第2章 单变量线性回归linear regression with one variable
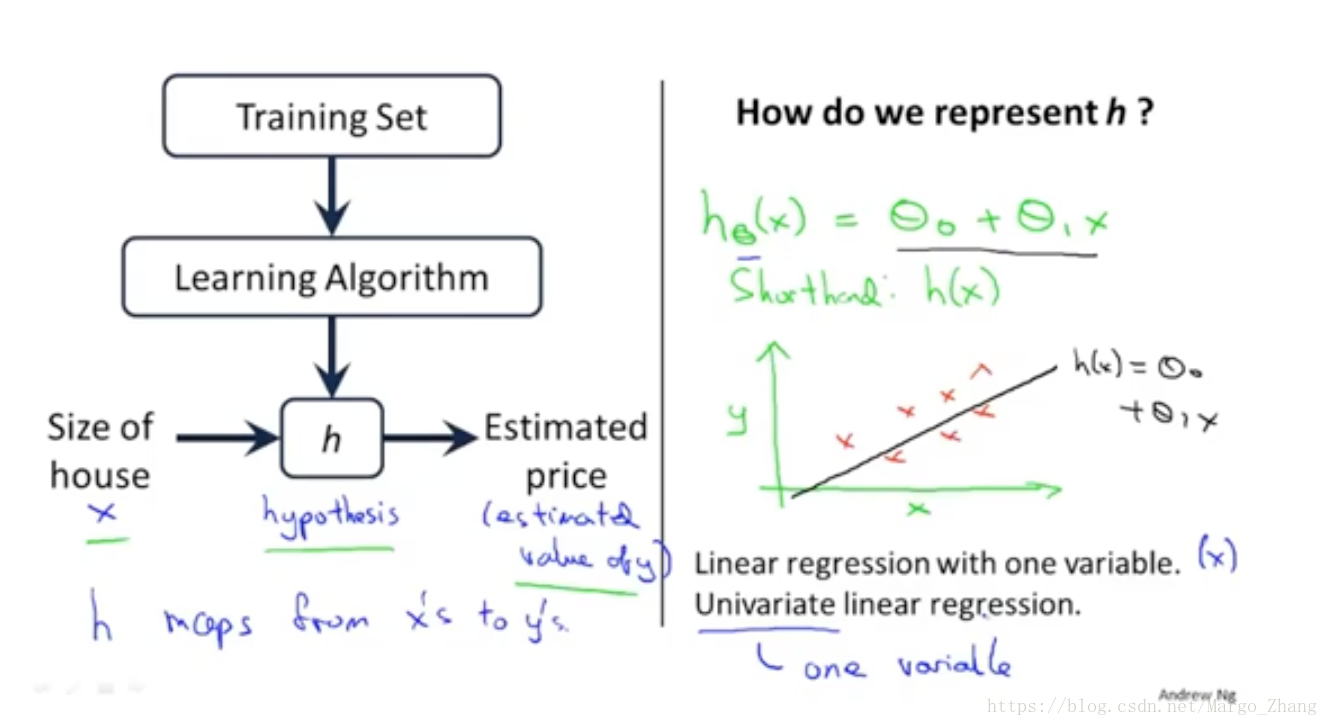
1,模型描述 model representation
Supervised learning (given the 