写在前面
本节是Python入门篇的最后一篇了,通过本节我们将会熟悉Python模块、包的使用,同时了解和养成书写Pythonic代码的习惯。主要内容如下图所示:
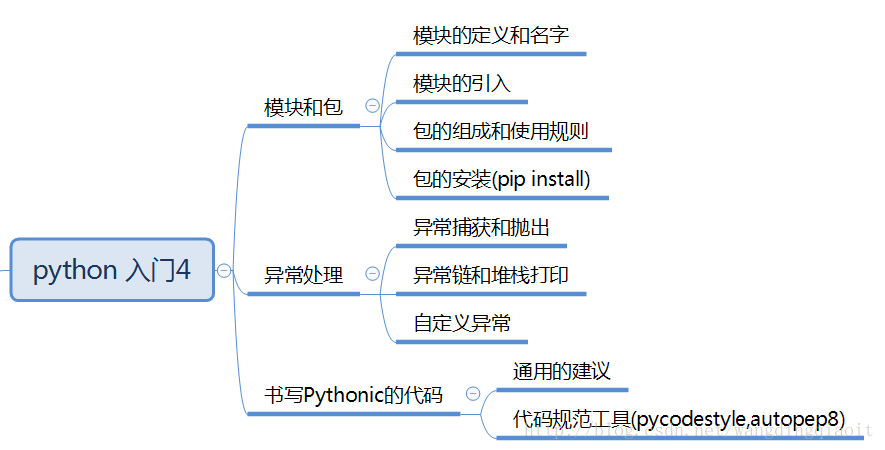
模块和包
1) 模块的定义和名字
在Python中一个脚本(Script)是一个将要被当做主模块(main)执行的python文件。模块(Module)是一个以.py结尾的python文件,在文件中我们定义了函数、类,准备以后重用这些代码块。Python中模块的名字,就是以.py为后缀的文件的文件名,例如fibo.py,那么模块名就是fibo。__name__变量保存了引用的模块的名字,当模块被当做主模块执行时,则__name__等于__main__。
例如我们创建一个斐波拉契数列的模块fibo.py如下:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while b < n:
print b,
a, b = b, a+b
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a+b
return result
if __name__ == "__main__":
test_num = 100
print('fibo unit testing for uuper value= %d' % test_num)
fib(test_num)
print('\ntest end.')然后在另一个文件fiboTest.py中引入这个模块(import module):
import fibo
import sys
print(__name__)
print(fibo.__name__)
print(sys.__name__)当我们执行上面的脚本将会输出:
>python fiboTest.py
__main__
fibo
sys执行完上述脚本后,我们会在当前目录下看到解释器为我们生成了一个
fibo.pyc文件,这是Python为模块生成的字节码文件,可以由Python虚拟机执行。pyc文件里面保存有fibo.py这个模块的时间戳,Python负责利用这个时间戳同步模块。
“__main__“这个特殊的名字主要用来区分是否当前正在执行的脚本。如果一个模块定义了输出的函数和类,但同时包含了单元测试的代码时,则需要像上面fibo.py中那样用__name__做判断,这样当这个模块被其他模块引用时,则__name__等于这个模块名字,单元测试代码不会被执行;当直接运行这个脚本时,__name__等于”__main__“则运行单元测试代码(参考自SO)。
2)模块的引入
在一个模块中引入已经定义好的函数或者类,这种方式称之为引入(importing),是一种很好的代码复用机制。Python中有多种代码引入方式:
import fibo # 引入整个模块 使用fibo.fib(100)
import fibo as fiboNumber # 重命名 fiboNumber.fib(100)
from fibo import * # 引入所有名字 引入后直接使用fib(100)
from fibo import fib2 # 引入指定名字 引入后直接使用fib2(100)
# 引入后可以这样使用
fibo.fib(100)
fiboNumber.fib(100)
fib(100)
print(fib2(200))一般尽量避免from fibo import *这种形式的引入,因为如果模块过大容易引入不必要内容,可能产生命名空间相关的错误。
在引入时,如果找不到对应的模块则会产生错误:
ImportError: No module named names在Python中,模块引入时搜索路径顺序为:首先搜索同名的内置模块( built-in module ),没找到时则搜索sys.path中包含的路径。sys.path路径内容不同系统略有差别,例如Windows下为:
import sys
print(sys.path)输出内容为:
>python path.py
['E:\\ds', 'C:\\WINDOWS\\SYSTEM32\\python27.zip', 'C:\\Python27\\DLLs', 'C:\\Python27\\lib', 'C:\\Python27\\lib\\plat-win', 'C:\\Python27\\lib\\lib-tk', 'C:\\Python27', 'C:\\Python27\\lib\\site-packages']在上面输出的路径中,第一个就是当前运行脚本所在的路径。
可以通过往sys.path中添加自定义模块的搜索路径。
在引入模块的时候,我们可以使用下面这三个函数,来查看命名空间中的名字情况。
- dir dir(moduleName)函数用于获取moduleName模块中定义的名字,当不传递参数时,返回当前模块定义的名字。
