.特点
- TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
- 2.使用方式
- a.自然顺序(Comparable)
- TreeSet类的add()方法中会把存入的对象提升为Comparable类型
- 调用对象的compareTo()方法和集合中的对象比较
- 根据compareTo()方法返回的结果进行存储
- b.比较器顺序(Comparator)
- 创建TreeSet的时候可以制定 一个Comparator
- 如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
- add()方法内部会自动调用Comparator接口中compare()方法排序
- 调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
- c.两种方式的区别
- TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
- TreeSet如果传入Comparator, 就优先按照Comparator
- a.自然顺序(Comparable)
自然排序原理图:

比较器排序原理图:
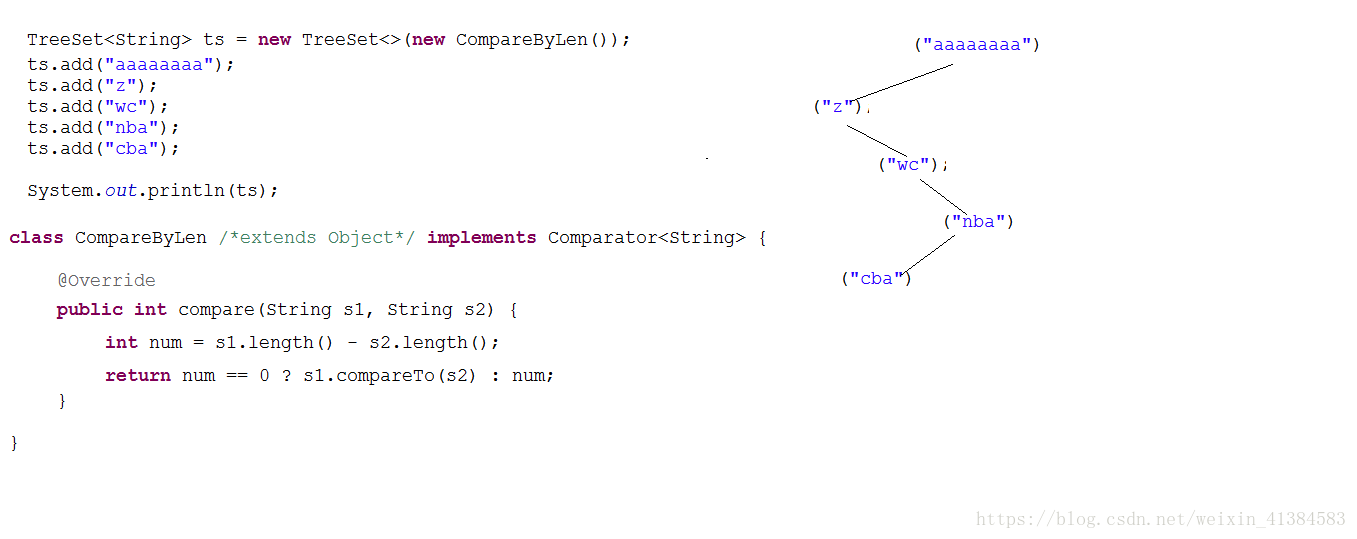
TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一
* 8种基本包装类和String类,源文件都是实现了comparable接口,而且重写了
* compareTo方法,默认按照字典顺序排序
* 当compareTo方法返回0的时候集合中只有一个元素(唯一性)
* 当compareTo方法返回正数的时候集合会怎么存就怎么取(升序)
* 当compareTo方法返回负数的时候集合会倒序存储(降序)