1. 概览
- ConcurrentHashMap 和HashTable类很相似,但 ConcurrentHashMap 能够提供比 HashTable 更好的并发性能。在你从中读取对象的时候 ConcurrentHashMap 并不会把整个 Map 锁住。此外,在你向其中写入对象的时候,ConcurrentHashMap 也不会锁住整个 Map。它的内部只是把 Map 中正在被写入的部分进行锁定。
- 另外一个不同点是,在被遍历的时候,即使是 ConcurrentHashMap 被改动,它也不会抛 ConcurrentModificationException。尽管 Iterator 的设计不是为多个线程的同时使用。
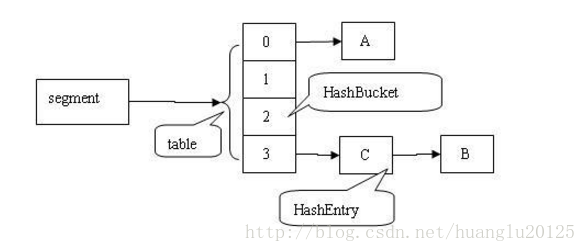
2. ConcurrentHashMap的结构
- ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。
- HashEntry 用来封装映射表的键 值对;
- Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶;每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
1. HashEntry类
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}- 与HashMap源码中的Entry类似,HashEntry是基本的存储单元,用来封装散列映射表中的键值对。在 HashEntry类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。(HashMap的Entry没有这样做)
- 具体用法和HashMap的相同,当没有哈希冲突时,作为数组的元素顺序存储;当出现哈希冲突时,采用头插法形成链表(即是形成一个桶)。
2. Segment类
- Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
- table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
- Segment的源码如下
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 在本 segment 范围内,包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型
*/
transient volatile int count;
/**
* table 被更新的次数
*/
transient int modCount;
/**
* 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列
*/
transient int threshold;
/**
* table 是由 HashEntry 对象组成的数组
* 如果散列时发生碰撞,碰撞的 HashEntry 对象就以链表的形式链接成一个链表
* table 数组的数组成员代表散列映射表的一个桶
* 每个 table 守护整个 ConcurrentHashMap 包含桶总数的一部分
* 如果并发级别为 16,table 则守护 ConcurrentHashMap 包含的桶总数的 1/16
*/
transient volatile HashEntry<K,V>[] table;
/**
* 装载因子
*/
final float loadFactor;
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K,V>newArray(initialCapacity));
}
/**
* 设置 table 引用到这个新生成的 HashEntry 数组
* 只能在持有锁或构造函数中调用本方法
*/
void setTable(HashEntry<K,V>[] newTable) {
// 计算临界阀值为新数组的长度与装载因子的乘积
threshold = (int)(newTable.length * loadFactor);
table = newTable;
}
/**
* 根据 key 的散列值,找到 table 中对应的那个桶(table 数组的某个数组成员)
*/
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
// 把散列值与 table 数组长度减 1 的值相“与”,
// 得到散列值对应的 table 数组的下标
// 然后返回 table 数组中此下标对应的 HashEntry 元素
return tab[hash & (tab.length - 1)];
}
}3. 整体结构
- 整体结构如下:与HashMap的结构挺相似的,只不过多了一个segment作为“锁”。
ConcurrentHashMap 的高并发性主要来自于三个方面:
- 用分离锁实现多个线程间的更深层次的共享访问。
- 用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求。
- 通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。
接下来详细介绍这三种机制:
2. 并发机制1:采用读写分离锁
- 在 ConcurrentHashMap 中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作才需要加锁。下面以 put 操作为例说明对 ConcurrentHashMap 做结构性修改的过程,源码如下
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 加锁,这里是锁定某个 Segment 对象而非整个 ConcurrentHashMap
try {
int c = count;
if (c++ > threshold) // 如果超过再散列的阈值
rehash(); // 执行再散列,table 数组的长度将扩充一倍
HashEntry<K,V>[] tab = table;
// 把散列码值与 table 数组的长度减 1 的值相“与”
// 得到该散列码对应的 table 数组的下标值
int index = hash & (tab.length - 1);
// 找到散列码对应的具体的那个桶
