# Data Manipulation
import numpy as np
import pandas as pd
# Visualization
import matplotlib.pyplot as plt
import missingno
import seaborn as sns
from pandas.tools.plotting import scatter_matrix
from mpl_toolkits.mplot3d import Axes3D
# Feature Selection and Encoding
from sklearn.feature_selection import RFE, RFECV
from sklearn.svm import SVR
from sklearn.decomposition import PCA
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, label_binarize
# Machine learning
import sklearn.ensemble as ske
from sklearn import datasets, model_selection, tree, preprocessing, metrics, linear_model
from sklearn.svm import LinearSVC
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LinearRegression, LogisticRegression, Ridge, Lasso, SGDClassifier
from sklearn.tree import DecisionTreeClassifier
#import tensorflow as tf
# Grid and Random Search
import scipy.stats as st
from scipy.stats import randint as sp_randint
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
# Metrics
from sklearn.metrics import precision_recall_fscore_support, roc_curve, auc
# Managing Warnings
import warnings
warnings.filterwarnings('ignore')
# Plot the Figures Inline
%matplotlib inline
(篇幅受限,完整code戳:Python全套代码 实战 图片 数据演示 案例 )
Objective
我们的任务:预测一个人的收入能否超过五万美元
人口普查数据集: https://archive.ics.uci.edu/ml/datasets/adult
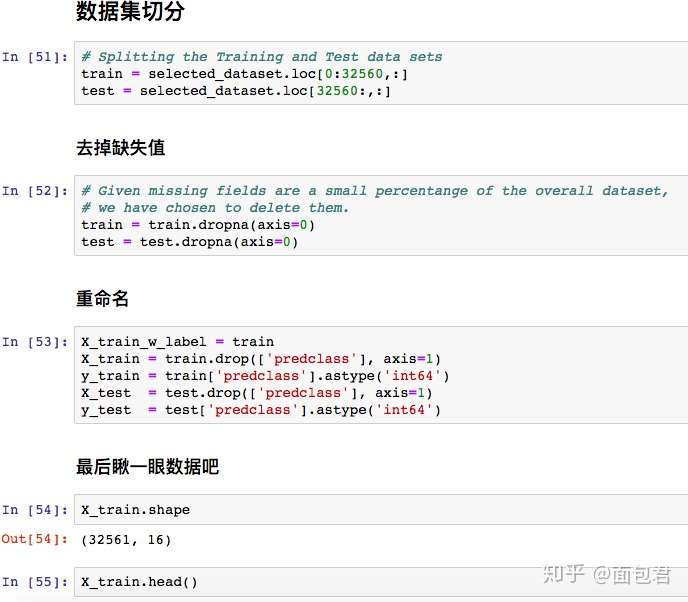
# Load Training and Test Data Sets
headers = ['age', 'workclass', 'fnlwgt',
'education', 'education-num',
'marital-status', 'occupation',
'relationship', 'race', 'sex',
'capital-gain', 'capital-loss',
'hours-per-week', 'native-country',
'predclass']
training_raw = pd.read_csv('dataset/adult.data',
header=None,
names=headers,
sep=',\s',
na_values=["?"],
engine='python')
test_raw = pd.read_csv('dataset/adult.test',
header=None,
names=headers,
sep=',\s',
na_values=["?"],
engine='python',
skiprows=1)
import pandas as pd
print (help(pd.read_csv))