- globals 函数用于获取当前模块的全局空间中的名字,如果在函数内部调用则返回这个函数定义所在的模块的全局空间名字,而不是这个函数被调用的模块的全局空间名字。
- locals 返回局部空间的名字
下面使用这三个函数。
>>> import fibo,sys
>>> dir(fibo)
['__builtins__', '__doc__', '__file__', '__name__', '__package__', 'fib', 'fib2']
>>> dir()
['__builtins__', '__doc__', '__name__', '__package__', 'fibo', 'sys']
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_getframe', '_mercurial', 'api_version', 'argv', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_clear', 'exc_info', 'exc_type', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'gettrace', 'getwindowsversion', 'hexversion', 'long_info', 'maxint', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'ps2', 'py3kwarning', 'setcheckinterval', 'setprofile', 'setrecursionlimit', 'settrace', 'stderr', 'stdin', 'stdout', 'subversion', 'version', 'version_info', 'warnoptions', 'winver']
>>> locals()
{'__builtins__': <module '__builtin__' (built-in)>, '__package__': None, 'sys': <module 'sys' (built-in)>, 'fibo': <module 'fibo' from 'fibo.pyc'>, '__name__': '__main__', '__doc__': None}
>>> globals()
{'__builtins__': <module '__builtin__' (built-in)>, '__package__': None, 'sys': <module 'sys' (built-in)>, 'fibo': <module 'fibo' from 'fibo.pyc'>, '__name__': '__main__', '__doc__': None}
>>> _version = 1.0
>>> def show_version():
... localV="beta"
... print(locals()) # 函数内部使用locals
... print(globals()) # 函数内部使用globals
...
>>> show_version()
{'localV': 'beta'}
{'show_version': <function show_version at 0x01DBF730>, '__builtins__': <module '__builtin__' (built-in)>, '_version': 1.0, '__package__': None, 'sys': <module 'sys' (built-in)>, 'fibo': <module 'fibo' from 'fibo.pyc'>, '__name__': '__main__', '__doc__': None}3)包的组成和使用规则
包(packages)是由一组有着共同目的的模块组成的单元,例如一个处理音频的程序,可能包含的包如下:
sound/ Top-level package 顶层包
__init__.py Initialize the sound package # 包的标志文件
formats/ Subpackage for file format conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...在上面结构中__init__.py文件是Python中用来标志一个文件目录是包(Python3.3以后不需要这个文件了)。
例如我们新建一个目录fibLib,里面放入我们的fibo.py,然后在fiblib同级目录下新建一个packTest.py如下:
from fibolib.fibo import fib
fib(1000)执行程序将会输出:
Traceback (most recent call last):
File "packTest.py", line 1, in <module>
