之前的两篇文章多次提到哈希冲突,这里再解释一下。
所谓哈希冲突,就是两个key值经过哈希函数计算以后得到了相同的哈希值,而一个下标只能存放一个key,这就产生了哈希冲突,如果这个下标其中一个key先存着了,那另一个key就必须通过别的方法找到属于自己的存放位置。
产生了哈希冲突,我们就要解决。选择一个好的解决哈希冲突的方法,也是提高哈希表效率的关键。
开发定址法
为产生冲突的地址Hash(key)求得一个地址序列:
H0,H1,H2,...,Hn 1 <= n <= m - 1 其中m为表的大小
H0 = H(key) Hi = (H(key)+ di)% m i=1,2,...n
形象地一句话来说,就是根据增量di不断地往后找可以存放的下标。
增量di可以有下面三种取值:
- 线性取值,1,2,3....这样,也就是从冲突位置不断往后找下一个可以存放的下标
- 二次取值,1,4,9....这样,也就是从冲突位置不断往后找x的二次方的下标,其中x从1开始线性增大
- 随机取值,di可以去任意随机值,随机找一个。
开放定制法有很明显的缺点
- 元素不能删除
- 当哈希表中元素越来越满时,效率明显下降
再哈希法
这其实就是一次哈希出来结果相同,再用另外的哈希函数来计算,直到不再产生相同的哈希值为止。这就要求我们设计不同的哈希函数,对程序的要求就更高一点,它也和开放定制法一样要保证装载因子,和开发定址法差不多其实。
哈希桶(拉链法)
每个下标中存的都是一个链表,相同哈希值的key直接往下标中的链表后面插入就行了
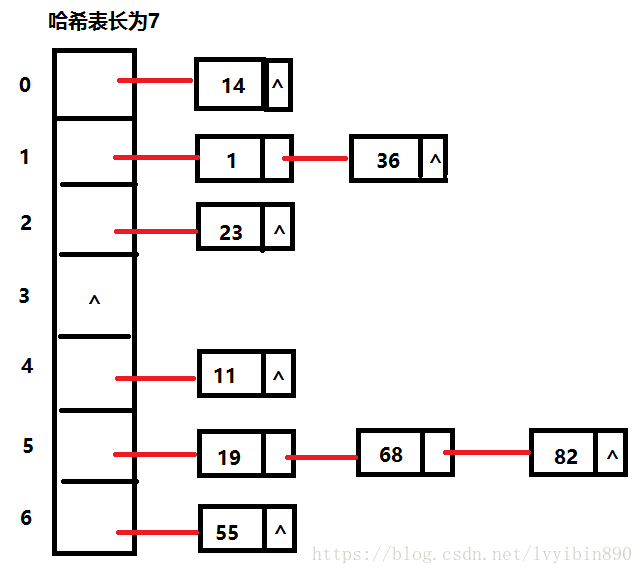
这种方法的特点是,表的大小和存储的数据数量差不多(大不了每个下标都只放一个节点,如果下标一样的都是放在同一下标的链表中,并没有占据新的下标) ,因此哈希桶的方法没有特别依赖于装载因子,哈希表块满时,它还是可以做到较好的效率,而开发定址法就需要保证装载因子。
当然,哈希桶法并不是万能的,也有它的缺点:
- 它需要稍微多一点的空间来存放元素,因为还要有一个指向下一个节点的指针。
- 每次探测也要花费较多的时间,因为它需要间接引用指针,而不是直接访问元素。
但其实,对于上面的缺点,对于现在的电脑来说并不会有太大的影响,所以这些缺点是微不足道的,所以实际使用哈希时,一般都是用哈希桶来解决冲突。
需要注意的是,哈希表也不是能让这个链表无限长的。打个比方,如果我所有的数据的哈希值都是一样,那么只会存在一个下标内,其余下标都没有用到,这就产生了一种极端情况。在这种情况下,我们要查找起来,就等于在一个链表中查找,它的查找效率是O(n),这显然违背了哈希表设计的思维。因此,在某一个链表或是几个链表的长度达到一定长度时,就需要对哈希表扩容,具体细节还是要看怎么设计了。
但是相比于开发定址法,它会发生扩容的频率就要小很多了,因为开发定址法还要保证自己的装填因子,所以它会更加频繁地扩容,所以就效率而言,拉链法还是要优于开发定址法。