# Join Datasets
dataset_raw = training_raw.append(test_raw)
dataset_raw.reset_index(inplace=True)
dataset_raw.drop('index',inplace=True,axis=1)
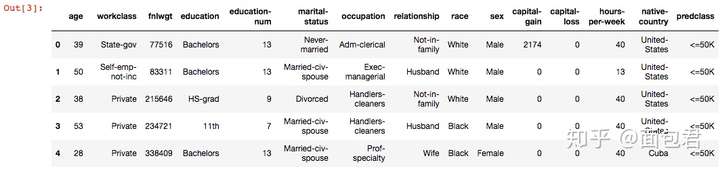
dataset_raw.head()
age 年龄 double
workclass 工作类型 string
fnlwgt 序号 string
education 教育程度 string
education_num 受教育时间 double
maritial_status 婚姻状况 string
occupation 职业 string
relationship 关系 string
race 种族 string
sex 性别 string
capital_gain 资本收益 string
capital_loss 资本损失 string
hours_per_week 每周工作小时数 double
native_country 原籍 string
income 收入 string
单特征分析
关于特征,我们可以分析单特征,也可以分析不同特征之间的关系,首先来看单特征
特征简单分为两种:类别型和数值型
- Numerical: 都是数
- Categorical: 种类或者字符串
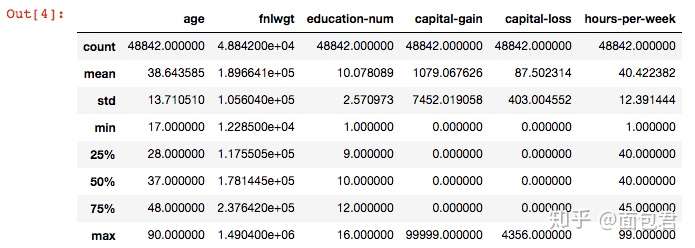
# 会展示所有数值型的特征
dataset_raw.describe()
# 展示所有种类型特征
dataset_raw.describe(include=['O'])

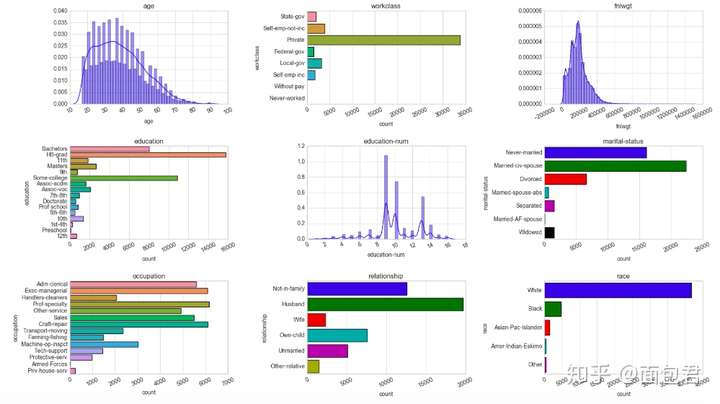
# 单特征展示
import math
def plot_distribution(dataset, cols=5, width=20, height=15, hspace=0.2, wspace=0.5):
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width,height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataset.shape[1]) / cols)
for i, column in enumerate(dataset.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if dataset.dtypes[column] == np.object:
g = sns.countplot(y=column, data=dataset)
substrings = [s.get_text()[:18] for s in g.get_yticklabels()]
g.set(yticklabels=substrings)
plt.xticks(rotation=25)
else:
#直方图,频数
g = sns.distplot(dataset[column])
plt.xticks(rotation=25)
plot_distribution(dataset_raw, cols=3, width=20, height=20, hspace=0.45, wspace=0.5)

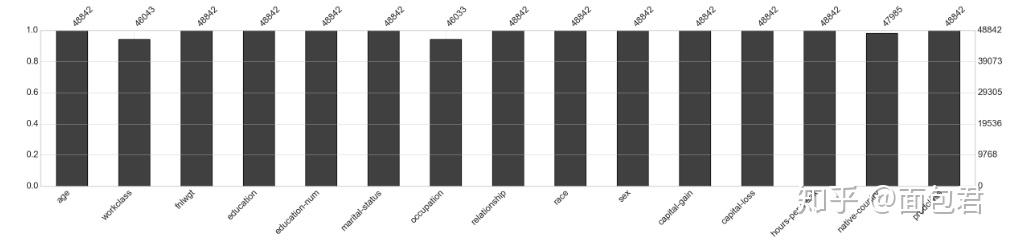
# 缺失值显示
missingno.matrix(dataset_raw, figsize = (30,5))

missingno.bar(dataset_raw, sort='ascending', figsize = (30,5))
Feature Cleaning, Engineering
清洗: 数据预处理工作:
- 缺失值: 对缺失值进行填充
- 特殊值: 一些错误导致的特殊值,例如 ±Inf, NA NaN
- 离群点: 这些点可能会对结果产生影响,先把它们找出来
- 错误值: 比如人的年龄不可能出现负数
特征工程: There are multiple techniques for feature engineering:
- 特征分解: 比如将时间数据2014-09-20T20:45:40Z 转换成天,小时等信息.