'right answer' for each example in the data):
regression problems(predict real-valued output)连续实数
classification problems(discrete-valued output)离散量
训练样本的表征

学习算法h的表征
以下是univariate linear regression 单变量线性回归
2,代价函数Cost function
如何把最有可能的直线与数据相拟合,平方误差代价函数,squared error cost function

3,代价函数(一)cost function intuition
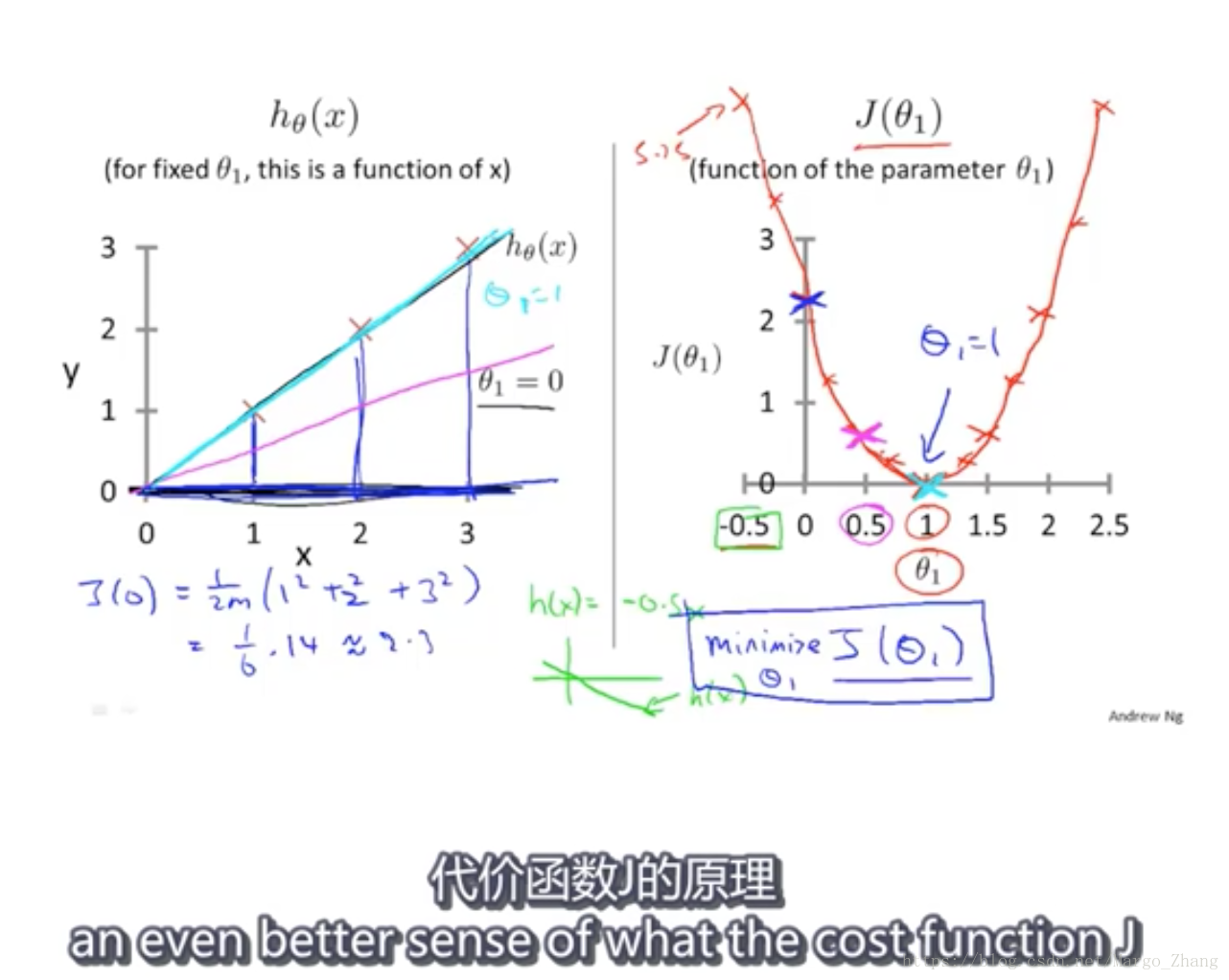
找到使J最小的theta
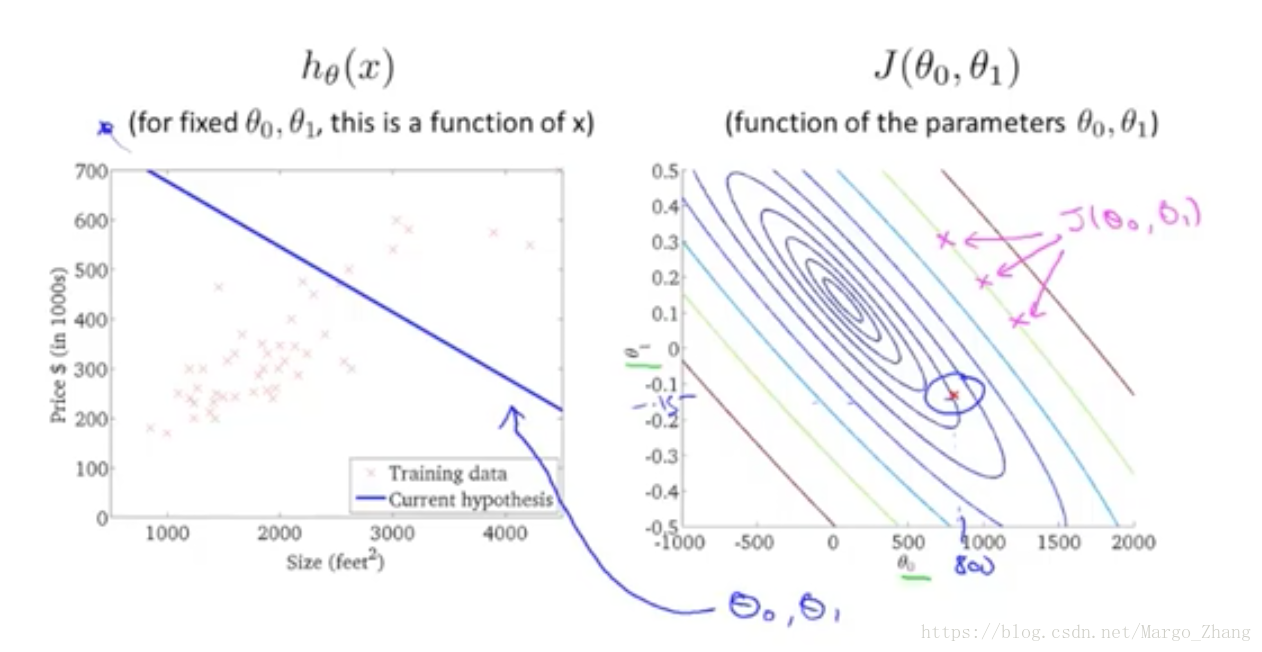
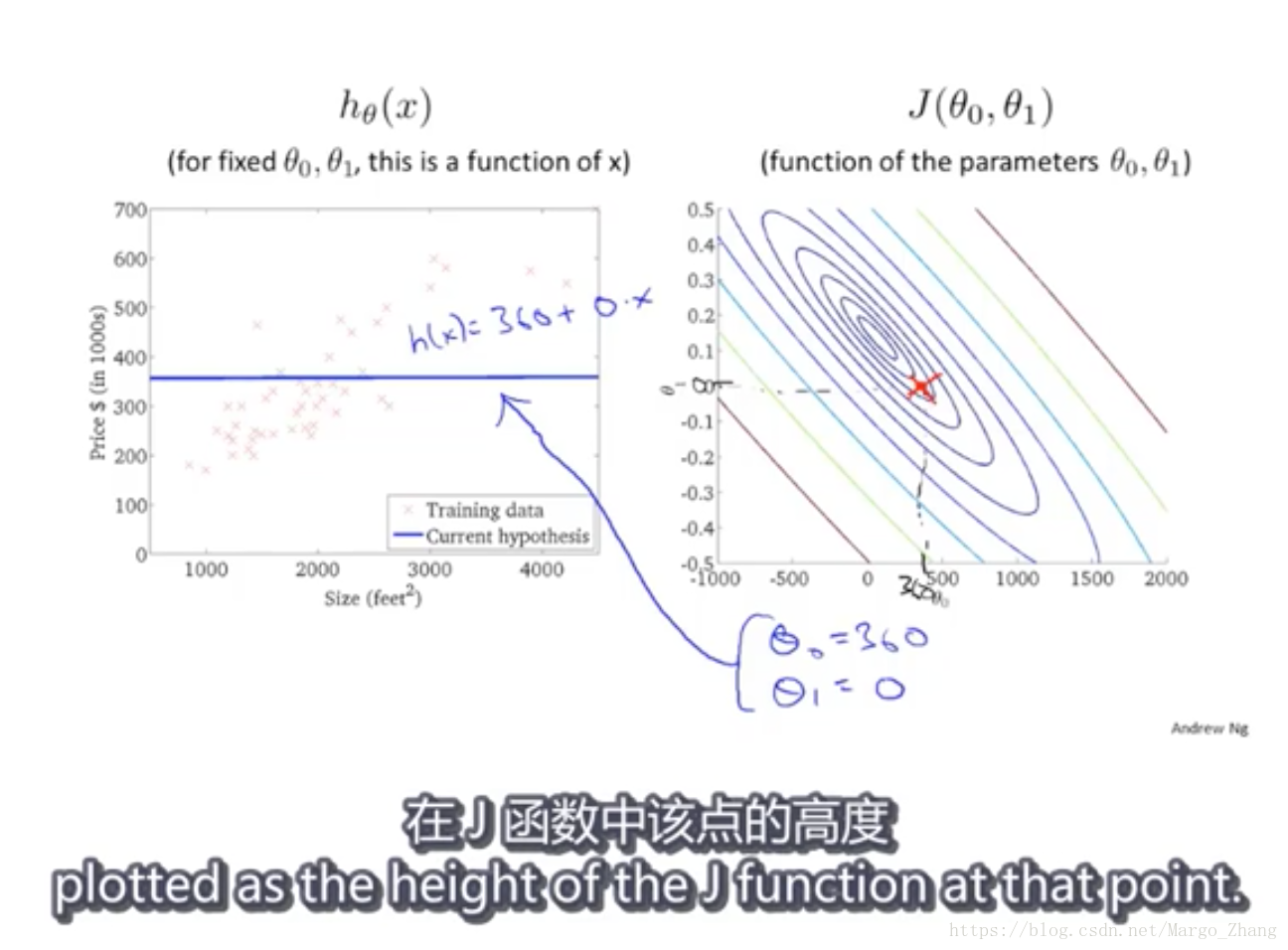
