版权声明:@Author 犯罪嫌疑人卢某 洒家辛苦总结 希望尊重洒家的劳动哟 https://blog.csdn.net/unscdf117/article/details/78724901
两个ArrayList中有大量的数据(比如千万条),直接合并的话对内存的占用是很大的,毕竟ArrayList的底层是操作数组,合并需要创建一个更大的数据来保存之前的两个ArrayList.
此时有一个场景,需要把两个千万级的ArrayList进行合并并且去除之中的重复元素.下意识情况下也许会想到使用Set集合进行去重,然而这样会造成大量的内存浪费,也会造成CPU的大量占用.
ArrayList中去重使用retainAll(),方法内调用batchRemove(),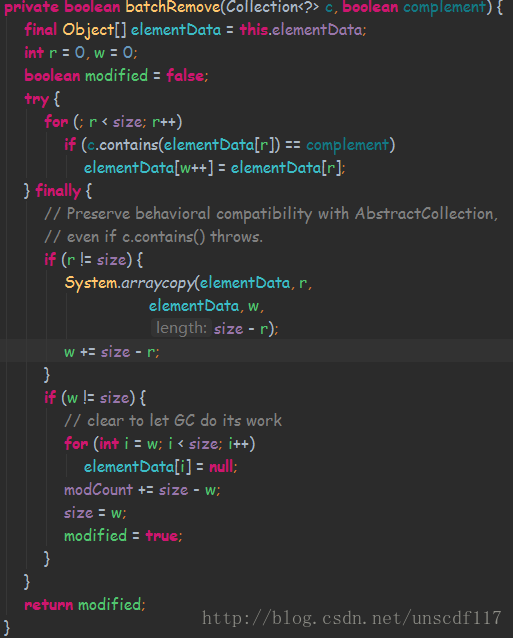
这里也使用到了数组复制,所以必然占据内存.
别的方法我也想不到,但是虚拟机堆内存大小是比较小的,使用SQL的Group By和distinct进行去重,但是这个方案会受制于磁盘阵列的搭建方式,比如Raid1的效率远远不如Raid0,如果是分布式项目还会存在链路层的限制.
目前没有好的方案,集合对象可以存在泛型,直接使用泛型集合进行去重.
List中的元素实现IEquatable接口,并且提供GetHashCode()和Equals()方法,然后集合对象.distinct().ToList();
代码如下