- 离散化: 我们可以选择离散一些我们所拥有的连续变量,因为一些算法会执行得更快。但是会对结果产生什么样的影响呢?需要比较离散和非离散的建模结果
- dataset_bin => 连续值被离散化的数据集
- dataset_con => 非离散化的数据集
- 特征组合: 将不同的特征组合成一个新特征
缺失值问题: 我们可以填补缺失值,在许多不同的方式::
- 额外的数据补充: 有点难弄
- 均值填充: 这样可以不改变当前数据集整体的均值
- 回归模型预测: 建立一个回归模型去得到预测值
# 创建两个新的数据集
dataset_bin = pd.DataFrame() # To contain our dataframe with our discretised continuous variables
dataset_con = pd.DataFrame() # To contain our dataframe with our continuous variables
标签转换
如果收入大于 $50K. 那么就是1 反之就是0
# Let's fix the Class Feature
dataset_raw.loc[dataset_raw['predclass'] == '>50K', 'predclass'] = 1
dataset_raw.loc[dataset_raw['predclass'] == '>50K.', 'predclass'] = 1
dataset_raw.loc[dataset_raw['predclass'] == '<=50K', 'predclass'] = 0
dataset_raw.loc[dataset_raw['predclass'] == '<=50K.', 'predclass'] = 0
dataset_bin['predclass'] = dataset_raw['predclass']
dataset_con['predclass'] = dataset_raw['predclass']
#数据不太均衡的
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(20,1))
sns.countplot(y="predclass", data=dataset_bin);

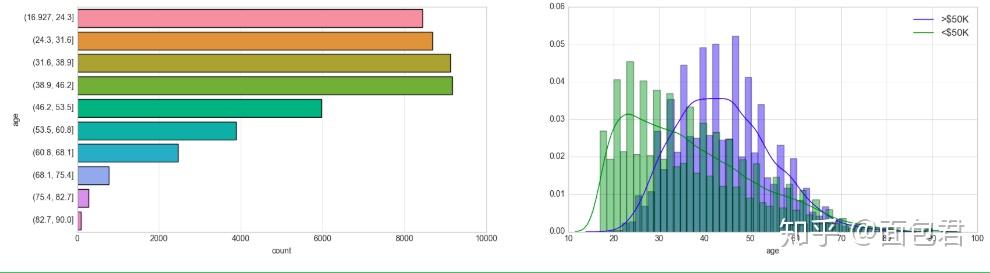
Feature: Age
dataset_bin['age'] = pd.cut(dataset_raw['age'], 10) # 将连续值进行切分
dataset_con['age'] = dataset_raw['age'] # non-discretised
#左图是切分后的结果 右图是根据不同的收入等级划分
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(20,5))
plt.subplot(1, 2, 1)
sns.countplot(y="age", data=dataset_bin);
plt.subplot(1, 2, 2)
sns.distplot(dataset_con.loc[dataset_con['predclass'] == 1]['age'], kde_kws={"label": ">$50K"});
sns.distplot(dataset_con.loc[dataset_con['predclass'] == 0]['age'], kde_kws={"label": "<$50K"});
。。。
。。。
。。。
。。(此处省略其他feature处理,完整code戳:Python全套代码 实战 图片 数据演示 案例 )
双变量分析
接下来要看特征之间的关系了