4,代价函数(二)

采用等高线来看,在有两个变量theta0和theta1作用下,h_theta的值
5,梯度下降gradient descent


6,梯度下降知识点gradient descent intuition
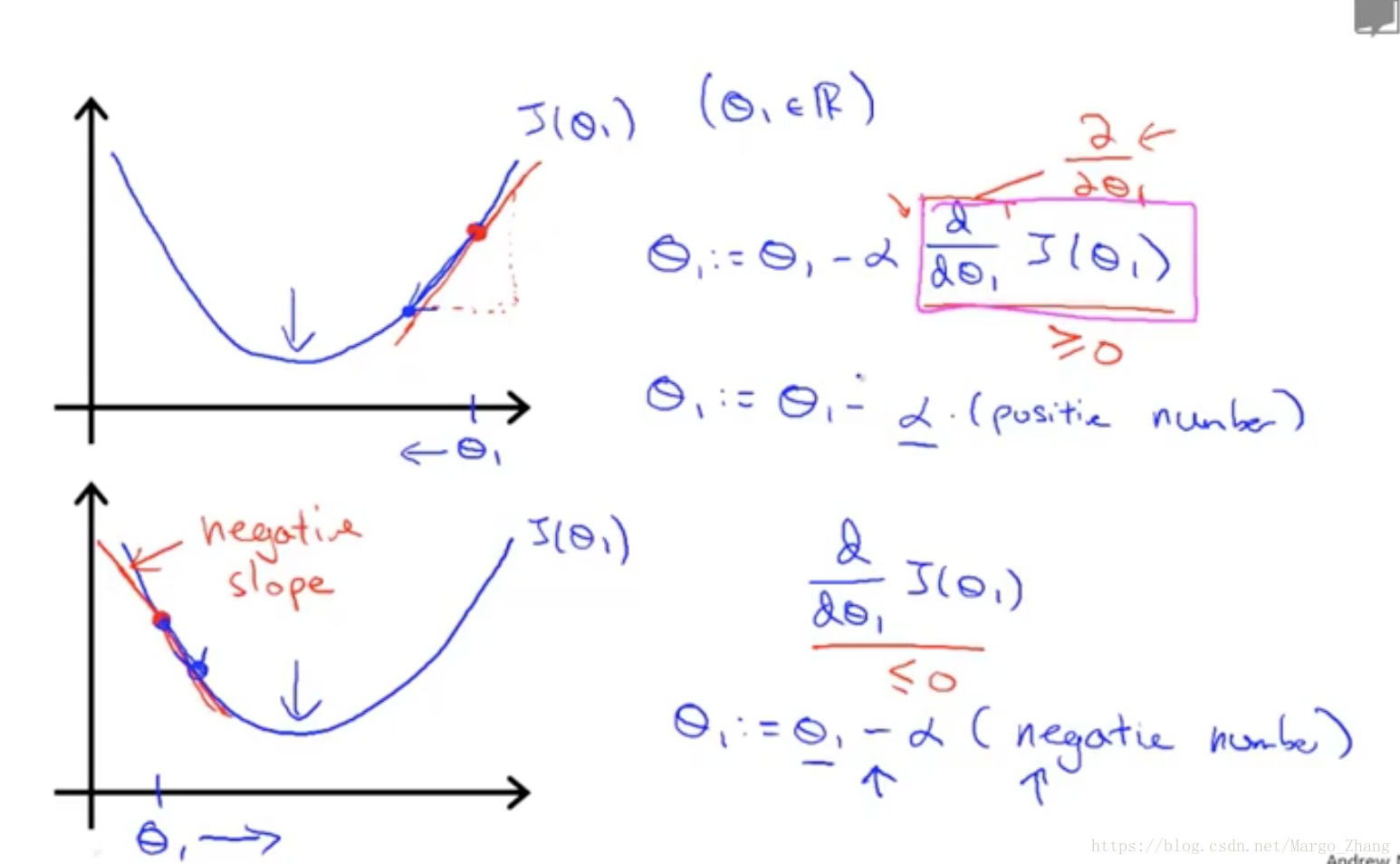
