引言
在寒假开始的时候就打算学习爬虫了,但是没有想到一入坑到现在还没有出坑,说多了都是泪 T_T
我准备介绍的这个库是我初学爬虫时候用到的,比较古老,所以我只用了一两次就转向了requests了
urllib.request
这个库在python2.7之中其实是被称为urllib2,但是到了python3之后这个库就取消了,变成了urllib的一个内置了,当然啦,用法还是和之前的urllib2没有什么区别。
单纯的使用urllib.request.urlopen()其实已经实现一些基本的请求了,不过如果一般要构建完整请求的时候一般要需要用上Request()函数,简单的贴一下代码。
req = urllib.request.Request(url,headers = headers)
response = urllib.request.urlopen(req)而这里的response就是服务器返回的请求了。
正则表达式
最终想想还是要讲讲正则表达式,正则表达式简单粗暴,我一开始简直迷上了正则的力量,哦,当然,后面在美丽的汤的和xpath的勾引下。。。咳咳咳
正则表达式我就不具体多讲,大家可以去翻翻一些其他人的博客或者官方文档查阅一下即可。
这里有一篇不错的他人的博客可以查阅的点击这里。
实践
单纯的讲解是非常枯燥无聊的,作为一个热好实践的实践党,每一次学习必备的就是实战,这次的实战题目就是爬取内涵吧的小说段子。
准备
url = http://www.neihanpa.com/article/
python 版本 3.6.3
paltform:win32
使用模块urllib.request、re、os