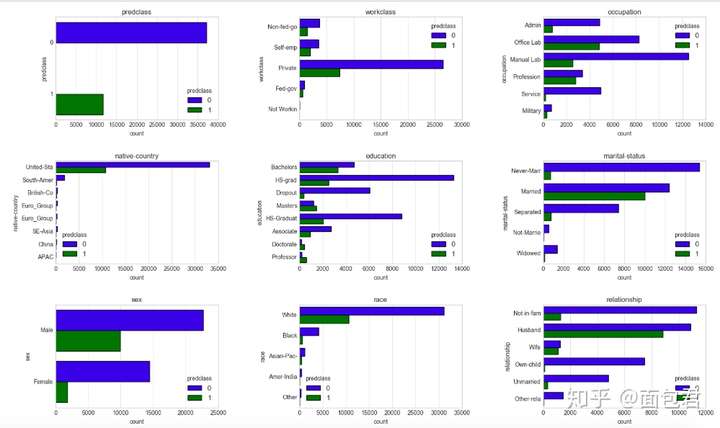
# 在不同类别属性上观察两种标签的分布情况
def plot_bivariate_bar(dataset, hue, cols=5, width=20, height=15, hspace=0.2, wspace=0.5):
dataset = dataset.select_dtypes(include=[np.object])
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width,height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataset.shape[1]) / cols)
for i, column in enumerate(dataset.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if dataset.dtypes[column] == np.object:
g = sns.countplot(y=column, hue=hue, data=dataset)
substrings = [s.get_text()[:10] for s in g.get_yticklabels()]
g.set(yticklabels=substrings)
plot_bivariate_bar(dataset_con, hue='predclass', cols=3, width=20, height=12, hspace=0.4, wspace=0.5)
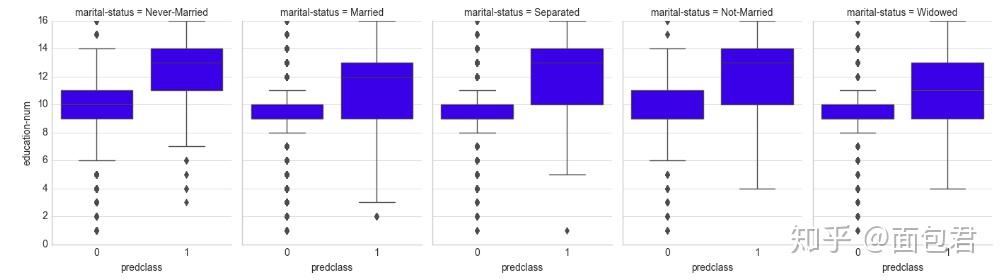
# 婚姻状况和教育对收入的影响
plt.style.use('seaborn-whitegrid')
g = sns.FacetGrid(dataset_con, col='marital-status', size=4, aspect=.7)
g = g.map(sns.boxplot, 'predclass', 'education-num')
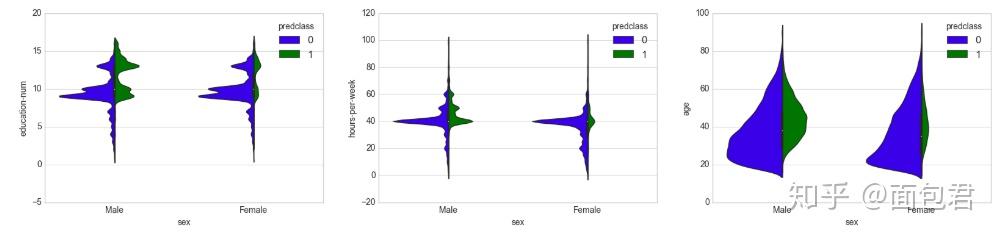
# 性别、教育对收入的影响
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(20,4))
plt.subplot(1, 3, 1)
sns.violinplot(x='sex', y='education-num', hue='predclass', data=dataset_con, split=True, scale='count');
plt.subplot(1, 3, 2)
sns.violinplot(x='sex', y='hours-per-week', hue='predclass', data=dataset_con, split=True, scale='count');
plt.subplot(1, 3, 3)
sns.violinplot(x='sex', y='age', hue='predclass', data=dataset_con, split=True, scale='count');
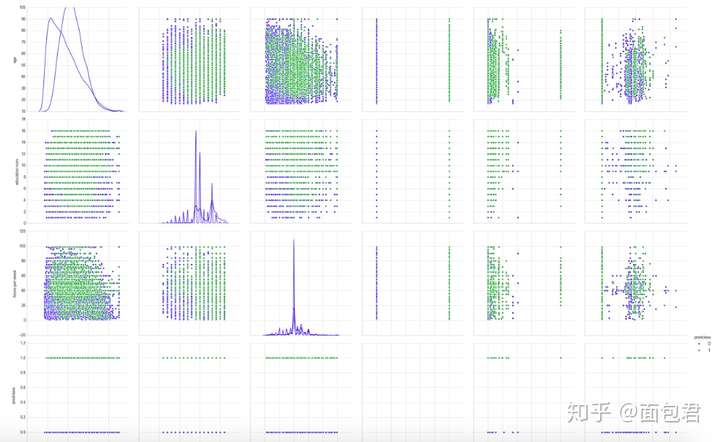
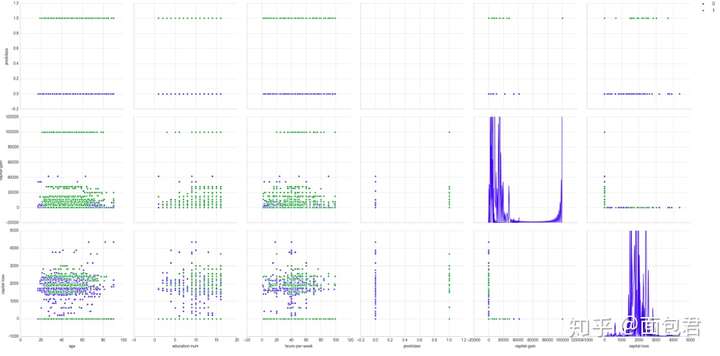
# 不同特征之间的散点图分布
sns.pairplot(dataset_con[['age','education-num','hours-per-week','predclass','capital-gain','capital-loss']],