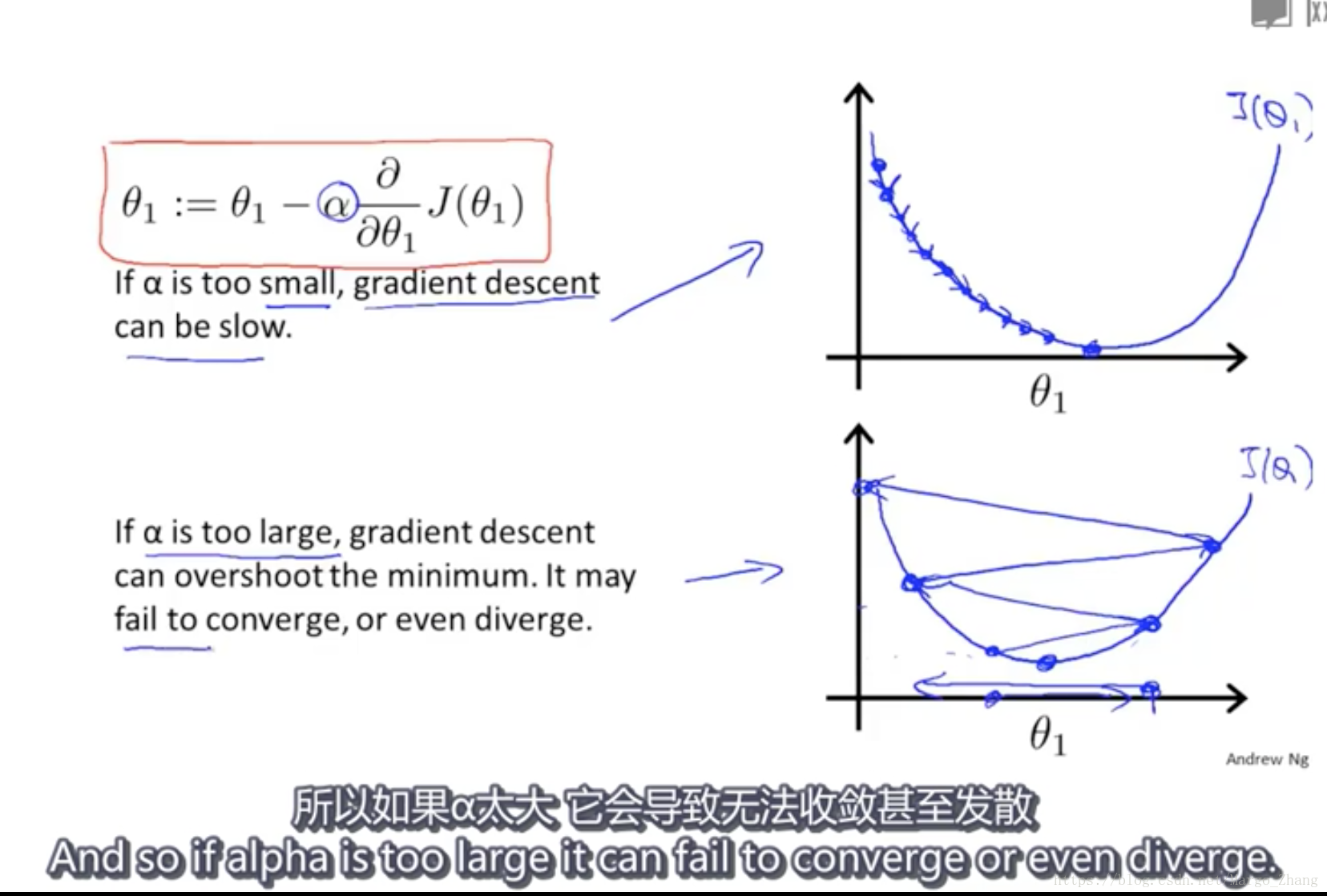

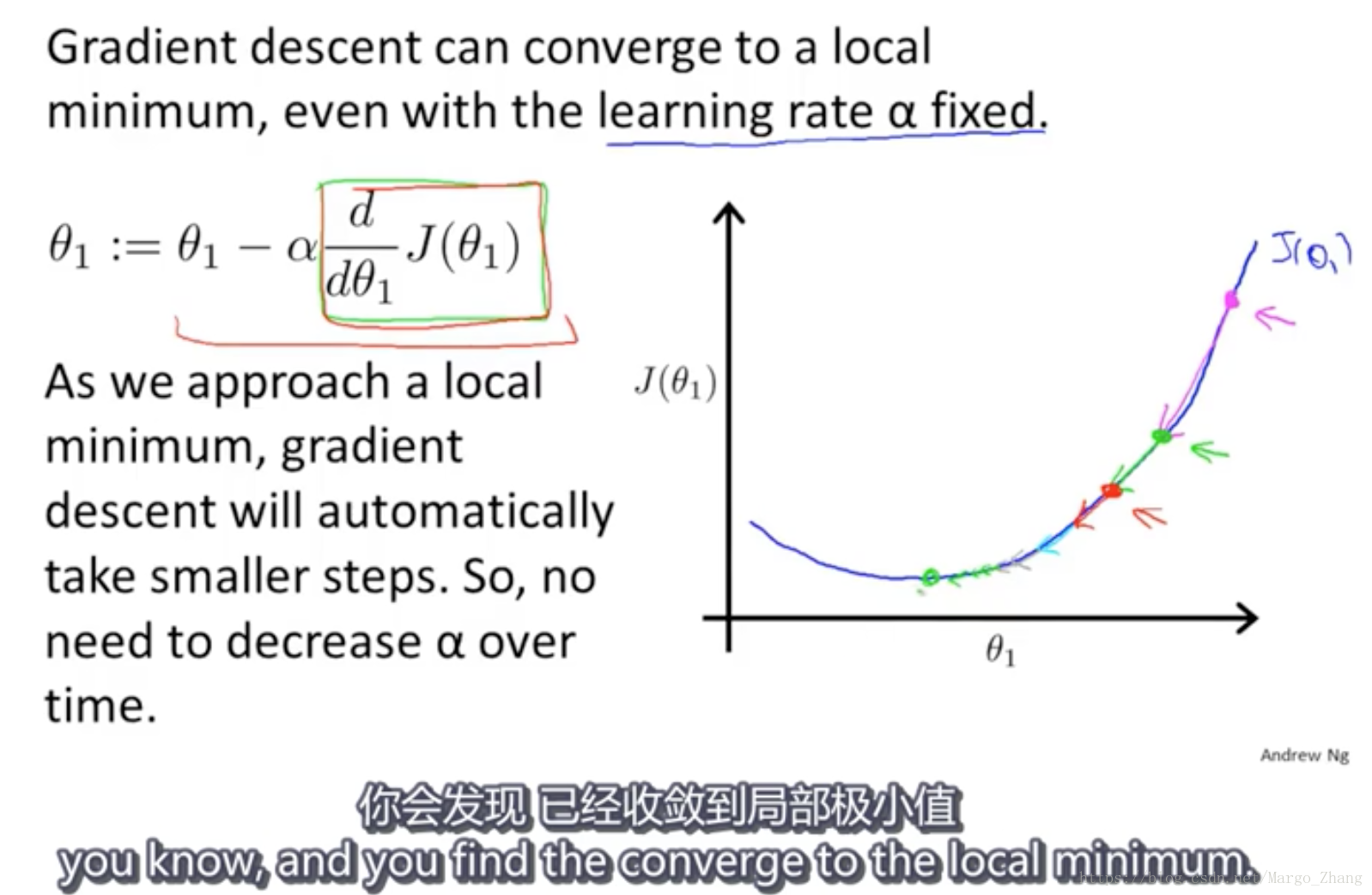
随着theta_1接近最优点,他的导数值不断趋近于0,越来越小。
从而就算不调整alpha,梯度下降也会自动采用较小的步幅。