from fibolib.fibo import fib
ImportError: No module named fibolib.fibo这是因为在Python2.x下面需要加入__init__.py文件,这里我们新建一个空的__init__.py文件,重新执行程序则输出:
>python packTest.py
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987__init__.py文件也可以加入其它包相关的代码,这里不再详述。
4)包的安装
可以使用Python自带的包管理工具pip,这是包管理程序,
Windows下在Python安装目录的,例如C:\Python27\Scripts下能找到这个程序。
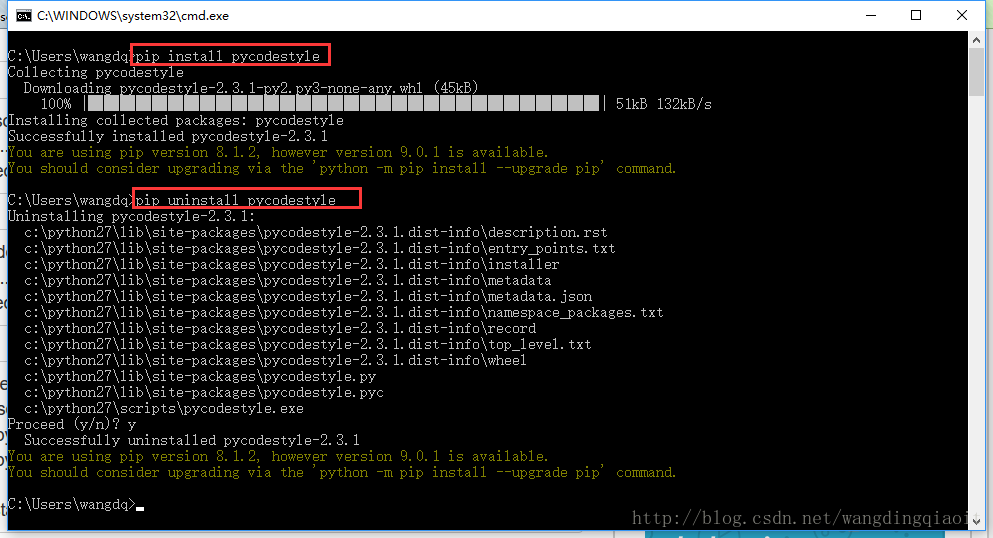
使用pip我们可以安装、卸载和升级第三方包,例如这里我们安装和卸载一个Python 编码风格拼写检查的库pycodestyle,如下图所示:
异常处理
在程序出错的情况下可以使用异常来捕获和处理。
1)异常捕获和抛出
这里通过一个除零异常来说明异常的捕获。
# zerodivision.py
def input_numbers():
a = float(input("Enter first number:"))
b = float(input("Enter second number:"))
return a, b
x, y = input_numbers() # 输入数字
while True:
try:
print("{0} / {1} is {2}".format(x, y, x/y))
break
except ZeroDivisionError: # 捕获除0异常
print("Cannot divide by zero")
x, y = input_numbers()Python使用try…except这样的结构来捕获和处理异常。
上面的脚本运行时输出:
>python zerodivision.py
Enter first number:5
Enter second number:0
Cannot divide by zero
Enter first number:10
Enter second number:2
10.0 / 2.0 is 5.0完整的异常处理还包括一个始终执行的部分,finally。
例如进行文件操作,无论是否发生异常我们总是关闭文件:
# cleanup.py
f = None
try:
f = open('data.txt', 'r')
contents = f.readlines()
for line in contents:
print(line.rstrip())
except IOError:
print('Error opening file')
finally: # 无论异常发生与否 总是执行
if f:
f.close()有时候我们虽然捕获了异常,但不能真正地处理这个异常,例如只是为了对异常进行日志记录时。
这个时候我们可以把异常继续抛出,交给上层逻辑处理:
logger = logging.getLogger(__name__)
try:
do_something_in_app_that_breaks_easily()
except AppError as error:
logger.error(error) # 为了日志记录
raise # just this! 这样就行了 能够再次抛出异常
# raise AppError # Don't do this, you'll lose the stack trace! 不要抛出这个指定异常raise在抛出异常时,可以给异常带上参数,例如:
raise ValueError('A very specific bad thing happened', 'foo', 'bar', 'baz') 2)异常链和堆栈打印
异常是具有继承关系的层次结构的,下面列出部分继承关系:
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StandardError
| +-- BufferError
| +-- ArithmeticError
| +-- AssertionError
| +-- AttributeError
| +-- EnvironmentError
| | +-- IOError
| | +-- OSError
| +-- ImportError
| +-- LookupError
| | +-- IndexError
| | +-- KeyError
| +-- RuntimeError
| | +-- NotImplementedError
| +-- SyntaxError
| +-- SystemError
| +-- TypeError
| +-- ValueError
+-- Warning
+-- DeprecationWarning
