1.网络爬虫的应用需求
应用Requests和BeautifulSoup技术实现了从“豆瓣电影TOP250”中将电影名称、豆瓣评分和相关链接爬取下来,把爬取下来的目标数据存储到MongoDB数据库中。
2. 数据实现思路
首先引入pymogo库,然后连接服务器和数据库,接着选择数据集合进行增、删、查、改操作。从实现代码来看,把爬取到的数据存储到数据库只需要一行代码。整个网络爬虫跟MongoDB数据库相关的代码,也就下面几句:

3. 网络爬虫的代码实现
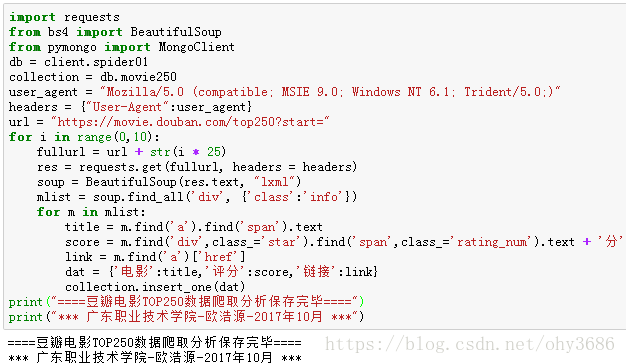
4. 数据库验证
到底爬虫获取的数据有没有存储到数据库中指定的集合中呢?我们可以打开mongo.exe的交互终端进行查看。通过查询的办法把评分为9.5分的记录找出来。

如果你觉得上面通过交互终端进行数据查询很不方便,你也可以利用Python语句编写代码,查询集合中“评分”为“9.5分”的记录。其实现代码也相当的简洁:

将上述代码放到爬虫里面,在程序将数据向数据库存储完毕之后,再读出其中“评分”为“9.5分”的记录作为验证。整个代码可以这样实现:

【小蜜蜂科教 / 广东职业技术学院 欧浩源】