观察将要爬取的网站
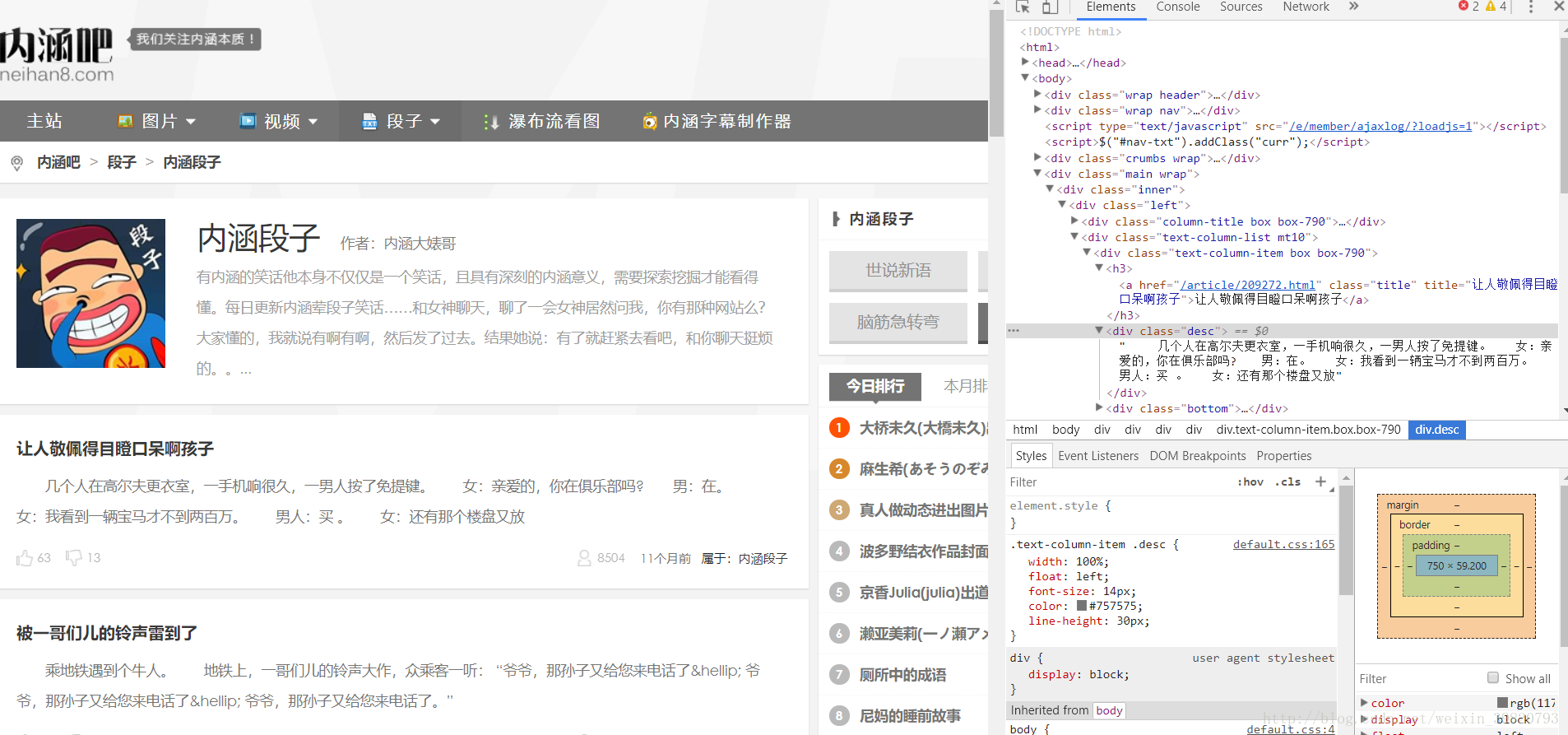
不难发现其中的对应关系。
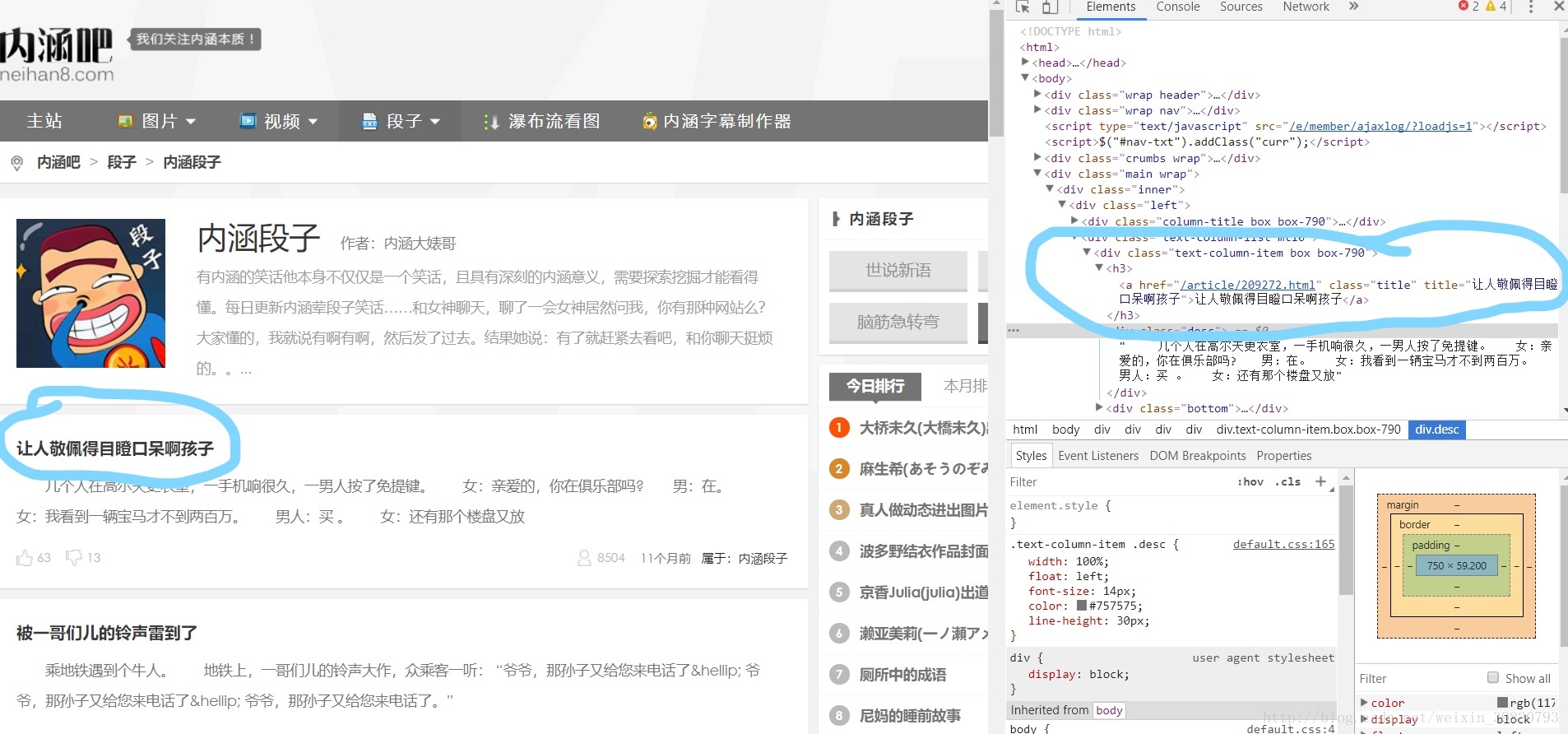
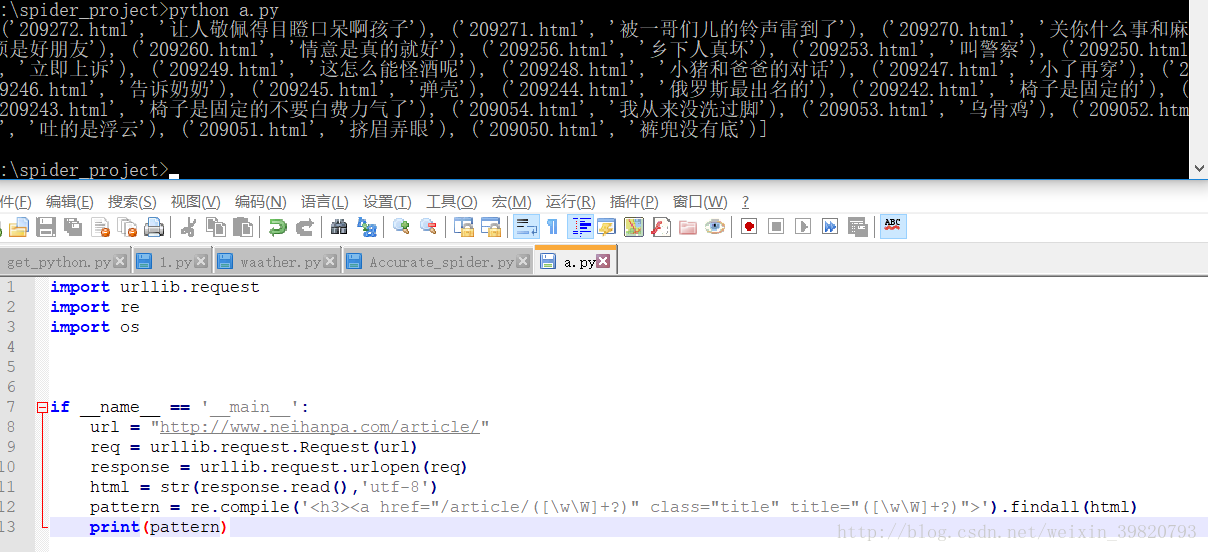
开始敲我们的代码
敲好了开头,先输出看看

看上去效果不错,但是输出了一丢哈希值是什么鬼?我们换一种编码试试。

成功的输出了中文,好我们继续接下来的工作,进行匹配。
正则匹配
经过观察这一段在不断的重复
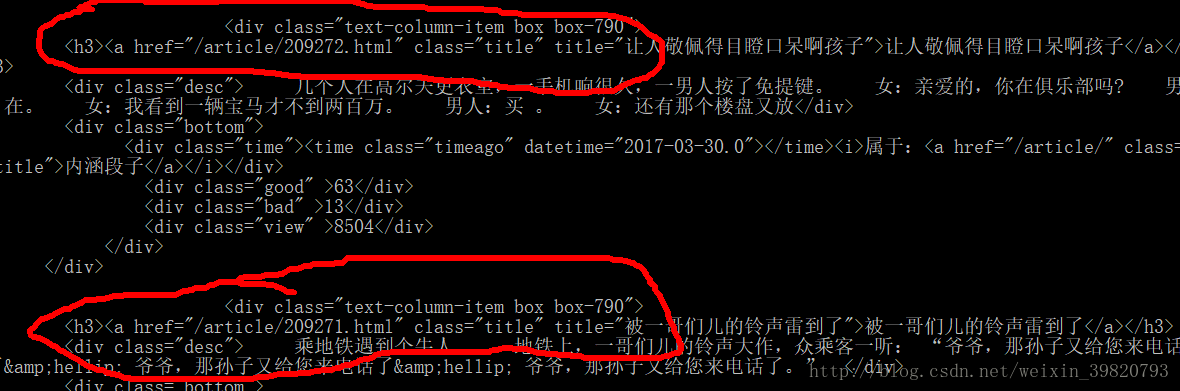
于是我把它copy到我的代码里去。

看看输出的结果,嗯看上去还不错(因为我比较懒,所以喜欢暴力的[\w\W]+?)