hue="predclass",
diag_kind="kde",
size=4);
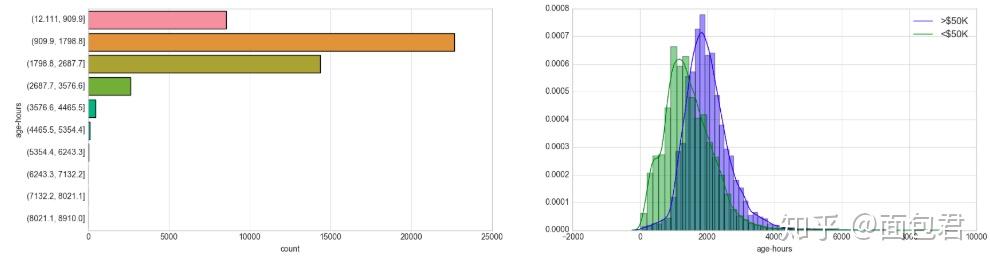
Feature Crossing: Age + Hours Per Week
开发新的变量啦
# Crossing Numerical Features
dataset_con['age-hours'] = dataset_con['age'] * dataset_con['hours-per-week']
dataset_bin['age-hours'] = pd.cut(dataset_con['age-hours'], 10)
dataset_con['age-hours'] = dataset_con['age-hours']
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(20,5))
plt.subplot(1, 2, 1)
sns.countplot(y="age-hours", data=dataset_bin);
plt.subplot(1, 2, 2)
sns.distplot(dataset_con.loc[dataset_con['predclass'] == 1]['age-hours'], kde_kws={"label": ">$50K"});
sns.distplot(dataset_con.loc[dataset_con['predclass'] == 0]['age-hours'], kde_kws={"label": "<$50K"});
。。。
。。(此处省略其他feature处理,完整code戳:Python全套代码 实战 图片 数据演示 案例 )
Feature Encoding
对特征进行编码,因为机器学习只认识数字 Additional Resources: http://pbpython.com/categorical-encoding.html
# One Hot Encodes
one_hot_cols = dataset_bin.columns.tolist()
one_hot_cols.remove('predclass')
dataset_bin_enc = pd.get_dummies(dataset_bin, columns=one_hot_cols)
dataset_bin_enc.head()
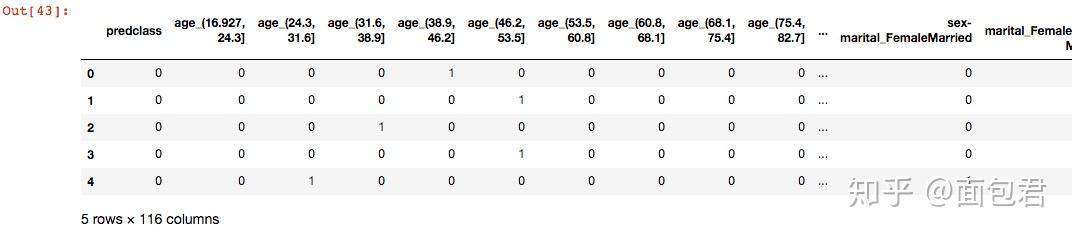
# Label Encode
dataset_con_test = dataset_con
dataset_con_test['workclass'] = dataset_con['workclass'].factorize()[0]
dataset_con_test['occupation'] = dataset_con['occupation'].factorize()[0]
dataset_con_test['native-country'] = dataset_con['native-country'].factorize()[0]
dataset_con_enc = dataset_con_test.apply(LabelEncoder().fit_transform)
dataset_con_enc.head()

特征选择
特征多并不代表都是好用的,咱们得来挑一挑,哪些比较有价值,这样才给他留下来
- 降维:
- 主成分分析 (PCA): 降维最常用的手段,需要指定基坐标系,然后变换到指定的维度
- 奇异值分解(SVD): 找出来有具有特定含义的特征
- 线性判别分析(LDA): 拿到最适合分类的特征空间
- 特征重要性/相关性:
- 筛选: 找出来哪些对结果最能产生影响的特正门
- 评估子集: 用部分特征数据进行实验
- 集成方法: 类似随机森林
特征相关性
两个随机变量共同变化的相关度量。特征应该彼此不相关,同时与我们试图预测的特性高度相关。
# 创建两个数据集的相关图s.
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(25,10))
plt.subplot(1, 2, 1)
mask = np.zeros_like(dataset_bin_enc.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(dataset_bin_enc.corr(),
vmin=-1, vmax=1,
square=True,
cmap=sns.color_palette("RdBu_r", 100),
mask=mask,
linewidths=.5);
plt.subplot(1, 2, 2)
mask = np.zeros_like(dataset_con_enc.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(dataset_con_enc.corr(),
vmin=-1, vmax=1,
square=True,
cmap=sns.color_palette("RdBu_r", 100),
mask=mask,
linewidths=.5);

特征重要性
可以基于随机森林来进行特征重要性的评估
# Using Random Forest to gain an insight on Feature Importance
clf = RandomForestClassifier()
clf.fit(dataset_con_enc.drop('predclass', axis=1), dataset_con_enc['predclass'])
plt.style.use('seaborn-whitegrid')
importance = clf.feature_importances_
importance = pd.DataFrame(importance, index=dataset_con_enc.drop('predclass', axis=1).columns, columns=["Importance"])
importance.sort_values(by='Importance', ascending=True).plot(kind='barh', figsize=(20,len(importance)/2));
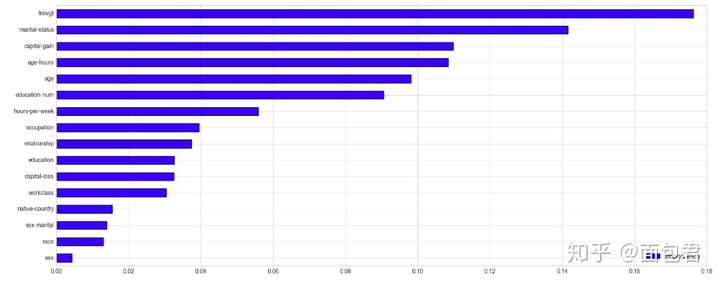
PCA
到底降不降维?没有一个固定的说法,在机器学习中没有说一个算法一个方案就一定对的,我们需要尝试
涉及参数:
- n_components:这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于等于1的整数。当然,我们也可以指定主成分的方差和所占的最小比例阈值,让PCA类自己去根据样本特征方差来决定降维到的维度数,此时n_components是一个(0,1]之间的数
- whiten :判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化,让方差都为1.对于PCA降维本身来说,一般不需要白化。如果你PCA降维后有后续的数据处理动作,可以考虑白化。默认值是False,即不进行白化。
- 除了这些输入参数外,有两个PCA类的成员值得关注。第一个是explained_variance_,它代表降维后的各主成分的方差值。方差值越大,则说明越是重要的主成分。第二个是explained_variance_ratio_,它代表降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分。
# Calculating PCA for both datasets, and graphing the Variance for each feature, per dataset
std_scale = preprocessing.StandardScaler().fit(dataset_bin_enc.drop('predclass', axis=1))
X = std_scale.transform(dataset_bin_enc.drop('predclass', axis=1))
pca1 = PCA(n_components=len(dataset_bin_enc.columns)-1)
fit1 = pca1.fit(X)
std_scale = preprocessing.StandardScaler().fit(dataset_con_enc.drop('predclass', axis=1))
X = std_scale.transform(dataset_con_enc.drop('predclass', axis=1))
pca2 = PCA(n_components=len(dataset_con_enc.columns)-2)
fit2 = pca2.fit(X)
# Graphing the variance per feature
plt.style.use('seaborn-whitegrid')
plt.figure(figsize=(25,7))
plt.subplot(1, 2, 1)
plt.xlabel('PCA Feature')
plt.ylabel('Variance')
plt.title('PCA for Discretised Dataset')