+-- SyntaxWarning可以借助 getclasstree()函数来打印它们之间的继承关系。
我们在捕获异常的时候,尽量捕获最具体的异常,
也就是最明确表达了你异常信息的那个具体类,而不是它的父类。
抛出具体的异常:
raise ValueError('A very specific bad thing happened')要比抛出这种:
raise Exception('I know Python!') # don't, if you catch, likely to hide bugs.更合适。
在抛出异常时,我们可以使用traceback模块的方法,像解释器一样打印出异常的堆栈,例如:
# stacktrace_ex.py
import traceback
def myfun():
def myfun2():
try:
3 / 0
except ZeroDivisionError as e:
print(e)
print("Class:", e.__class__)
for line in traceback.format_stack():
print(line.strip())
myfun2()
def test():
myfun()
test() 执行时输出:
>python stacktrace_ex.py
integer division or modulo by zero
('Class:', <type 'exceptions.ZeroDivisionError'>)
File "stacktrace_ex.py", line 28, in <module>
test()
File "stacktrace_ex.py", line 26, in test
myfun()
File "stacktrace_ex.py", line 22, in myfun
myfun2()
File "stacktrace_ex.py", line 19, in myfun2
for line in traceback.format_stack():3) 自定义异常
Python也支持自定义异常,自定义的异常需要继承自Exception类,例如:
# user_defined.py
class BFoundEx(Exception):
def __init__(self, value):
self.par = value
def __str__(self):
return "BFoundEx: b character found at position {0}".format(self.par)
string = "There are beautiful trees in the forest."
pos = 0
for i in string:
try:
if i == 'b':
raise BFoundEx(pos)
pos = pos + 1
except BFoundEx as e:
print(e)执行输出:
>python user_defined.py
BFoundEx: b character found at position 10对于异常的使用,也有一定的原则,具体可以参考SO。
书写Pythonic的代码
1)代码书写建议
遵从语言习惯书写出来的代码,通常简洁、可阅读性强,不仅方便自己,而且也方便以后维护。
书写Python代码的时候,也有一定的风格指导,例如一个过滤列表中大于4的元素的例子:
# Filter elements greater than 4
a = [3, 4, 5]
b = []
for i in a:
if i > 4:
b.append(i)上面的风格和下面对比:
a = [3, 4, 5]
b = [i for i in a if i > 4] # 使用comprehension
# 或者:
b = filter(lambda x: x > 4, a) # 使用内置函数filter显然第二种方式更清晰,简洁。
例如对列表中每个元素进行增加3的操作:
a = [3, 4, 5]
for i in range(len(a)):
a[i] += 3和下面的代码比较:
a = [3, 4, 5]
a = [i + 3 for i in a]
# Or:
a = map(lambda i: i + 3, a)显然第二种方式更简洁。
还有更多的例子和完整的风格建议,可以参考Code Style。
2)代码风格检查工具
可以安装pycodestyle、autopep8这类代码风格检查工具,例如上面的fibo.py,使用pycodestyle工具检查时发现问题如下:
>pycodestyle fibo.py
fibo.py:3:1: E302 expected 2 blank lines, found 1
fibo.py:9:1: E302 expected 2 blank lines, found 1
fibo.py:15:18: W292 no newline at end of file