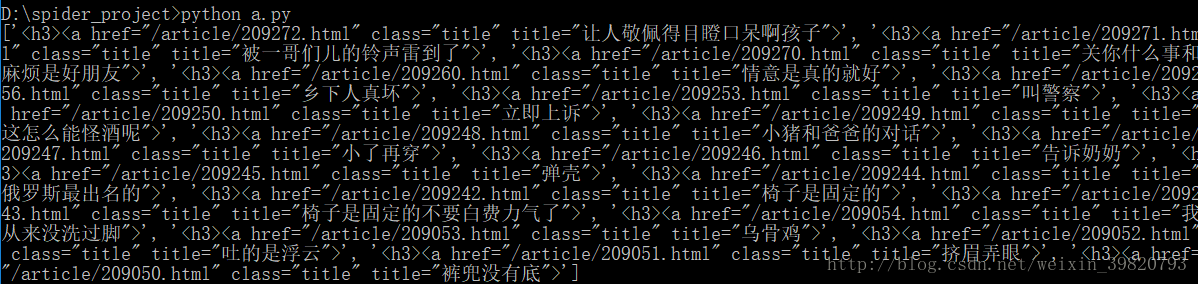
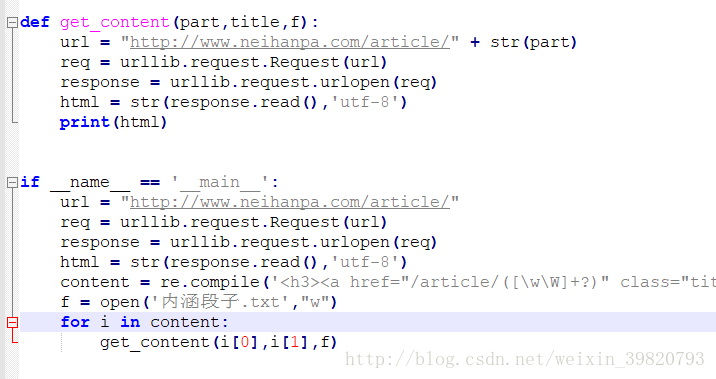
该把我们要的取出来了,只要在需要的东西打小括号就好了。
为什么要去除那个html呢?可能有人会问了,这个问题你只要点进去那一个段子,再看看它的url就明白了。
开始进行url的拼接
现在我们获得了我们想要的了,我们开始拼接我们要的url,然后进行同样的一波操作,在此我打算用一个txt文件来保存段子内容。
好,我们输出来看看。
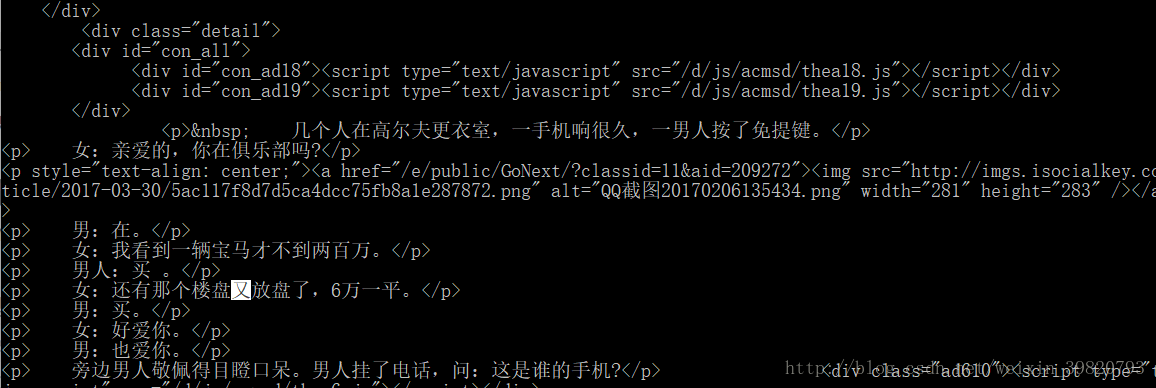
嗯,发现中间穿插了图片,但是这不重要,我们并不需要图片,然后我们再仔细观察一下规则。

发现出现了不少\r\n\t甚至还有\u3000,大家可能不知道什么是\u3000,不知道大家知不知道\x20这个是ASCII中的空白格,那么很简单\u3000就是Unicode中的空格之一,然后我们发现最后一行并不是我们想要的,于是把它删去。
再次输出:

发现已经差不多了,但是还是有些不完美。