plt.bar(range(0, fit1.explained_variance_ratio_.size), fit1.explained_variance_ratio_);
plt.subplot(1, 2, 2)
plt.xlabel('PCA Feature')
plt.ylabel('Variance')
plt.title('PCA for Continuous Dataset')
plt.bar(range(0, fit2.explained_variance_ratio_.size), fit2.explained_variance_ratio_);
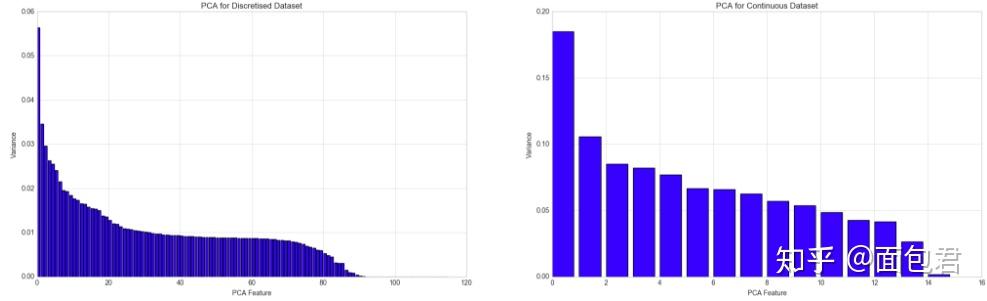
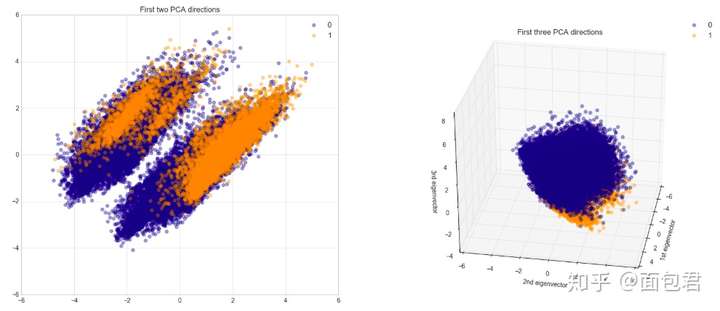
# PCA's components graphed in 2D and 3D
# Apply Scaling
std_scale = preprocessing.StandardScaler().fit(dataset_con_enc.drop('predclass', axis=1))
X = std_scale.transform(dataset_con_enc.drop('predclass', axis=1))
y = dataset_con_enc['predclass']
# Formatting
target_names = [0,1]
colors = ['navy','darkorange']
lw = 2
alpha = 0.3
# 2 Components PCA
plt.style.use('seaborn-whitegrid')
plt.figure(2, figsize=(20, 8))
plt.subplot(1, 2, 1)
pca = PCA(n_components=2)
X_r = pca.fit(X).transform(X)
for color, i, target_name in zip(colors, [0, 1], target_names):
plt.scatter(X_r[y == i, 0], X_r[y == i, 1],
color=color,
alpha=alpha,
lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('First two PCA directions');
# 3 Components PCA
ax = plt.subplot(1, 2, 2, projection='3d')
pca = PCA(n_components=3)
X_reduced = pca.fit(X).transform(X)
for color, i, target_name in zip(colors, [0, 1], target_names):
ax.scatter(X_reduced[y == i, 0], X_reduced[y == i, 1], X_reduced[y == i, 2],
color=color,
alpha=alpha,
lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
ax.set_title("First three PCA directions")
ax.set_xlabel("1st eigenvector")
ax.set_ylabel("2nd eigenvector")
ax.set_zlabel("3rd eigenvector")
# rotate the axes
ax.view_init(30, 10)
递归特征消除
- 递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
# Calculating RFE for non-discretised dataset, and graphing the Importance for each feature, per dataset
selector1 = RFECV(LogisticRegression(), step=1, cv=5, n_jobs=-1)
selector1 = selector1.fit(dataset_con_enc.drop('predclass', axis=1).values, dataset_con_enc['predclass'].values)
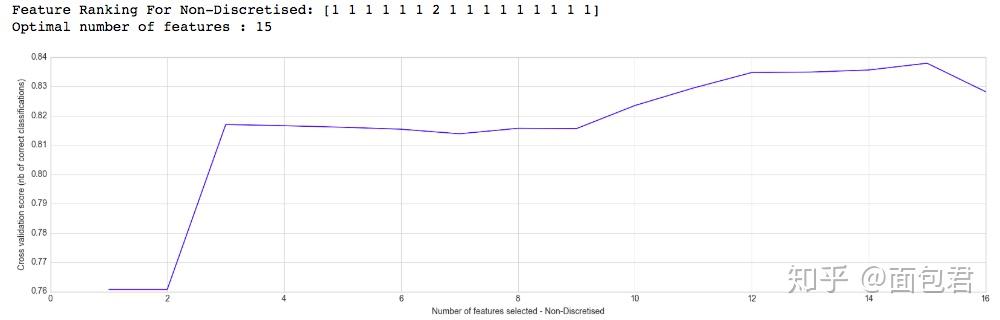
print("Feature Ranking For Non-Discretised: %s" % selector1.ranking_)
print("Optimal number of features : %d" % selector1.n_features_)
# Plot number of features VS. cross-validation scores
plt.style.use('seaborn-whitegrid')
plt.figure(figsize=(20,5))
plt.xlabel("Number of features selected - Non-Discretised")
plt.ylabel("Cross validation score (nb of correct classifications)")
plt.plot(range(1, len(selector1.grid_scores_) + 1), selector1.grid_scores_);