7,线性回归的梯度下降(Gradient descent for linear regression)

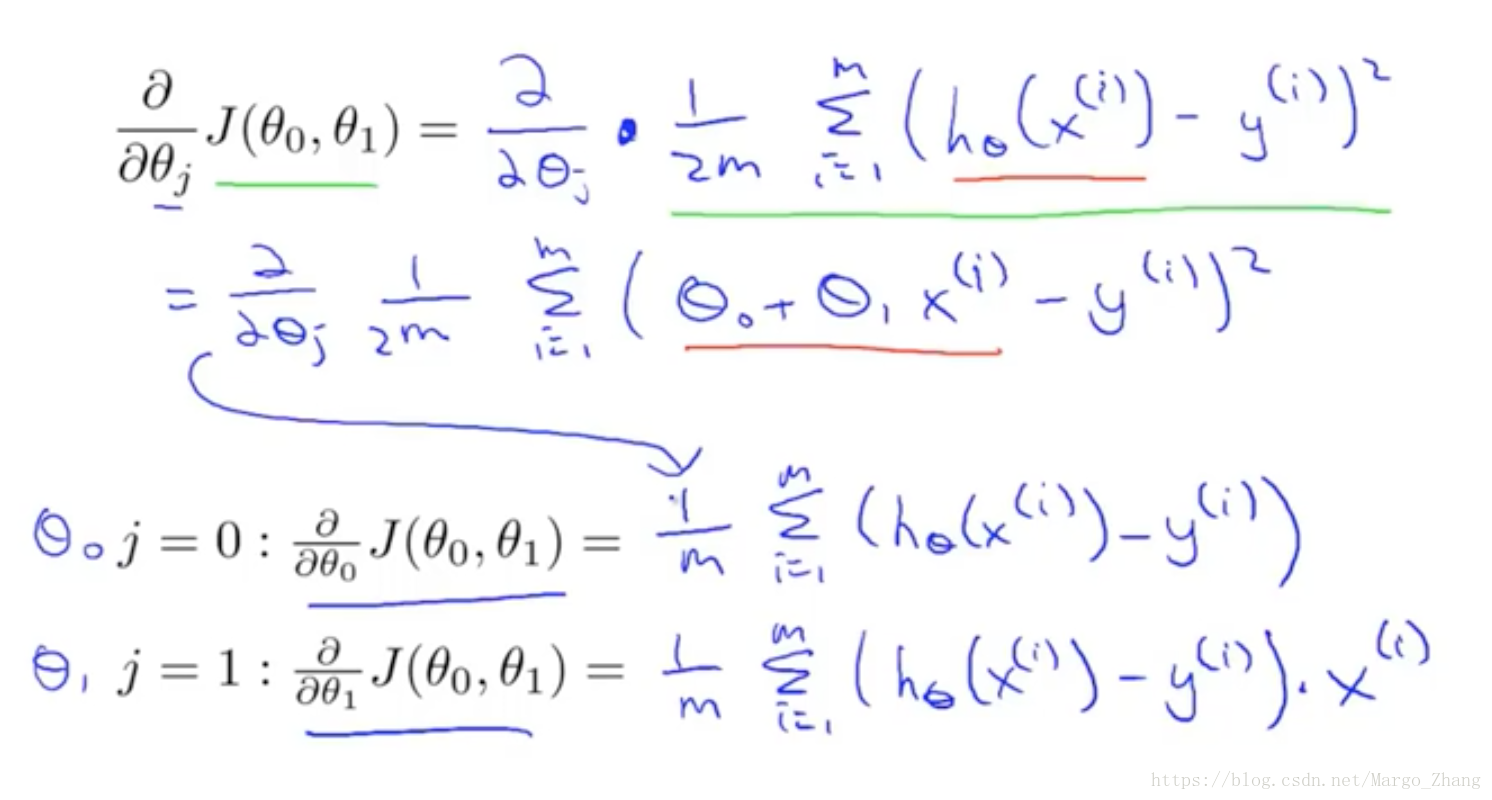

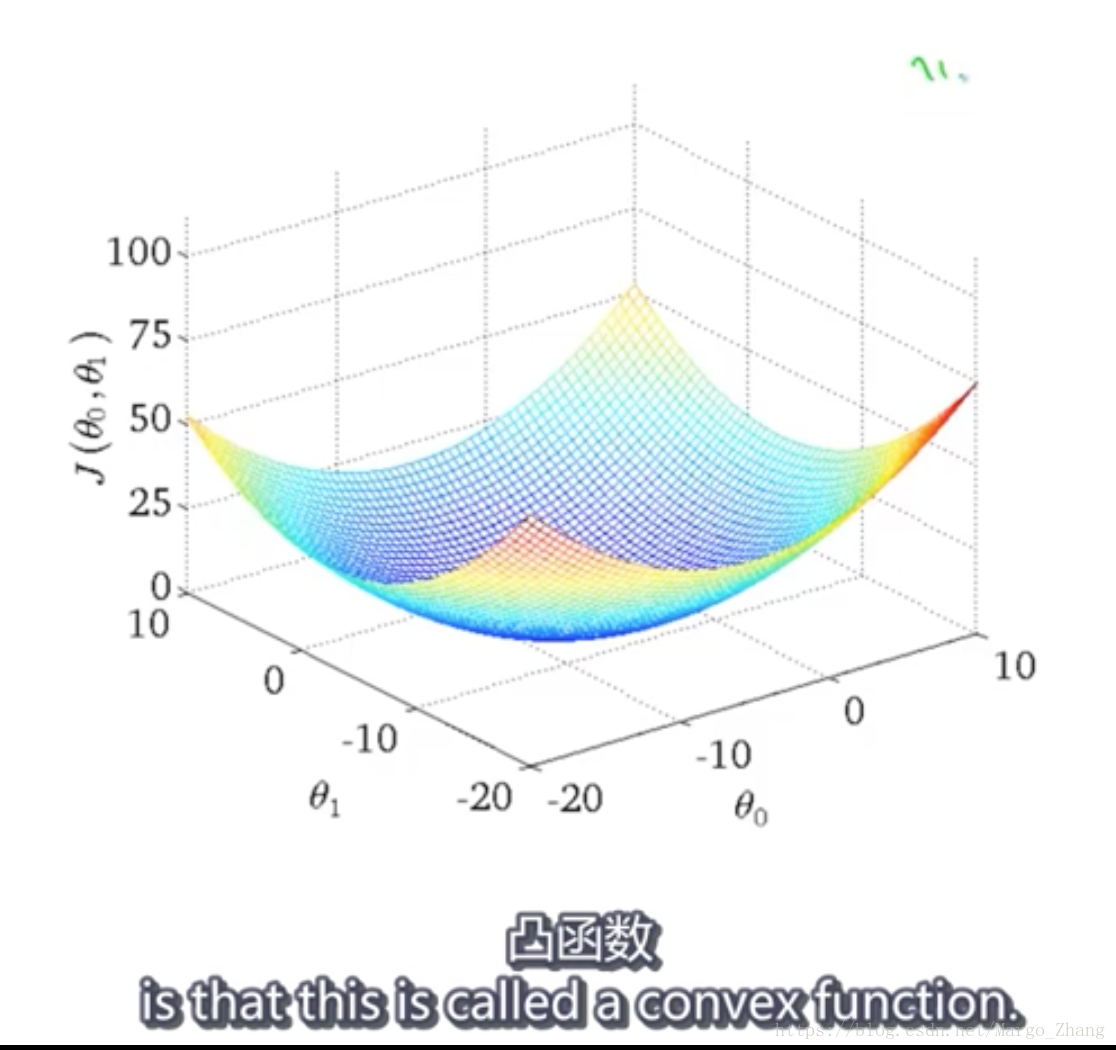