我们使用replace()函数将其去掉。

好了,到了这里基本就是实现了
最后附加
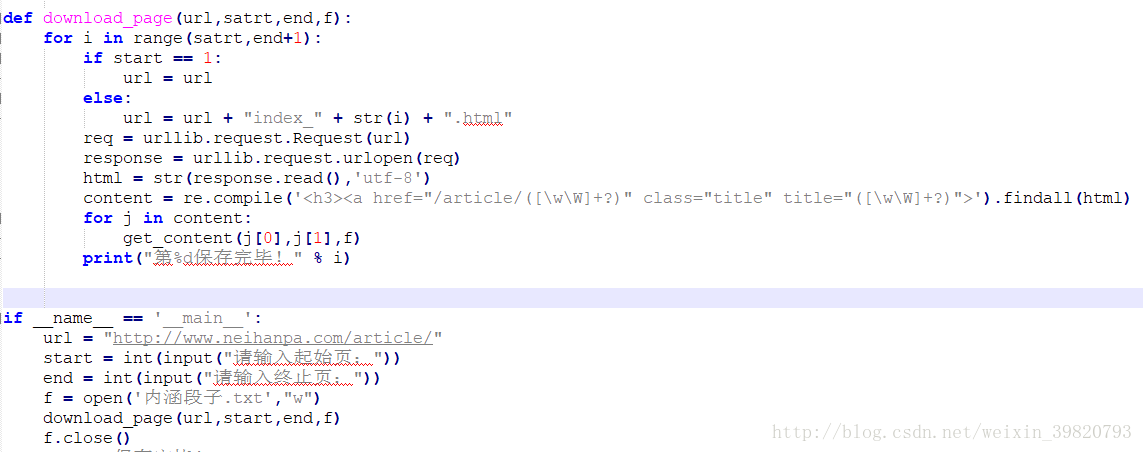
这时我又诞生想法了,我不想单单抓这一页了,我想抓多几页了(人类的欲望果然时无限的@_@)
好,这个时候我们继续观察,

到了第二页变成了索检二?再尝试一下,果然如此,于是我们再写个函数,拼接出页数的url,然后再进行简单的交互,让用户输入起始页和终止页,也可以当每一页保存完成的时候,输出第几页保存完成.
结语:
回头看看自己一开始写的代码发现一开始的自己挺菜的。。。嗯。。。是真的,也幸好我的学习方式没有错误,从最简单的正则开始学习,然后后面才学bs4之类的,不然的话估计基础不是那么好。
想要完整的代码可以点击下面哦:
https://github.com/Don98/Don98.github.io/tree/master/spider_project
对了,忽然想起,如果有人问为什么os模块我没有用到,我还导入了的话,我的回答就是,本来想用来创建文件夹的,不过最后忘了用到而已。