1.项目说明
读取知乎数据,并对数据进行清洗,筛选计算知友的全国分布情况,和学校的分布情况,并做图表可视化
2.项目具体要求
- 数据清洗 - 去除空值
- 问题1 知友全国地域分布情况,分析出TOP20
要求:
① 按照地域统计 知友数量、知友密度(知友数量/城市常住人口),不要求创建函数
② 知友数量,知友密度,标准化处理,取值0-100,要求创建函数
③ 通过多系列柱状图,做图表可视化 - 问题2 知友全国地域分布情况,分析出TOP20
要求:
① 按照学校(教育经历字段) 统计粉丝数(‘关注者’)、关注人数(‘关注’),并筛不要求创建函数
② 通过散点图 → 横坐标为关注人数,纵坐标为粉丝数,做图表可视化选出粉丝数TOP20的学校,
③ 散点图中,标记出平均关注人数(x参考线),平均粉丝数(y参考线)
3.实现思路:
- 通过查看数据,问题数据主要有两种:a.空值,b.无效数据。对于空值object类型字段可以填充为’缺失数据’,数值型字段填充为’0’,无效数据可以在后面的数据处理中筛选出来。
- 通过知友数量和密度两个指标来分析知友的全国地域分布情况,可以筛选出’居住地’字段进行数值统计,
连接省市常住人口数据,然后计算知友密度,进行标准化之后排序,然后绘制TOP20柱状图。 知友的’粉丝数’和’关注人数’数据决定该用户的在知乎的活跃程度,结合其教育经历,通过统计可以获得知乎在各个
高校的使用热度,因此要筛选出’关注者’,’关注’,’教育经历’三个字段进行数据筛选和统计,对TOP20绘制散点图,
用散点大小表示热度。4.实现过程:
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
os.chdir('C:\\test')
zh_data = pd.read_csv('知乎数据_201701.csv',engine = 'python')
city_rk = pd.read_csv('六普常住人口数.csv',engine = 'python')
def data_clean(df):
cols = df.columns
for col in cols:
if df[col].dtype =='object':
df[col].fillna(value = '缺失数据',inplace = True )
else:
df[col].fillna(0,inplace = True)
return df
zh_data = data_clean(zh_data)说明:对于缺失数据一般处理方法是删除缺失值和填充缺失值,删除缺失值会导致其他字段的数据一并删除,
影响其他字段数据的完成性,因此在整体处理数据缺失值时,一般采用填充缺失值。在这里对数值类型字段
直接填充为0,非数值类型字段填充为’缺失数据’。
def data_clean(df):
cols = df.columns
for col in cols:
if df[col].dtype =='object':
df[col].fillna(value = '缺失数据',inplace = True )
else:
df[col].fillna(0,inplace = True)
return df
zh_data = data_clean(zh_data)说明:对于缺失数据一般处理方法是删除缺失值和填充缺失值,删除缺失值会导致其他字段的数据一并删除,
影响其他字段数据的完成性,因此在整体处理数据缺失值时,一般采用填充缺失值。在这里对数值类型字段
直接填充为0,非数值类型字段填充为’缺失数据’。
#数据处理
city_g=zh_data.groupby('居住地')[['_id']].count() # 知乎数据根据居住地分组