线性回归的梯度下降,代价函数相对于theta_0,theta_1是凸函数。
只有一个全局最优解,没有局部最优解,所以总是能得到最优解。
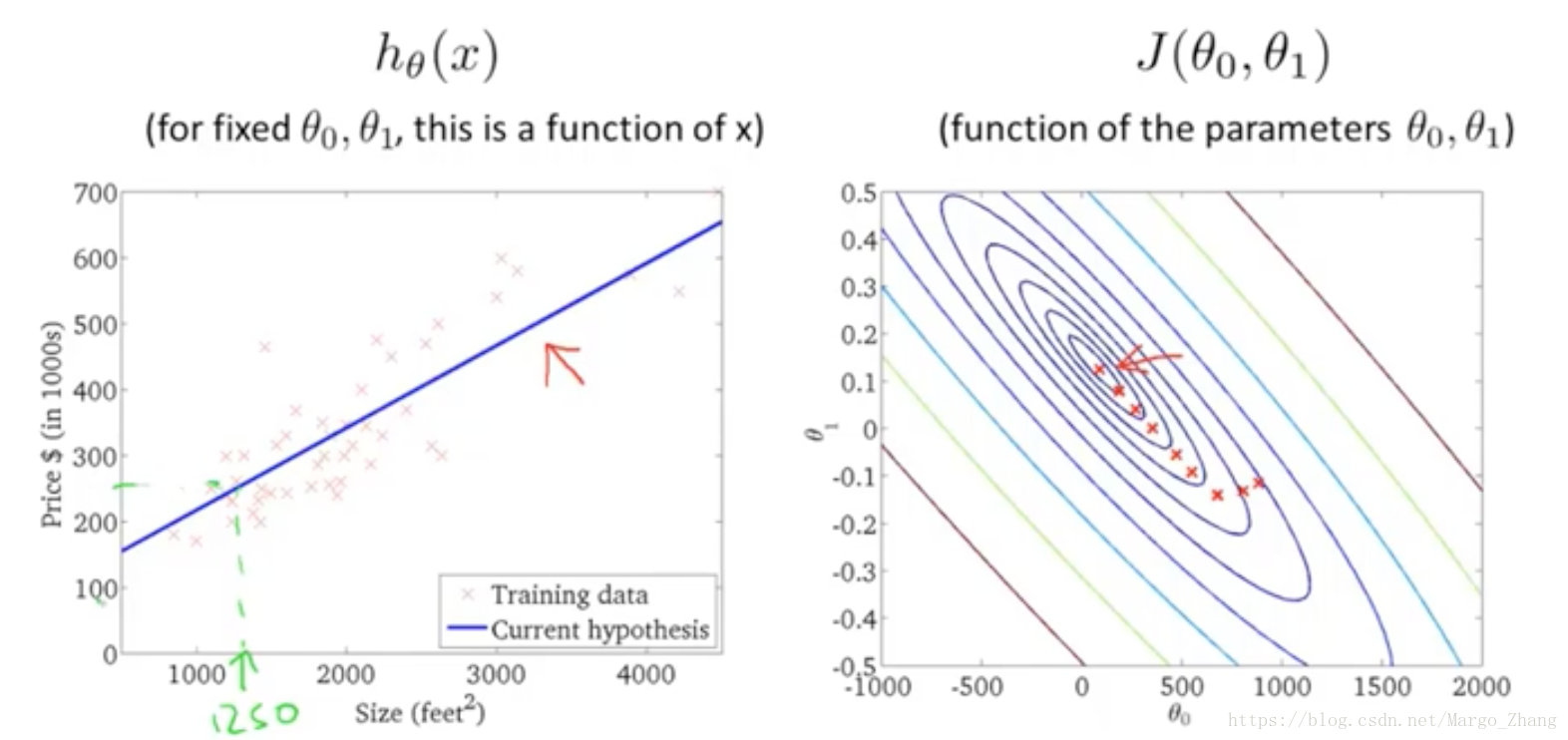

batch梯度下降法,需要计算所有的训练样本。也有不需要用到全部训练集的,后面会讲到。