# Feature space could be subsetted like so:
dataset_con_enc = dataset_con_enc[dataset_con_enc.columns[np.insert(selector1.support_, 0, True)]]
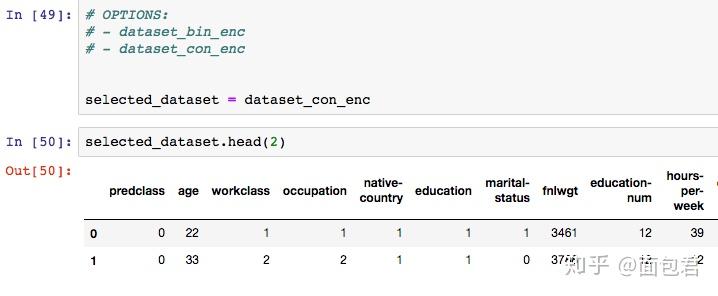
选择不同的编码数据集
分别尝试下不同机器学习算法的效果
机器学习算法
- KNN
- Logistic Regression
- Random Forest
- Naive Bayes
- Stochastic Gradient Decent
- Linear SVC
- Decision Tree
- Gradient Boosted Trees
在sklearn中有很多通用函数,可以自定义一套方案
# 在不同阈值上计算fpr
def plot_roc_curve(y_test, preds):
fpr, tpr, threshold = metrics.roc_curve(y_test, preds)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
# 返回结果
def fit_ml_algo(algo, X_train, y_train, X_test, cv):
# One Pass
model = algo.fit(X_train, y_train)
test_pred = model.predict(X_test)
if (isinstance(algo, (LogisticRegression,
KNeighborsClassifier,
GaussianNB,
DecisionTreeClassifier,
RandomForestClassifier,
GradientBoostingClassifier))):
probs = model.predict_proba(X_test)[:,1]
else:
probs = "Not Available"
acc = round(model.score(X_test, y_test) * 100, 2)
# CV
train_pred = model_selection.cross_val_predict(algo,
X_train,
y_train,
cv=cv,
n_jobs = -1)
acc_cv = round(metrics.accuracy_score(y_train, train_pred) * 100, 2)
return train_pred, test_pred, acc, acc_cv, probs

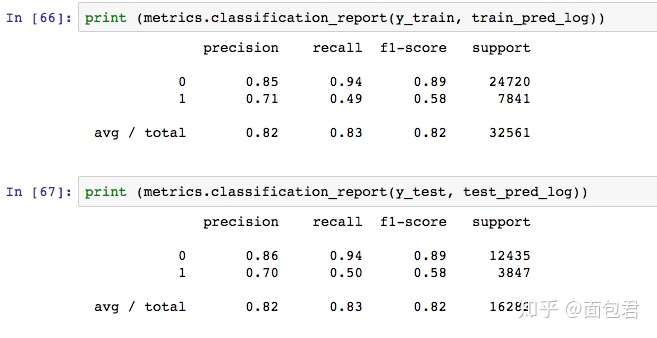
# Logistic Regression
import datetime
start_time = time.time()
train_pred_log, test_pred_log, acc_log, acc_cv_log, probs_log = fit_ml_algo(LogisticRegression(n_jobs = -1),
X_train,
y_train,
X_test,
10)
log_time = (time.time() - start_time)
print("Accuracy: %s" % acc_log)
print("Accuracy CV 10-Fold: %s" % acc_cv_log)
print("Running Time: %s" % datetime.timedelta(seconds=log_time))
Accuracy: 83.17
Accuracy CV 10-Fold: 82.79
Running Time: 0:00:07.055535
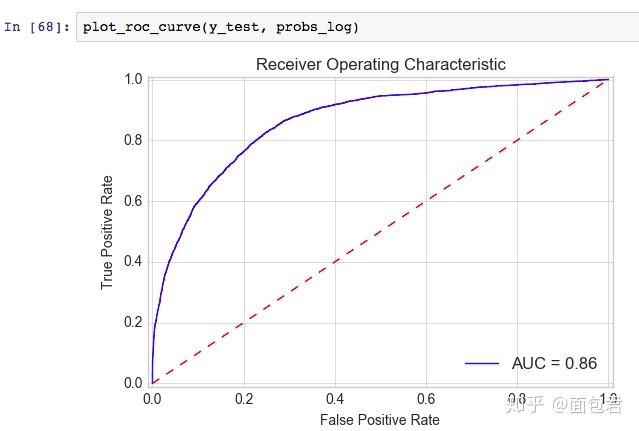
。。(此处省略其他AUC处理,完整code戳:Python全套代码 实战 图片 数据演示 案例 )
Ranking Results
Let's rank the results for all the algorithms we have used
models = pd.DataFrame({
'Model': ['KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree', 'Gradient Boosting Trees'],
'Score': [
acc_knn,
acc_log,
acc_rf,
acc_gaussian,
acc_sgd,
acc_linear_svc,
acc_dt,
acc_gbt
]})
models.sort_values(by='Score', ascending=False)
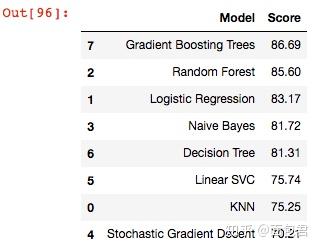
models = pd.DataFrame({
'Model': ['KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree', 'Gradient Boosting Trees'],
'Score': [
acc_cv_knn,
acc_cv_log,
acc_cv_rf,
acc_cv_gaussian,
acc_cv_sgd,
acc_cv_linear_svc,
acc_cv_dt,
acc_cv_gbt
]})
models.sort_values(by='Score', ascending=False)
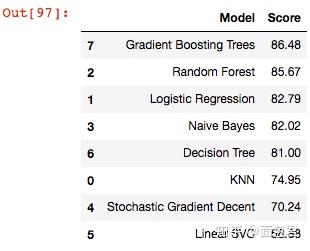
。。。
。。(此处省略其他rank,完整code戳:Python全套代码 实战 图片 数据演示 案例 )