city_rk['city'] = city_rk['地区'].str[:-1] #地区字段去除'省','市'
data1 = pd.merge(city_g,city_rk,how ='inner',left_index = True,right_on = 'city')[['city','常住人口','_id']]
data1.columns = ['地区','常住人口','知友数量']
data1['知友密度'] = data1['知友数量']/data1['常住人口']
#统计知友密度
#创建函数:知友数量,知友密度,标准化处理,取值0-100,
def data_norm(df,*cols):
for col in cols:
mi = df[col].min()
ma = df[col].max()
df[col+'_n'] = (df[col]-mi)/(ma-mi)*100
return df
data2 = data_norm(data1,'知友数量','知友密度')
data_sl = data2[['地区','知友数量_n']].sort_values('知友数量_n',ascending = False).iloc[:20]
data_ds = data2[['地区','知友密度_n']].sort_values('知友密度_n',ascending = False).iloc[:20]
#图表可视化
fig = plt.figure(figsize = (16,9))
ax1 = fig.add_subplot(2,1,1)
ax1.bar(np.arange(len(data_sl)),data_sl['知友数量_n'],width = 0.6,facecolor = 'yellowgreen',tick_label = data_sl['地区'])
ax1.grid(linestyle = '--',axis = 'y')
ax1.set_xlim(-0.5,19.5)
ax1.set_title('知友数量TOP20')
x_sl = range(20)
y_sl = data_sl['知友数量_n']
for i,j in zip(x_sl,y_sl):
ax1.text(i-0.3,5,'%.1f' % j, color = 'black',fontsize = 12)
ax2 = fig.add_subplot(2,1,2)
ax2.bar(np.arange(len(data_ds)),data_ds['知友密度_n'],width = 0.6,facecolor = 'skyblue',tick_label = data_ds['地区'])
ax2.grid(linestyle = '--',axis = 'y')
ax2.set_xlim(-0.5,19.5)
ax2.set_title('知友密度TOP20')
x_ds = range(20)
y_ds = data_ds['知友密度_n']
for i,j in zip(x_ds,y_ds):
ax2.text(i-0.3,5,'%.1f' % j, color = 'black',fontsize = 12)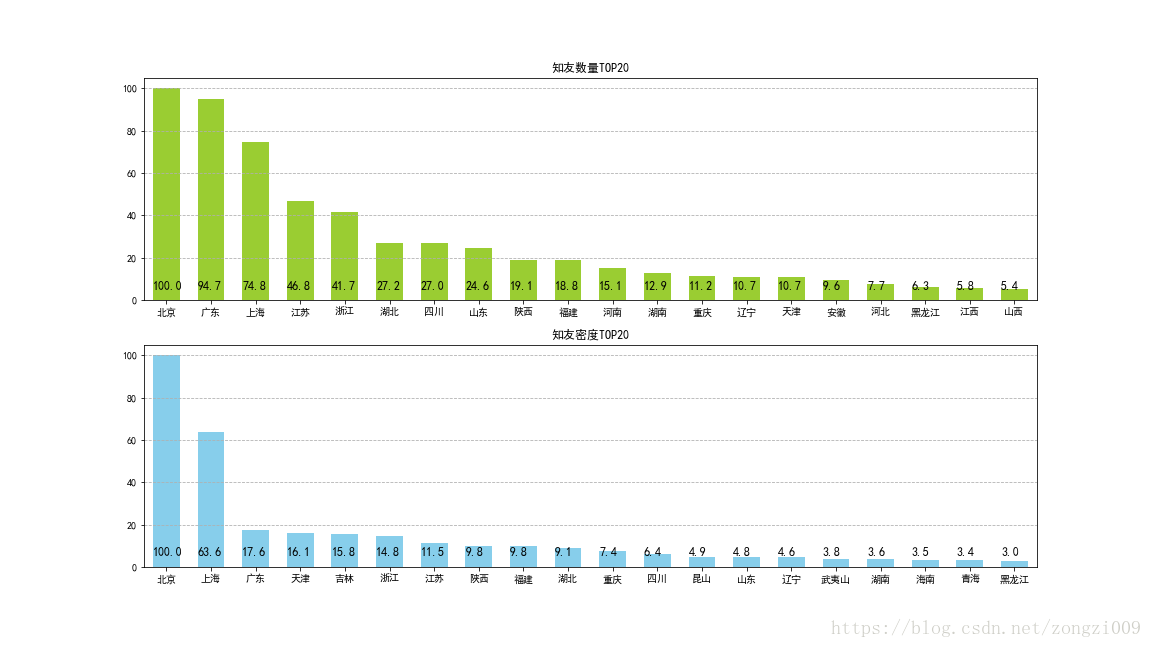
说明:分析知友的区域分布,需要根据知友的居住地进行统计,这里使用groupby()方法根据居住地分组计算id的个数,
就得到不同城市或地区的知友数量,因为主要分析top20的数据,所以需要筛选掉top20中的无效的数据。