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { // 如果键 / 值对以经存在
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value; // 设置 value 值
}
else { // 键值对不存在
oldValue = null;
++modCount;
// 要添加新节点到链表中,所以 modCont 要加 1
// 创建新节点,并添加到链表的头部
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // 写 count 变量
}
return oldValue;
} finally {
unlock(); // 解锁
}
}- 这里的加锁操作是针对(键的 hash 值对应的)某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap。因为插入键值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。
- 此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞。同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值。
- 相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
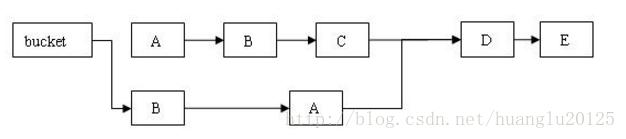
3. 并发机制2:HashEntery 对象部分属性设为final
- 在前面HashEntry的源码中,我们可以看到HashEntry 中的 key,hash,next 都声明为 final 型。这意味着,不能把节点添加到链接的中间和尾部,也不能在链接的中间和尾部删除节点。。这个特性可以保证:在访问某个节点时,这个节点之后的链接不会被改变。这个特性可以大大降低处理链表时的复杂性。
- 对于插入操作, 因为把一个节点插入链表时,采用的是头插法,所以next被设置为final不影响插入和删除。
- 对于删除节点操作,ConcurrentHashMap的remove方法会先克隆一份一样的链表,读线程可以继续读原来的链表,而删除节点的线程可以在克隆的链表中操作。
- remove前示意图:
- remove后的示意图:

4. 并发机制3:用 Volatile 变量协调读写线程间的内存可见性
- HashEntry 类的 value 域被声明为 Volatile 型,Java 的内存模型可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到。在 ConcurrentHashMap 中,不允许用 unll 作为键和值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道产生了冲突——发生了重排序现象,需要加锁后重新读入这个 value 值。这些特性互相配合,使得读线程即使在不加锁状态下,也能正确访问 ConcurrentHashMap。
- ConcurrentHashMap 中,每个 Segment 都有一个变量 count。它用来统计 Segment 中的 HashEntry 的个数。这个变量被声明为 volatile,所有不加锁读方法,在进入读方法时,首先都会去读这个 count 变量。比如下面的 get 方法:
V get(Object key, int hash) {
if(count != 0) { // 首先读 count 变量
HashEntry<K,V> e = getFirst(hash);
while(e != null) {
if(e.hash == hash && key.equals(e.key)) {
V v = e.value;
if(v != null)
return v;
// 如果读到 value 域为 null,说明发生了重排序,加锁后重新读取
return readValueUnderLock(e);
}
e = e.next;
}
}
return null;
}- 在 ConcurrentHashMap 中,所有执行写操作的方法(put, remove, clear),在对链表做结构性修改之后,在退出写方法前都会去写这个 count 变量。所有未加锁的读操作(get, contains, containsKey)在读方法中,都会首先去读取这个 count 变量。
- 这个特性和前面介绍的 HashEntry 对象的不变性相结合,使得在 ConcurrentHashMap 中,读线程在读取散列表时,基本不需要加锁就能成功获得需要的值。这两个特性相配合,不仅减少了请求同一个锁的频率(读操作一般不需要加锁就能够成功获得值),也减少了持有同一个锁的时间(只有读到 value 域的值为 null 时 , 读线程才需要加锁后重读)。
5. HashTable、HashMap、ConcurrentHashMap 的区别
- HashTable 不接受 key 为 null, HashMap 接受 key 为 null
- 哈希冲突的概率不同: 根据 Hash 值计算数组下标的算法不同, HashTable 直接使用对象的 hashCode, hashMap 做了重新计算, HashTable 的冲突几率比 HashMap 高
- hashTable 默认的数组大小为 11, hashMap 默认数组大小为 16,他们的默认 负载因子都是 0.75, HashTable 扩展为 2size+1, HashMap 扩展为 2size
- 线程安全: HashTable 是线程安全的, HashMap 则不是线程安全的 , 但是 仅仅是 Hashtable 仅仅是对每个方法进行了 synchronized 同步, 首先这样的效率 会比较低;其次它本身的同步并不能保证程序在并发操作下的正确性(虽然每个 方法都是同步的,但客户端调用可能在一个操作中调用多个方法,就不能保证操 作原子性了),需要高层次的并发保护。
- 并发效率问题:相比于 HashTable 和用同步包装器包装的 HashMap,ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问。同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。