再连接城市常住人口数据,就可以计算知友数量密度,这里的知友数量数据较大,而占比数据又相对很小,为便于比较和可视化,
需要进行归一化,这里采用(x-min)/(max-min)进行归一化。
根据知友数量及密度柱状图,分析可知经济发达的一线城市和省份的知友数量和密度较大,主要集中在北京,上海,广东地区。
因此知乎的推广及运营重点应落在这三个地区
#根据教育经历分组获得'关注','关注者' 数据,并删除异常数据
data3 = zh_data.groupby('教育经历').sum()[['关注','关注者']].drop(['缺失数据','大学','本科'])
#获得排名前20的大学数据
data_funs = data3.sort_values('关注',ascending=False)[:20]
data_funs.rename(columns = {'关注':'关注人数','关注者':'粉丝数'},inplace = True)
#绘制散点图
fig = plt.figure(figsize = (13,10))
x = data_funs['关注人数']
y = data_funs['粉丝数']
s1 = data_funs['粉丝数']/1000
colors = range(20)
plt.scatter(x,y,s = s1,c = colors,marker = 'o',alpha = 0.5,label = '学校')
for i,j,z in zip(x,y,data_funs.index): #标注学校名称
plt.text(i+800,j,z)
#设置x,y轴label
plt.xlabel('关注人数')
plt.ylabel('粉丝数')
#设置x,y轴界限
plt.ylim([-100000,700000])
plt.xlim([15000,65000])
#绘制平均线
me1 = data_funs['关注人数'].mean()
plt.axvline(me1,linestyle = '--',color = 'g',label = '平均关注人数:%i' %me1)
me2 = data_funs['粉丝数'].mean()
plt.axhline(me2,linestyle = '--',color = 'r',label = '平均粉丝数:%i' %me2)
plt.legend(loc = 'upper left')
plt.grid(linestyle='--')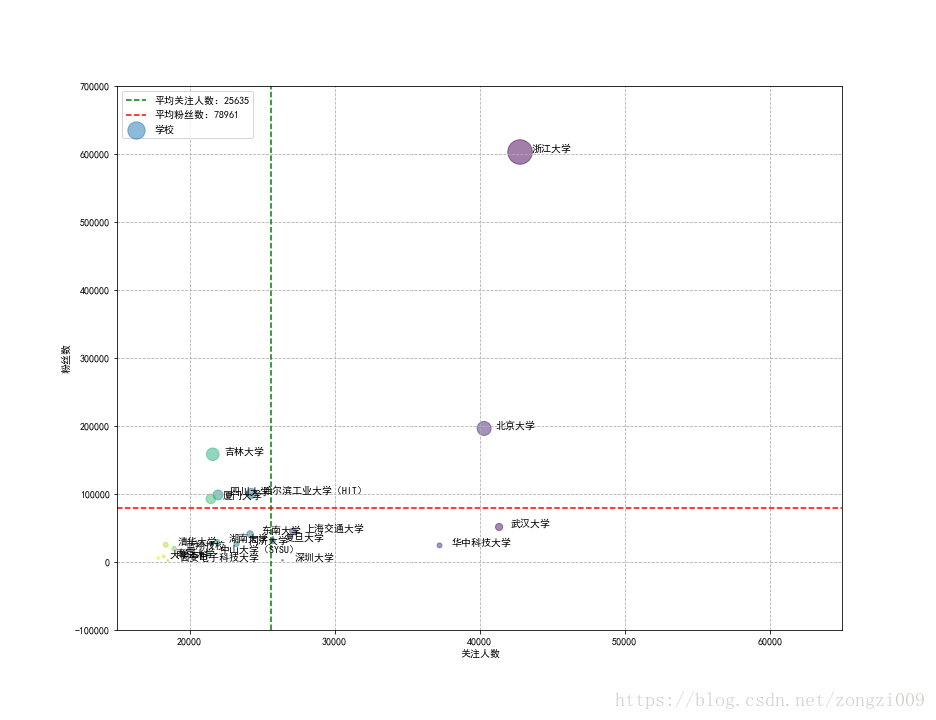
说明:知乎是一个相对严谨的网络知识问答平台,使用者通常都是有较好的教育背景的用户,因此分析用户的教育背景数据很有必要。
这里将分析各个高校的知乎使用热度,将使用两个指标:关注人数,粉丝数。
筛选计算各个高校的关注人数和粉丝数,对top20数据进行数据可视化,绘制散点图。通过散点图分析可得到以下几个结论:
a.top20学校都是全国的知名高校,说明教育背景越好的用户使用知乎热度越高。
b.大部分高校的粉丝数和关注人数都低于平均值,说明有相当部分的用户在知乎的活跃度并不高,参与度不高。
知乎的运营推广应该更偏向于高学历人群,特别是全国知名高校,创造对该人群更加有吸引力社群环境。
同时也需要深度分析用户活跃度和参与度不高的原因,采取有效的方法提供用户的使用热度。
5.总结
该项目主要考查对基本python数据分析工具的使用,主要是pandas,numpy,matplotlib三个库。
涉及到了数据分析的主要三个步骤:数据清洗,数据处理和计算,数据可视化。
通过完成该项目对基本的数据分析步骤有了较完整的了解,对三个主要分析库的运用可得到很好的检验和提高。